Чего только не сделают люди в порыве гнева. Кто-то готов сломать телефон или выкинуть ноутбук в окно. Способы мести тоже выбирают изысканно. Один из самых популярных — выложить в социальные сети компрометирующие фотографии и видеоролики с участием бывшей девушки. Мол, так она будет опозорена, ведь фотографии увидят знакомые и родственники. Это очень распространённое явление получило название «порноместь» (revenge porn). В современном обществе сцены убийства ни у кого не вызывают удивления, но показывать секс между влюблёнными людьми — это своеобразное табу.
Facebook обещает устранить порноместь с помощью технологий. Сейчас составляется база хэшей для фотографий, которые блокируются в социальной сети. Блокировка работает как в общей социальной сети, так и в приватных чатах Messenger (фирменное приложение для IM). Аналогичную технологию в 2015 году запустила Google.
Но в системе Facebook странно то, что для пополнения базы хэшей компания полагается… на будущих жертв порномести. Их просят заранее «зарепортить» свои компрометирующие фотографии.
Некоторое время назад на Хабре была опубликована заметка о возможностях 3D SEM-микроскопии применительно к исследованию структуры человеческого мозга в рамках европейского мегапроекта «The Human Brain Project». Под катом мы постарались максимально подробно – а это значит будет много текста – ответить на заданные вопросы, но начнём по традиции с некоторого введения. Attention! Впереди очень много текста
Компания Phinergy первой в мире сумела изготовить воздушно-алюминиевую батарею, пригодную для эксплуатации в автомобиле. 100-килограммовая батарея Al-Air содержит достаточно энергии, чтобы обеспечить 3000 км хода компактного легкового автомобиля. Phinergy провела демонстрацию технологии с Citroen C1 и упрощённой версией батареи (50 пластин по 500 г, в корпусе, наполненном водой). Машина проехала 1800 км на одном заряде, останавливаясь только для пополнения запасов воды — расходуемого электролита (видео).
Когда у исследователей имеется недостаток реальных данных, зачастую они прибегают к аугментации данных, как способу расширить имеющийся датасет. Идея состоит в том, чтобы модифицировать имеющийся тренировочный датасет таким образом, чтобы оставить семантические свойства нетронутыми. Не такая уж тривиальная задача, если речь идет о человеческих лицах.
В мае 2018 года Европа переключится на обновлённые правила обработки персональных данных, установленные Общим регламентом по защите данных (Регламент ЕС 2016/679 от 27 апреля 2016 г. или GDPR — General Data Protection Regulation). Данный регламент, имеющий прямое действие во всех 28 странах ЕС, заменит рамочную Директиву о защите персональных данных 95/46/ЕС от 24 октября 1995 года. Важным нюансом GDPR является экстерриториальный принцип действия новых европейских правил обработки персональных данных, поэтому российским компаниям следует внимательно отнестись к ним, если услуги ориентированы на европейский или международный рынок.
Новый регламент предоставляет резидентам ЕС инструменты для полного контроля над своими персональными данными. С мая 2018 года ужесточается ответственность за нарушение правил обработки персональных данных: по GDPR штрафы достигают 20 миллионов евро (около 1,5 млрд руб.) или 4% годового глобального дохода компании. В настоящей статье мы проанализировали новые правила обработки персональных данных в ЕС и сформулировали рекомендации для российских компаний по методам реагирования на GDPR.
Многие люди мечтают, что при их жизни найдут способ остановить старение. Теперь можно перестать мечтать. Реальная жизнь переплюнула научную фантастику. Исследователи смогли не только остановить, но и обратить процесс старения – вернув человеческие клетки обратно к их «молодому» состоянию. Правда, пока что только в лаборатории. Ученые рассчитывают, что скоро их открытие позволит создавать лекарства против естественной дегенерации тканей. И указывают на то, какие продукты нам нужно употреблять, чтобы достичь похожего эффекта в своём организме.
В прошлой части мы узнали что из себя представляет игра на UnrealEngine, научились строить геометрию, и расставлять акторов. В комплекте с играми на UnrealEngine и даже UnrealRuntime довольно много стандартных акторов, таких как декорации, всевозможные тригеры, оружие и прочие полезные вещи. При их грамотном использовании, можно делать разнообразные интересные уровни для игр, однако, полную свободу творчества это не даст. У игры будет стандартное начало, стандартные правила выигрыша и поражения, даже ввести лишнюю кнопку управления будет нельзя. Вот тут и пришла пора познакомится с UnrealScript. Сразу оговорюсь если вы гуру UnrealScript то скорей всего вам будет не интересно. Остальным добро пожаловать под кат.
В конце прошлого года мы писали о наших планах по разработке детского биоэлектрического протеза. Подводим промежуточные итоги и делимся новой информацией.
При создании анимации всего лишь в 64 КБ сложно использовать готовые изображения. Мы не можем хранить их традиционным способом, потому что это недостаточно эффективно, даже если применять сжатие, например JPEG. Альтернативное решение заключается в процедурной генерации, то есть в написании кода, описывающего создание изображений во время выполнения программы. Нашей реализацией такого решения стал генератор текстур — фундаментальная часть нашего тулчейна. В этом посте мы расскажем, как разрабатывали и использовали его в H – Immersion.
Прожекторы субмарины освещают детали морского дна.
Большинство пользователей текстовых редакторов не обращают особого внимания на используемый шрифт. Это же касается и программистов — обычно все работают со шрифтом по умолчанию, за редкими исключениями. Но теперь ситуация изменилась — создан шрифт Operator Mono, новый шрифт, который может облегчить программистам жизнь. «Мы разрабатывали этот шрифт с прицелом на Javascript и CSS», — говорят создатели. Авторы шрифта использовали различное начертание и размеры символов шрифта для различных операций и элементов в используемом языке программирования.
Этот шрифт без труда помогает различать «1» и «l», например, или видеть дополнительные скобки. В процессе работы шрифт выделяет отдельные элементы при помощи цветов и начертания. Надо заметить, шрифт вовсе не бесплатный, облегчение жизни программиста в данном случае стоит $200.
Какое-то время я хотел убрать комментарии из своего блога; в основном, потому что здесь вообще мало комментариев, да и не хочется возиться с лишними «тормозами» от Disqus. Посмотрев на время загрузки Disqus, я был потрясён тем, что приходится терпеть посетителям сайта по моей вине (кроме тех, кто использует блокировщики вроде Privacy Badger и uBlock Origin.
Эта статья заточена под Hugo, но код легко адаптируется для любого сайта.
Что не так с Disqus?
Вот как выглядит типичный журнал запросов с включенным Disqus.
Скоро лето, и каникулы или отпуск — не за горами. Для тех, у кого появится свободное время, Роберт Диана вместо обычного бездельничества предлагает выучить новый язык программирования.
Сейчас я работаю над senjin/gglsl — библиотекой для программирования шейдеров с помощью Groovy, о которой недавно писал.
Здесь я опишу три подхода к анализу AST (abstract syntax tree), все на примерах под-задач, вытекающих одна из другой и связанных общим контекстом: рекурсивные функции, паттерн Visitor, и паттерн-матчинг. Паттерн-матчинг реализован на Java и доступен на GitHub.
Золото досталось России, серебро разделила Россия и Италия, бронза досталась Украине. Таковы результаты европейского финала престижного соревнования InnovateFPGA под эгидой Интела. Победители поедут в Калифорнию, где встретятся с финалистами из Америки и Азии. Надеюсь, теперь не нужно будет объяснять на Хабре, почему Verilog и ПЛИС/FPGA стратегически важны, несмотря на то, что «вакансий на джаву больше».
Студенты, которые сейчас делают проекты на ПЛИСах, через несколько лет будут делать массовые микросхемы для самоуправляемых автомобилей, ускорителей нейронных сетей, дополненной реальности и других приложений, в который обычный процессор не справляется. Именно поэтому Intel потратил 16.7 миллиардов долларов на покупку Altera и вход в рынок ПЛИС. А на днях Интел купил еще и компанию eASIC для дешевой конверсии дизайнов из ПЛИС в ASIC (в eASIC есть достаточно многочисленная российская команда).
Победа российских и украинских команд в интеловском конкурсе InnovateFPGA возникла не на пустом месте, а в результате работы конкретных людей в ЛЭТИ, ИТМО, КПИ и других местах, о которых уже были статьи на Хабре. Если продолжить эти начинания и расширить преподавание ПЛИС и языков описания аппаратуры во все технические вузы от Калининграда до Якутии, от Львова до Тбилиси и Астаны — то через пару десятилетий это может изменить расстановку сил в мировой электронной промышленности примерно так же, как работы Курчатова и Королева изменили расстановку сил в мировой атомной промышленности и освоении космоса.
8 лет назад я написал на Хабре публикацию «Мой опыт восстановления зрения», в которой рассказал про свой опыт безоперационного восстановления зрения — путём закапывания капелек и различных упражнений. Тогда на Хабре ещё не было счётчика просмотров постов, поэтому те 75 тысяч просмотров — это многолетний поисковый трафик, лишний раз доказывающий очевидное — вопрос зрения беспокоит не только меня.
Сегодня я расскажу про второй опыт восстановления зрения, но на этот раз более радикальный и с каким-то вообще невероятным результатом. А именно — о лазерной коррекции по технологии ReLEx SMILE.
Изображения вносят самый большой вклад в размер веб-страниц. По мнению многих экспертов, оптимизация изображений, их сжатие – приоритет номер один в списке мероприятий по ускорению производительности сайтов. Для этого могут использоваться различные методы сжатия – с потерями или без потерь, а также конвертация в другие форматы – SVG или WebP.
Поскольку тема оптимизации изображений по-прежнему актуальна, Google недавно представил новый алгоритм сжатия изображений с открытым исходным кодом, называющийся Guetzli. В этой статье мы разберемся, что он собой представляет, как работает и сравним его производительность с другими широко использующимися алгоритмами сжатия изображений.
Привет, GeekTimes! Совершенно невероятная мощь и производительность сокрыта в слове RAMDisk — Когда-то давно были даже специальные устройства, имитирующие на железном уровне работу рамдиска — Gigabyte i-RAM, например. Однако сейчас при доступе к огромному объему оперативки строить виртуальные диски становится еще проще. Что это дает? Ответ под катом.
Не подвергая сомнению эффективность вышеприведённых методов, предлагаю Вашему вниманию сортировку, которая при определённых входных условиях легко уделывает по скорости любой другой алгоритм.
Задача сортировки — это классическая задача, которую должен знать любой программист. Именно поэтому эта статья посвящена данной теме — реализации сортировки на платформе .NET. Я хочу рассказать о том, как устроена сортировка массивов в .NET, поговорить о ее особенностях, реализации, а также провести небольшое сравнение с Java.
Итак, начнем с того, что первые версии .NET используют алгоритм быстрой сортировки по умолчанию. Поэтому небольшой экскурс в быструю сортировку:
Я долгое время думал, что написать сортировку массива слиянием так, чтобы она не использовала дополнительной памяти, но чтобы время работы оставалось равным O(N*log(N)), невозможно. Поэтому, когда karlicos поделился ссылкой на описание такого алгоритма, меня это заинтересовало. Поиск по сети показал, что про алгоритм люди знают, но никто им особо не интересуется, его считают сложным и малоэффективным. Хотя, может быть, они имеют в виду какую-то «стабильную» версию этого алгоритма, но нестабильная при этом все равно никому не нужна.
Timsort, в отличии от всяких там «пузырьков» и «вставок», штука относительно новая — изобретен был в 2002 году Тимом Петерсом (в честь него и назван). С тех пор он уже стал стандартным алгоритмом сортировки в Python, OpenJDK 7 и Android JDK 1.5. А чтобы понять почему — достаточно взглянуть на вот эту табличку из Википедии.
Среди, на первый взгляд, огромного выбора в таблице есть всего 7 адекватных алгоритмов (со сложностью O(n logn) в среднем и худшем случае), среди которых только 2 могут похвастаться стабильностью и сложностью O(n) в лучшем случае. Один из этих двух — это давно и хорошо всем известная «Сортировка с помощью двоичного дерева». А вот второй как-раз таки Timsort.
Алгоритм построен на той идее, что в реальном мире сортируемый массив данных часто содержат в себе упорядоченные (не важно, по возрастанию или по убыванию) подмассивы. Это и вправду часто так. На таких данных Timsort рвёт в клочья все остальные алгоритмы.
Предлагаю вашему вниманию новый (как я думаю) алгоритм сортировки. Пытался искать похожее, но аналогов не увидел. Дайте знать, если видели что-то подобное. Суть сортировки в том, что хэш-функция и разрешение коллизий построены таким образом, что в хэш-таблице данные оказываются уже в отсортированном виде. Остаётся только пробежаться по массиву хэш-таблицы и собрать непустые отсортированные данные.
Я с большим удовольствием прочитал топик-исследование башни Тесла. Безусловно, авторы ставят очень заманчивую цель: передача энергии без проводов, в планетарных масштабах, просто мечта энергетики. Анализ, проведенный в топике, глубок, формулы — классика радиотехники, все расчеты верны. Но после прочтения остался вопрос: если все сделать согласно авторам, то что мы получим? Какие характеристики передачи энергии будут у такой системы?
В одном будущем проекте встала задача передавать и хранить данные в формате VCard, которые содержат кириллические буквы. Так как размер передаваемой информации ограничен, необходимо было уменьшить размер данных.
Было несколько вариантов:
Использовать традиционные кодировки (для кириллицы — CP1251).
Использовать форматы сжатия Юникода. На сегодняшний день это — SCSU и BOCU-1. Детальное описание этих двух форматов привожу ниже.
Использовать универсальные алгоритмы сжатия (gzip).
В 2017-м мы сравнили около 7 500 open source-инструментов для веб-разработки, из которых выбрали 27 лучших (0,4%). Это крайне конкурентный список, в который вошли инструменты, библиотеки и проекты, опубликованные в течение 2017-го. Mybridge AI оценивает их качество на основании популярности, заинтересованности и новизне. Чтобы было понятно, у выбранных продуктов среднее количество звёзд на Github — 5260.
Open source-инструменты могут почти даром повысить вашу продуктивность. Также вы можете чему-то научиться, читая исходный код и создавая что-нибудь на основе этих проектов. Так что рекомендуем уделить время и поэкспериментировать с инструментами из нашей подборки, возможно, какие-то из них прошли мимо вас.
Parcel — маленький и быстрый бандлер, позиционируется как решение для маленьких проектов. С момента первого релиза (7 дней назад) уже собрал 8725 звездочек на гитхабе. Согласно официальной документации имеет следующие плюсы:
Быстрая сборка
Parcel использует worker process для многопоточной сборки, а так же имеет свой файловый кэш для быстрой пересборки при последующих изменениях.
Собирает все ваши ассеты
Из коробки имеется поддержка ES6, TypeScript, CoffeeScript, HTML, SCSS, Stylus, raw-файлов. Плагины не требуются.
Автоматические преобразования
Весь код автоматически проходит через Babel, PostCSS, PostHTML — подхватываются при необходимости из node_modules.
️ Разделение кода без лишней конфигурации
Используя динамический import(), Parcel разделяет бандл для возможности быстрой начальной загрузки точки входа в приложение
Горячая перезагрузка
Типичный хот-релоад без конфигурации — сохраняете изменения и они автоматически применяются в браузере.
Дружелюбный вывод ошибок
При ошибке подсвечивается кусок кода, в котором она произошла.
Web Audio API для меня является одной из тех новинок, которыми сейчас напичканы браузеры и с которой хотелось подружиться поближе и хоть как-то проникнуться тем, что же можно с помощью этого натворить. Что бы проникнуться, я решил написать простенький визуализатор аудио.
Но прежде чем начать разбираться непосредственно с Audio API, нам необходимо набросать заготовку нашего визуализатора и делать мы будем это при помощи canvas.
Двухэтапная аутентификация. Хорошая идея, но на практике только упрощающая получение доступа к вашим данным, т.к. включает в себя слишком много дополнительных участников, которые тоже могут иметь свои уязвимости.
Давно собирался написать об этом, но как то не доходили руки. На днях уже на себе ощутив всю прелесть данного метода защиты, решил что время таки пришло.
Распознавание изображений — классический пример использования нейронных сетей. Вспомним, как происходит процесс обучения сети, в чем возникают сложности и зачем в разработке использовать биологию. Подробности под катом.
Если вы пишете программы для кофемолок (холодильников, ZX Spectrum, телевизоров, встроенных систем, старых компьютеров — нужное подчеркнуть), и хотите использовать при этом красивые шрифты, не спешите сохранять буквы в растровый формат. Потому что сейчас я расскажу, как сделать растеризатор векторных шрифтов размером в пару килобайт, не уступающий по качеству FreeType 2 с выключенным хинтингом.
Статья будет интересна и тем, кто просто хочет узнать, как работают библиотеки-растеризаторы.
Продолжаем серию статей о мобильном геймдеве. В этой статье я расскажу как рендерить UTF-8 текст с помощью SDF Bitmap шрифтов, как эти шрифты создавать и как использовать эту технику для качественного рендеринга иконок.
В июле 2017 года производитель кинокамер «RED» анонсировал новый смартфон «RED HYDROGEN»
Сама новость про RED и смартфоны обескуражила многих обывателей: «Серьезно? Они же камеры делают — какие еще смартфоны...»
Но ещё более неожиданным стало заявление о том, что смартфон будет поддерживать голограммы!
Многие решили, что ребята сошли с ума, либо это какой то обман века, странный пиар или… Неужели это возможно? Может не за горами и световой меч?
— Да, это возможно.
Но не так как нам рисует голливуд — проекцию принцессы Леи мы не увидим. Скорей всего вы просто не знаете что такое голограмма потому что смотрели много фантастики вместо изучения физики. Как раз для таких людей и написана эта статья — просто о сложном.
В последнее время российские законодатели принимают законы, которые плохо проработаны с точки зрения соблюдения прав человека. Самым громким из таких законодательных актов стал пакет «антитеррористических» законопроектов (ФЗ №374, ФЗ №375), принятый в июле 2016 года, который в народе прозвали “закон Яровой”. В ряд законов были внесены резонансные нормы, способные серьезно сказаться на жизни жителей России. В частности, были добавлены нормы о недоносительстве (несообщение о преступлении), о призывах к терроризму в соцсетях, о регулировании религиозно-миссионерской деятельности, о хранении операторами связи и организаторами распространения информации сообщений пользователей.
В настоящей статье речь пойдет о поправках, касающихся хранения данных пользователей, поскольку они угрожают праву на неприкосновенность частной жизни, не соответствуют Конституции РФ и ряду других нормативных правовых актов.
Где же была эта чертова картинка?! Я сто раз натыкался на нее, пока она была не нужна!
Привычная нам организация документов по папкам, логика которой досталась нам еще из доцифровой эпохи, и по сей день прекрасно работает, когда нужно распределить много однотипных файлов в интуитивно понятном порядке.
Но составляя, к примеру, коллекцию из разнородных, непохожих друг на друга изображений, довольно быстро приходишь к ситуации, когда для очередного файла находится пяток равно подходящих для него разделов, но ты, скрепя сердце, кладешь его в шестой (смутно предчувствуя, что через месяц будешь переворачивать все эти папки вверх дном, потому что наверняка забудешь, в какую именно его положил).
Настоящим спасением в таком случае становится переход на навигацию по тегам (лейблам, ярлыкам, темам, ключевым словам – от приложения к приложению эти термины разнятся и пересекаются). Папки и теги соотносятся примерно как оглавление и предметный указатель книги: когда информация по одной теме разбросана по разным главам, список страниц с ее упоминаниями будет более полезным, чем нудное перелистывание по оглавлению.
Да, внести десяток (а порой – и не один!) тегов для файла тяжелее, чем перетащить его из одной папочки в другую, но это сторицей окупается, когда ты с легкостью находишь сохраненный пять лет назад фотоснимок, о котором в памяти остался лишь тот красивый желтый одуванчик в углу на заднем фоне.
Какие удобства предлагают нам наиболее известные файловые менеджеры с поддержкой тегов?
IPFS не совсем ещё сделалась хорошо известной технологией, даже в Кремниевой долине многим она ещё не известна, однако вести о ней быстро расходятся из уст в уста в сообществе открытого исходного кода. И многие рады потенциальным возможностям IPFS в области улучшения передачи файлов и ускорения потокового вещания их по Интернету.
С моей личной точки зрения, однако же, IPFS в действительности гораздо важнее этих возможностей. IPFS избавляет сайты от необходимости использовать центральный сервер-первоисточник и поэтому, вероятно, это наш лучший шанс полностью переменить архитектуру Интернета прежде, чем она развалится от внутренних противоречий.
Как и почему это? Для ответа на этот вопрос придётся вдаваться в подробности.
Мне не раз приходилось видеть людей, которые пытаются избавиться от постороннего шума путём увеличения громкости наушников. Известно, что такой способ изоляции сознания от посторонних шумов вреден для волосковых клеток базилярной мембраны и может привести к повреждению слуха. Не посягаю на право каждого портить своё здоровье удобными для него методами, но всё же считаю, что конструкторская мысль помогла избавиться от шума более щадящими средствами.
Одним из подобных средств стали наушники с активным шумоподавлением (или ANC (NC)-наушники от active noise control), которые достаточно широко представлены в линейках ведущих (и не очень) производителей.
Когда вы входите в мой дом… эм… Мы с женой хотели, чтобы у нас были какие-либо произведения искусства в доме, которые были бы личными и также связанными с тем, чем мы занимаемся. И поэтому вы можете увидеть две вещи: одна из них это кривая дракона, я расскажу вам о ней больше через минуту. И другая это вот эта работа. Это строчка из “Дороги к мудрости” Пита Хайна:
Должны мы, Чтоб к мудрости Вечной добраться, Что нам Так заманчиво Брезжит, Опять И опять, И опять Ошибаться, Но реже И реже, И реже.
Это одна из моих любимых фраз. Своего рода история всей моей жизни — это совершение ошибок и попытки научиться чему-то на них. Эту фразу спроектировали в форме суперэллипса, который является одним из великих открытий Пита Хайна. Этот эллипс более полный и он использовался во многих архитектурных изделиях.
В современной литературе про поддержание здорового образа жизни и ее продление часто упоминается витамин D. В некоторых работах рекомендуется регулярно проверять его уровень и пить поддерживающие дозы, а в других работах утверждается, что непонятно есть ли от этого польза.
В нашей статье мы разберемся что такое витамин D, как он работает, на что влияет и, если вы пришли к выводу, что хотите его принимать для улучшения здоровья и продления жизни, то как это правильно делать.
При разработке регистрационного процесса мессенджера со всей очевидностью стало понятно, что телефонный номер в качестве идентификатора вообще не нужен и даже мешает. Это примерно тоже самое чтобы делать так, чтобы какое-то устройство поддерживало код Морзе, т. е. анахронизм в чистом виде.
Удивительно, но многие мессенджеры упорно продолжают регистрировать по номеру телефона — видимо получить информацию о владельце настолько важно, что они мирятся со следующими проблемами:
В 1979 году сразу две страны — Западная Германия и СССР — запустили экспериментальные образцы пассажирских маглевов. Маглев (magnetic levitation) — поезд на магнитной подушке, который при движении парит в воздухе, не касаясь никакой опоры. Немцы сделали из этого настоящую рекламу — маглев по коротенькой трассе возил посетителей Международной транспортной выставки IVA. У нас же с рекламой всегда было плохо, поэтому первый советский маглев ТП-01 ездил по заводской 36-метровой трассе:
Игры и программирование — этот симбиоз помогает новичкам освоить азы кодинга, а опытным разрабам — освежиться и отвлечься от трудных повседневных задач. Вроде бы и развлекаешься, но в то же время с пользой для мозгов. Предлагаем вам вторую часть подборки игр, в которых нужно писать код. Если пропустили первую часть, тоже рекомендуем посмотреть, там много интересного.
Говорят, обещанного три года ждут. Вот и я в комментарии к статьеvmb обещала перевести главу из книги Zero Day, но пока собиралась — всю книгу уже перевели. Так что выкладываю тут перевод статьи Марвина Л. Мински о будущем и развитии человека. За наводку на статьи Мински спасибо MagisterLudi
UPD: Владельцы лаборатории — Инвитро — теперь есть на Хабре. Занёс в их корпоративный блог. С вопросами можно обращаться к ним напрямую.
Это из новой лаборатории 3D-печати органов. Спереди внушительный микроскоп, дальше видно двух медицинских инженеров за AutoCAD – делают макет площадки для формирования тканевых сфероидов.
Тут недавно открылась лаборатория 3D-биопринтинга органов (проект Инвитро). Вокруг неё творится какая-то лютая феерия непонимания того, что именно делается. В общем, хоть я и не микробиолог, но мне стало интересно. Я пробился до разработчика — В.А. Миронова. Именно он изобрёл технологию печати органов и запатентовал это в США, участвовал в разработке уже трех модификаций биопринтеров, и именно он «главный по науке» в новой лаборатории в Москве:
В.А. Миронов (M.D., Ph.D., профессор с 20-летним опытом в микробиологии, в частности, на границе с IT) — в процессе полуторачасового объяснения мне сути технологии изрисовал кучу бумаги.
В двух словах о печати он рассказать не смог, потому что сначала надо понять некоторую историю вопроса. Например, почему пришлось отбросить светлую идею растить эмбриона без головы в суррогатной матери, а затем вынимать из него почку и помещать её в биораставор для ускоренного созревания.
А пока главное. Не торопитесь пить всё что горит: до новой печени ещё очень далеко. Поехали.
Чем больше узнаёшь в своей области знания, тем чётче понимаешь, что никто не может знать всего.
По какой-то причине (за что, господи, за что?) моей областью стала разработка игр. Каждый, кто работает в этой сфере, скажет вам: никогда не добавляй сетевой многопользовательский режим в уже готовую игру, никогда, пьяный ты клоун.
Как бы то ни было, я именно это и сделал, и ненавижу себя за это. На удивление, вышло замечательно. Никто из нас не знает всего.
Проблема №1: ресурсы
Первый вопрос, который у меня возник: как сказать клиенту, что для рендеринга объекта нужно использовать такой-то меш?
Сериализировать весь меш? Не стоит, у клиента он уже есть на диске.
Передавать имя файла? Не-а, малоэффективно и небезопасно.
Ну ладно, может быть, просто строковый идентификатор?
К счастью, прежде чем у меня появилось время на реализацию собственных бредовых идей, я посмотрел доклад Майка Эктона, в котором он говорил об опасностях «ленивого принятия решений». Смысл в следующем: строки позволяют разработчикам лениво игнорировать принятие решений до момента создания работающего приложения, когда исправлять ошибки уже поздно.
Разработчики платформ, похожих на Facebook, признаются, что они создавались таким образом, чтобы вызывать зависимость. Должны ли мы последовать примеру управленцев соцсетей и отказаться от их использования? И способны ли на это простые смертные?
Марк Цукерберг не пользуется Facebook так же, как обычные люди. Согласно информации Bloomberg, у 33-летнего главы корпорации есть команда из 12 модераторов, удаляющих комментарии и спам с его страницы. «Небольшое количество» служащих помогают ему писать посты и составляют речи, несколько профессиональных фотографов делают тщательно подготовленные снимки с его встреч с ветеранами в Кентукки, владельцами малых предприятий в Миссури или торговцами чизстейков в Филадельфии.
Разработчики из компании Bonanza потратили более двух лет на создание программы для автоматического удаления фона с изображений. Задача оказалась гораздо сложнее, чем думали поначалу. Как оказалось, автоматическое удаление фона — одна из классических проблем компьютерного зрения, известная ещё с 80-х годов.
Как это часто бывает, если бы разработчики понимали всю сложность задачи, они бы вообще не брались за её решение. Но потом оказалось, что назад пути нет, и всё-таки им удалось добиться определённого успеха. 11 апреля они запустили конвертер Bonanza Background Burner, который неплохо очищает фон на произвольных фотографиях, при небольшой помощи или вовсе без неё. Доступ через API пока бесплатен, но в будущем владельцы сервиса что-нибудь придумают.
Японская компания Toshiba заявила о своем вкладе в развитие Интернета вещей и анализа больших данных. На этот раз она разработала нейроморфный процессор с очень низким энергопотреблением для нейронных сетей с временной задержкой (TDNN). Эта сеть состоит из большого количества модулей, в которых используется не цифровая, а аналоговая обработка данных.
В 16 играх машины одолели человека (в 17, если брать в расчет поражение Ли Седоля в го), но в будущем их ждут еще более впечатляющие достижения: решение самых ошеломляющих математических, физиологических и биологических проблем, победа над болезнями и старостью, ликвидация дорожных аварий, триумф в военных конфликтах и многое другое.
Мир изменился прямо на наших глазах, но не все заметили это. Когда и как программы научились играть безошибочно? Всегда ли проигрыш одного человека свидетельствует о поражении всего человечества? Обретет ли искусственный интеллект сознание?
Об авторе. Статья основана на лекции «Искусственный интеллект. История и перспективы», проведенной в московском офисе Mail.Ru Group Сергеем oulenspiegel Марковым. Сергей Марков занимается machine learning в «Сбербанке». В банковской сфере строят предиктивные модели для управления бизнес-процессом на основе достаточно больших обучающих выборок, которые могут включать несколько сотен миллионов кейсов. Среди своих хобби Сергей указывает шахматное программирование, ИИ для игр, минимаксные задачи. Программа SmarThink, созданная Сергеем Марковым, становилась чемпионом России (2004) и СНГ (2005) среди шахматных программ (2004), и сегодня входит в топ-30 сильнейших программ в мире. Также Сергей является основателем некоммерческого научно-просветительского портала 22 век.
За последнее десятилетие глубокие нейросети (Deep Neural Networks, DNN) превратились в превосходный инструмент для ряда ИИ-задач вроде классификации изображений, распознавания речи и даже участия в играх. По мере того, как разработчики пытались показать, чем обусловлен успех DNN в сфере классификации изображений, и создавали инструменты для визуализации (например, Deep Dream, Filters), помогающие понять, «что» именно «изучает» DNN-модель, возникло новое интересное применение: извлечение «стиля» из одного изображения и применение к другому, иного содержания. Это назвали «переносом визуального стиля» (image style transfer).
Уверен, что никому не нужно объяснять почему сайты должны быть гибкими и адаптивными. Все используют проценты и медиа-запросы в своей верстке. Сейчас это уже стандарт.
Но типографика до недавнего времени не была столь гибкой. Все что мы могли — изменять размеры шрифта от брейкпоинта к брейкпоинту. В таком случае мы получали скорее адаптивную типографику нежели отзывчивую. Для каждого медиа-запроса нужно задавать свои значения. Можно конечно использовать компонентный подход с относительными размерами шрифта, что может существенно ускорить процесс редактирования, но принципиально это ничего не меняет. При перемещении компонента в другое место нужно будет опять пробегать по всем медиа запросам и подставлять новые значения.
Но потом появились они — vw, vh, vmin, vmax — единицы измерения, которые базируются на viewport. У нас появился шанс на отзывчивую типографику.
Рубрика «Гость блога». Сегодня в гостях Николай Моисеев — сооснователь американской частной космической компании Final Frontier Design, которая занимается разработкой космических скафандров. О Николае и его компании многие могли уже узнать из публикаций «Медузы» или Geektimes. Сегодня он, по моей просьбе, комментирует съемочные кадры будущего научно-фантастического фильма «Марсианин» (The Martian).
Британская компания Surrey NanoSystems разработала технологию создания покрытия на основе углеродных нанотрубок с коэффициентом отражения 0,035% в видимом диапазоне. Презентация нового материала, названного Vantablack, состоится во время авиашоу в Фарнборо 19-20 июля. Пока что учёные продемонстрировали лабораторный образец — лист алюминиевой фольги с нанесённым на него покрытием. Оно поглощает 99,96% падающего света, из-за чего выглядит как «чёрная дыра» без каких либо отражений и теней. На фото участок с покрытием смотрится так, как будто часть кадра просто залили 100% черным цветом в графическом редакторе, однако и в реальности он выглядит точно так же.
Как-то друг попросил помочь с дипломной работой и дал ссылку на статью, в которой говориться о восстановлении изображения с помощью самоорганизующихся карт Кохонена. Почитав статью, я вначале решил, что это бред какой-то, и что нейросеть к восстановлению никаким боком не стыкуется. Но, я чуток ошибался, оказалось, что этот метод весьма увлекательный, и когда я его таки сделал, не мог набаловаться.
После публикации моей статьи о том, какой была бы Земля, будь она в два раза больше, у читателей появился вопрос: «А что насчёт тороидальной Земли»? Вопрос не самый оригинальный, эту тему уже обсуждали в онлайне и проводили её моделирование. Но я люблю всё делать сам, так что я попытался провести свой собственный анализ.
Может ли существовать тороидальная планета?
Стабильность тороидальной планеты неочевидна. С практической точки зрения планеты можно рассматривать как жидкие шарики без поверхностного натяжения – прочность камня не сравнить с весом планеты. Они обладают эквипотенциальными гравитационными поверхностями с учётом центробежного потенциала. Если бы это было не так, то на них встречались бы места, которые могли бы уменьшить свою энергию перетеканием в сторону понижения потенциала. Ещё один очевидный факт – существование верхней границы скорости вращения, после которой планета развалится: центробежная сила на экваторе превышает гравитацию и материал улетает в космос.
Я полагаю что все в общих чертах знают о существовании такого замечательного математического инструмента как преобразование Фурье. Однако в ВУЗах его почему-то преподают настолько плохо, что понимают как это преобразование работает и как им правильно следует пользоваться сравнительно немного людей. Между тем математика данного преобразования на удивление красива, проста и изящна. Я предлагаю всем желающим узнать немного больше о преобразовании Фурье и близкой ему теме того как аналоговые сигналы удается эффективно превращать для вычислительной обработки в цифровые.
(с) xkcd
Без использования сложных формул и матлаба я постараюсь ответить на следующие вопросы:
FT, DTF, DTFT — в чем отличия и как совершенно разные казалось бы формулы дают столь концептуально похожие результаты?
Как правильно интерпретировать результаты быстрого преобразования Фурье (FFT)
Что делать если дан сигнал из 179 сэмплов а БПФ требует на вход последовательность по длине равную степени двойки
Почему при попытке получить с помощью Фурье спектр синусоиды вместо ожидаемой одиночной “палки” на графике вылезает странная загогулина и что с этим можно сделать
Зачем перед АЦП и после ЦАП ставят аналоговые фильтры
Можно ли оцифровать АЦП сигнал с частотой выше половины частоты дискретизации (школьный ответ неверен, правильный ответ — можно)
Как по цифровой последовательности восстанавливают исходный сигнал
Я буду исходить из предположения что читатель понимает что такое интеграл, комплексное число (а так же его модуль и аргумент), свертка функций, плюс хотя бы “на пальцах” представляет себе что такое дельта-функция Дирака. Не знаете — не беда, прочитайте вышеприведенные ссылки. Под “произведением функций” в данном тексте я везде буду понимать “поточечное умножение”
Всего-то пару лет назад мы не могли общаться с приложениями Google сквозь уличный шум, не переводили русские надписи в Google Translate и не искали фото того самого лабрадудля в Google Photos, только лишь о нём услышав. Дело в том, что наши приложения были тогда недостаточно умны. Что ж, очень быстро они стали значительно, значительно умнее. Сегодня, благодаря технологии машинного обучения, все эти замечательные штуки, равно как и многое другое и более серьёзное, мы можем делать играючи.
В общем, встречайте: мы создали принципиально новую систему машинного обучения по имени TensorFlow. TensorFlow быстрее, умнее и гибче в сравнении с нашей предыдущей технологией (DistBelief, с 2011, та самая, что распознавала кошку без учителя), благодаря чему стало значительно проще адаптировать её к использованию в новых продуктах и исследовательских проектах. TensorFlow – высокомасштабируемая система машинного обучения, способная работать как на простом смартфоне, так и на тысячах узлов в центрах обработки данных. Мы используем TensorFlow для всего спектра наших задач, от распознавания речи до автоответчика в Inbox и поиска в Google Photos. Такая гибкость позволяет нам конструировать и тренировать нейросетки до 5 раз быстрее в сравнении с нашей старой платформой, так что мы действительно можем использовать новую технологию значительно оперативнее.
Право на анонимность уже стало мировым стандартом для обеспечения фундаментальных прав человека и гражданина в цифровую эпоху, прежде всего – права на свободу выражения мнения и права на тайну частной жизни / прайваси.
Так что же такое «право на анонимность», если мы говорим про интернет-пространство:
✓ Право на анонимный сёрфинг (поиск информации в сети) и анонимную отправку личных сообщений (e-mail, мессенджеры)
Анонимное соединение — это главное субъективное право, необходимое любому пользователю Интернета. Анонимным соединением считается соединение с сервером назначения, когда этот сервер не имеет возможности ни установить происхождение (IP-адрес/местонахождение) этого соединения, ни присвоить ему какой-либо идентификатор.
Пользователи должны иметь право на анонимный поиск информации в интернете, в том числе скрывать свои IP-адреса и отправлять сообщения анонимно. Осенью 2016 года Европейский суд справедливости (European Court of Justice) рассмотрел запрос немецкого Федерального Суда, связанного с иском представителя немецкой Пиратской партии к федеральному правительству. Жалоба была подана немецким гражданином в отношении хранения на правительственных сайтах динамических IP адресов после того, как пользователь покидает сайт. Европейский суд в своем решении признал динамический адреса (как и ранее статические адреса) персональными данными и указал, что операторы не имеют права сохранять динамические IP-адреса, кроме как для защиты от кибератак.
В первых двух частях нашего аналитического труда по теме анонимности в интернет-среде и правам граждан при сетевых коммуникациях (ч.1, ч.2) мы поговорили в целом про виды соответствующих цифровых прав нового времени, а также про российские законодательные нормы, которые, к сожалению, всё больше вносят не стимуляцию развития современных технологий и взаимодействия всех субъектов в онлайн-среде, а, наоборот, ведут к их закрепощению и нивелированию.
В данном посте будет идти речь уже о конкретных практиках правоприменения новых норм регуляции в России в этой сфере.
Когда люди не могут доверять законам, они всё больше доверяют технологиям. Наряду с прокси-серверами виртуальные частные сети VPN и луковичная сеть Tor являются самыми популярными средствами достижения анонимности в сети.
Привет, Хабр. Обычно я пишу программы для неговорящих людей, но решил удариться в крайности и сделать продукт для говорящих людей. Я хочу рассказать о разработке бота для VK, который переводит пересланные ему голосовые сообщения в текст. Сначала я использовал Yandex SpeechKit, но потом уперся в дневной лимит распознаваемых единиц и перешел на wit.ai, об этом и хочу рассказать, а также о фреймворке для создания ботов vk с помощью node.js, болтовне гугловского dialogflow.
Я по образованию программист, но по работе мне пришлось столкнуться с обработкой изображений. И тут для меня открылся удивительный и неизведанный мир цветовых пространств. Не думаю, что дизайнеры и фотографы узнают для себя что-то новое, но, возможно, кому-нибудь это знание окажется, как минимум полезно, а в лучшем случае интересно.
Такие задачи иногда возникают. Например, совсем недавно мне в руки попали данные натурного эксперимента, проводившегося 10 лет назад. Те графики, которые мне необходимы, оказались оформлены в виде… обычных растровых *.bmp-файлов. Таблиц со значениями среди материала по эксперименту не оказалось. А таблицы значений очень бы пригодились, ведь эти данные надо сравнить с моими результатами моделирования, а потом оформить всё это дело на должном уровне.
Эта проблема возникала ещё пару раз в прошлом. Например, когда я помогал моей любимой женщине делать курсовой по электрическим машинам — расчеты вели в Maple, а большинство расчетных данных имелись в учебнике Копылова в виде графиков. И это тоже растр. И много было попорчено крови, прежде чем нужные таблицы было вбиты нами в программу.
В общем, если у человека нет проблем, он их придумывает, чтобы успешно и героически их решать. Почесав затылок и вооружившись гуглом я стал искать не слишком болезненное решение задачи.
Понятно, что первый этап — растровые графики надо превратить в векторные. А из векторного формата, особенно если он открытый, числовые даные можно вытащить, маштабировать и превратить в таблицу.
Первым делом я опробовал Inkscape. Редактор этот я использую очень часто — несмотря на то что начало работы с ним давалось тяжело, на сегодня он — главный инструмент для рисования различных картин для статей, докладов и прочей научной документации.
Однако автоматические средства векторизации с задачей не справились, вернее справились, но не так как хотелось бы. Вполне возможно, что я не до конца разобрался с ними. В любом случае, попытки использовать Inkscape были оставлены на неопределенный срок и взор снова обратился к гуглу.
Ответ был найден… на ЛОРе! Ответом стал — Easy Trace Pro. По словам авторов эта программа — интелектуальный трассировщик картографических данных, и предназначена для векторизации карт.
Данная программа — проприетарное ПО для OS Windows, однако, вместе с платной версией 9 авторами предалагается полнофункциональная предыдущая версия — 7.99 для бесплатного скачивания и неограниченного использования. Кроме того, на сайте есть инструкция по запуску Easy Trace с помощью wine. Последнее я не пробовал — запустил виртуальную машину с виндой и установил бесплатную версию.
Результат превзошел мои ожидания. Возможно, использованная техника это очередной «велосипед», но она дала свои плоды, и если Вам это тоже интересно — прошу под кат.
Привет, Хабр! Давно у нас в блоге не было расшифровок мастер-классов. Исправляемся. В этом посте вас ждет грандиозное путешествие в мир шрифтов от древнейших времен до наших дней. Если вы хотите понять, каким образом шрифты влияют на наши эмоции и наконец научиться отличать гуманистический гротеск от ленточной антиквы — добро пожаловать под кат. И да, там очень много картинок. Передаем слово автору.
Шутка, написанная гарнитурой Times, на 10 % смешнее той, что написана гарнитурой Arial. Почему? Чёрт знает. Лучшее объяснение, которое я видел: юмор ассоциируется с агрессией, с остротой, с остроумием — а Times выглядит более острым, чем Arial.
Ещё один любопытный эксперимент, в котором участвовало 45 тыс. человек. Заходишь на сайт, тебе показывают статью Дэвида Дойча, британского физика. В статье автор пишет, что сегодня очень трудно внезапно умереть. Например, от инфекционного заболевания или в уличной драке. Лет сто назад это случалось намного чаще. Главный вывод статьи — сейчас мир безопасен как никогда. В среднем, конечно, ведь где-то постоянно идут локальные военные конфликты.
В английском языке много интересных и необычных слов, которые могут быть похожими на слова в русском по произношению, звучанию и написанию. Мы говорили о них в одной из предыдущих статей. Но бывает еще интереснее — целые фразы, которые не стоит переводить буквально. О них мы и поговорим в этой статье.
Повседневные фразы и инструкции
Тут сразу стоит отметить, что в английском довольно много фразовых глаголов, которые очень популярны, особенно в разговорной речи. Понятное дело, что sit down, stand up или come up уже никого не удивят, но есть другие интересные случаи, и не только с фразовыми глаголами.
В качестве официального портретиста испанских монархов на пике своей славы, Диего Веласкес писал королев, императоров и богов. Но одна из наиболее знаменитых его картин приоткрывает окно в более скромный мир. Женщина жарит яйца в горячем масле и готовиться вынуть их при помощи простой деревянной ложки. За ней слуга, несущий наполовину наполненную бутыль вина и дыню, обвязанную бечёвкой.
Такие картины особенно любят историки. Чрезвычайно талантливый художник со склонностью к реализму, выбравший один из тех нормальных эпизодов жизни, что редко сохраняются (так и сегодня — сколько современных художников решают нарисовать лавки с шаурмой или булочные? Историки подозревают, что в качестве моделей для ранних картин Веласкесу могли служить члены его семьи. Возможно, что эта женщина тоже его родственница, поскольку она появляется позже в том же году на одной из религиозных картин.
Меня зовут Григорий Сапунов, я СТО компании Intento. Занимаюсь я нейросетями довольно давно и machine learning’ом, в частности, занимался построением нейросетевых распознавателей дорожных знаков и номеров. Участвую в проекте по нейросетевой стилизации изображений, помогаю многим компаниям.
Давайте перейдем сразу к делу. Моя цель — дать вам базовую терминологию и понимание, что к чему в этой области, из каких кирпичиков собираются нейросети, и как это использовать.
План доклада такой. Сначала небольшое введение про то, что такое нейрон, нейросеть, глубокая нейросеть, чтобы мы с вами общались на одном языке.
Дальше я расскажу про важные тренды, что происходит в этой области. Затем мы углубимся в архитектуру нейросетей, рассмотрим 3 основных их класса. Это будет самая содержательная часть.
После этого рассмотрим 2 сравнительно продвинутых темы и закончим небольшим обзором фреймворков и библиотек для работы с нейросетями.
Не так давно столкнулся с проблемой поиска набора слов в большом тексте. Разумеется главной проблемой стала производительность. Поиск готовых решений порождал больше вопросов, чем давал ответов. Часто я натыкался на примеры использования каких-то сторонних коробок или онлайн-сервисов. А мне в первую очередь нужно было простое и легкое решение, которое в дальнейшем дало бы мысли для реализации собственной утилиты.
Несколько недель назад вышла замечательная англоязычная статься об open-source python-библиотеки FlashText. Эта библиотека предоставляла быстрое работающее решение задачи поиска и замены ключевых слов в тексте.
Т.к. на русском материалов подобной тематики не так много, то я решил перевести эту статью на русский. Под катом вас ждет описание проблемы, разбор принципа работы библиотеки а так же примеры тестов производительности.
Во многих странах переозвучка сериалов и кино на другой язык — не самое распространенное явление. Большинство фильмов и сериалов всё еще выходят на английском языке, а остальной контент чаще всего сопровождается субтитрами.
А вот российские зрители всё ещё сильно зависят от переозвучки на русский — настолько, что в советское время появлялись настоящие шедевры дубляжа, а после сформировалась особая культура переводов, в которые актёр озвучки вносил свой личный характер, интонации и шутки.
Мы решили рассказать о том, как как работают актёры дубляжа. История в двух частях.
В первой мы разберемся в общих вопросах: в чем разница между озвучкой и дубляжом, как выглядит весь процесс дубляжа фильма или сериала и почему быть актером дубляжа часто сложнее, чем играть на камеру.
Генерация SVG из изображений может использоваться для Placeholder’ов.
Я занимаюсь оптимизацией изображений и картинок для их быстрой загрузки. Одна из самых интересных областей исследования это Placeholder’ы: что показывать, когда изображение еще не загружено.
В последние дни я сталкивался с некоторыми методами загрузки, которые используют SVG, и я хотел бы описать их в этом посте.
В этом посте мы рассмотрим следующие темы:
Обзор различных типов Placeholder’ов
Placeholder на основе SVG (контуры, фигуры и силуэты)
На изображении выше многие увидят известную картину. Так выглядит большинство CSS файлов на продакшене. Мы все стараемся, чтобы наши веб-страницы загружались быстро; для достижения этой цели используем различные инструменты и техники оптимизации загрузки и рендеринга страниц. Об одном, но редко используемом методе, я бы хотел поговорить и рассказать, как мне удалось сократить размер CSS файла почты mail.ru на 180Кб.
Три года тьмы и холода привели к росту преступности, нищеты и появлению литературного шедевра
Двести лет назад произошло величайшее извержение вулкана в истории Земли. СтратовулканТамбора, расположенный на индонезийском острове Сумбава, взорвался с катастрофической силой в апреле 1815 года. [Это извержение стало крупнейшим по количеству выброшенного материала. Самым громким извержением считается взрыв вулкана Кракатау 1883 года / прим. перев.]
После тысячи лет спячки вулкану понадобилось всего несколько дней на разрушительное опустошение своих внутренностей и последующий коллапс. Концентрированная энергия этого события сильнейшим образом повлияла на человечество. Выстрелив своё содержимое в атмосферу с невероятной силой, Тамбора гарантировал достижение вулканическими газами верхних слоёв атмосферы, что привело к изменению сезонных ритмов глобальной климатической системы и погрузило человеческие сообщества по всему миру в хаос. Мелкие частицы в стратосфере затмили солнечный свет, и привели к наступлению длительного и самого разрушительного периода экстремальных погодных условий из всех, что наша планета видела за тысячу лет.
Эта статья разделена на две основные части, Трассировка лучей и Растеризация, в которых рассматриваются два основных способа получения красивых изображений из данных. В главе Общие концепции представлены некоторые базовые понятия, необходимые для понимания этих двух частей.
В этой работе мы сосредоточимся не на скорости, а на чётком объяснении концепций. Код примеров написан наиболее понятным образом, который не обязательно является самым эффективным для реализации алгоритмов. Есть множество способов реализации, я выбрал тот, который проще всего понять.
«Конечным результатом» этой работы будут два завершённых, полностью рабочих рендереров: трассировщик лучей и растеризатор. Хотя в них используются очень отличающиеся подходы, при рендеринге простой сцены они дают схожие результаты:
Первая часть статьи может быть доказательством того, что трассировщики лучей — это изящный пример программного обеспечения, позволяющий создавать потрясающе красивые изображения исключительно с помощью простых и интуитивно понятных алгоритмов.
К сожалению, эта простота имеет свою цену: низкую производительность. Несмотря на то, что существует множество способов оптимизации и параллелизации трассировщиков лучей, они всё равно остаются слишком затратными с точки зрения вычислений для выполнения в реальном времени; и хотя оборудование продолжает развиваться и становится быстрее с каждым годом, в некоторых областях применения необходимы красивые, но в сотни раз быстрее создаваемые изображения уже сегодня. Из всех этих областей применения самыми требовательными являются игры: мы ожидаем рендеринга отличной картинки с частотой не менее 60 кадров в секунду. Трассировщики лучей просто с этим не справятся.
Тогда как это удаётся играм?
Ответ заключается в использовании совершенно иного семейства алгоритмов, которое мы исследуем во второй части статьи. В отличие от трассировки лучей, которая получалась из простых геометрических моделей формирования изображений в человеческом глазе или в камере, сейчас мы будем начинать с другого конца — зададимся вопросом, что мы можем отрисовать на экране, и как отрисовать это как можно быстрее. В результате мы получим совершенно другие алгоритмы, которые создают примерно похожие результаты.
История с left-pad пробрала JavaScript-сообщество до самых костей. В то время как разбухший код продолжает замедлять наши сайты, сажать наши батареи и делать наш npm install медленным, многие разработчики решили сами провести тщательный аудит зависимостей, которые они привносят в свои проекты. Настало время, чтобы мы как сообщество встали и сказали: «Хватит!» Это сообщество принадлежит всем нам, а не только горстке JavaScript-разработчиков с шикарными длинными волосами.
Я решил описать свой опыт в области аудита зависимостей моего проекта и надеюсь, что эта информация будет полезной.
Занимаясь программированием рендеринга графики, мы живём в мире, в котором обязательны низкоуровневые оптимизации, чтобы добиться GPU-фреймов длиной 30 мс. Для этого мы используем различные методики и разработанные с нуля новые проходы рендеринга с повышенной производительностью (атрибуты геометрии, текстурный кеш, экспорт и так далее), GPR-сжатие, скрывание задержки (latency hiding), ROP…
Но в последнее время, особенно в свете перехода на 64 бита, я заметил рост количества неоптимизированного кода, словно в индустрии стремительно теряются все накопленные ранее знания. Да, старые трюки вроде быстрого обратного квадратного корня на современных процессорах контрпродуктивны. Но программисты не должны забывать о низкоуровневых оптимизациях и надеяться, что компиляторы решат все их проблемы. Не решат.
Эта статья — не исчерпывающее хардкорное руководство по железу. Это всего лишь введение, напоминание, свод базовых принципов написания эффективного кода для CPU. Я хочу «показать, что низкоуровневое мышление сегодня всё ещё полезно», даже если речь пойдёт о процессорах, которые я мог бы добавить.
В статье мы рассмотрим кеширование, векторное программирование, чтение и понимание ассемблерного кода, а также написание кода, удобного для компилятора.
25 сентября 2017 года в эфире федерального телеканала РЕН ТВ вышла передача посвященная теории плоской Земли, а уже 3 Октября Игорь Прокопенко получил премию «ТЭФИ» за программу «Военная тайна» в категории «Просветительская программа». Рассматриваемая же передача относится к циклу программ Игоря Прокопенко «Самые шокирующие гипотезы».
Написанное здесь, конечно же, не станет сюрпризом для большинства читателей, т.к. само название канала уже давно стало мемом, но всё же я решил детально разобрать этот выпуск, учитывая, что в данный момент появилось слишком много людей поддавшихся в 21 веке влиянию такого сектоподобного явления как теория плоской Земли в силу различных причин. И особо следует заметить, что обострение началось ещё задолго до мемов со школьником. Также, вопреки расхожему мнению, большинство адептов теории плоской Земли не являются троллями, всё намного печальнее.
В этой короткой заметке я хотел бы систематизировать (а именно, расположить в иерархию) многие популярные принципы проектирования программных приложений (test-driven development, ООП, SOLID и т. д.), а также рассмотреть следствия из этой иерархии.
В частности, такая иерархия (я надеюсь) позволит лучше расставлять приоритеты в разработке и профессиональном росте, лучше понимать старые технологии и быстрее изучать новые. При появлении новой парадигмы разработки (a la test-driven development) вы сможете быстро включить ее в эту иерархию и, следовательно, быстрее понять, из каких принципов исходили создатели парадигмы и как правильно ее использовать. Новичкам в программировании статья может быть полезна как обзор существующих принципов.
И в качестве самого базового я полагаю разумным считать принцип «управления сложностью/минимизации технической сложности» МакКоннела. А самыми важными срествами минимизации сложности являются модульность и абстракция.
Привет, Хабр! Сегодня я хочу рассказать вам, как можно изменить свое лицо на фото, используя довольно сложный пайплайн из нескольких генеративных нейросетей и не только. Модные недавно приложения по превращению себя в даму или дедушку работают проще, потому что нейросети медленные, да и качество, которое можно получить классическими методами компьютерного зрения, и так хорошее. Тем не менее, предложенный способ мне кажется очень перспективным. Под катом будет мало кода, зато много картинок, ссылок и личного опыта работы с GAN'ами.
Взявшись за написание небольшого, но реального и растущего проекта, мы «на собственной шкуре» убедились, насколько важно то, чтобы программа не только хорошо работала, но и была хорошо организована. Не верьте, что продуманная архитектура нужна только большим проектам (просто для больших проектов «смертельность» отсутствия архитектуры очевидна). Сложность, как правило, растет гораздо быстрее размеров программы. И если не позаботиться об этом заранее, то довольно быстро наступает момент, когда ты перестаешь ее контролировать. Правильная архитектура экономит очень много сил, времени и денег. А нередко вообще определяет то, выживет ваш проект или нет. И даже если речь идет всего лишь о «построении табуретки» все равно вначале очень полезно ее спроектировать.
К моему удивлению оказалось, что на вроде бы актуальный вопрос: «Как построить хорошую/красивую архитектуру ПО?» — не так легко найти ответ. Не смотря на то, что есть много книг и статей, посвященных и шаблонам проектирования и принципам проектирования, например, принципам SOLID (кратко описаны тут, подробно и с примерами можно посмотреть тут, тут и тут) и тому, как правильно оформлять код, все равно оставалось чувство, что чего-то важного не хватает. Это было похоже на то, как если бы вам дали множество замечательных и полезных инструментов, но забыли главное — объяснить, а как же «проектировать табуретку».
Хотелось разобраться, что вообще в себя включает процесс создания архитектуры программы, какие задачи при этом решаются, какие критерии используются (чтобы правила и принципы перестали быть всего лишь догмами, а стали бы понятны их логика и назначение). Тогда будет понятнее и какие инструменты лучше использовать в том или ином случае.
Данная статья является попыткой ответить на эти вопросы хотя бы в первом приближении.
Что-то происходит. Люди недовольны. Призрак гражданских беспорядков преследует наши программистские сообщества.
Впервые значимое число веб-разработчиков открыто ставят под сомнение веб-платформу. Вот характерная статья и обсуждение. Вот другая статья. И ещё одна. Я бы мог перечислить и больше, но если вы достаточно интересуетесь программированием, чтобы читать эту статью, то наверняка уже читали в этом году хотя бы одну напыщенную декламацию о современном состоянии веб-разработки. Эта статья не из таких. Я не могу соревноваться в издевательствах над существующим статусом-кво с людьми, которым приходится заниматься веб-разработкой каждый день. Это другая статья.
Демосцена всегда поражала воображение. В 1994, 2004, 2017 годах разработчики снова и снова всех удивляют, превращая файл размером 64 килобайта в нечто немыслимое. Демо стало не просто асаной, из которой программист выжимает максимум возможностей своего компьютера и собственных скиллов, а превратилось в отдельный вид киберискусства.
Современные демки откололись от континента прочих субкультур (где-то на берегу остались представители оверклокинга) и дрейфуют в одиночестве. Они не гимн возможностей компьютерной техники, а ding an sich selbst betrachtet — метафизическая вещь в себе, которая может быть фрагментом игры, аниме или трейлером фильма-катастрофы.
А еще демо может быть о космосе и это, вероятно, самый подходящий формат. Чтобы исследовать пространство и воочию наблюдать космологические модели, достаточно всего 64K. Сгенерированное изображение смешивает элементы геймдизайна, кинематографа и программирования в синхронизированный аудиовизуальный коктейль, который затянет вас в процесс отрешенного созерцания межгалактических чудес.
Проффесор Марк Поуст из Нидерландского университета Maastricht, создавший первый в мире «гамбургер в лаборатории», ожидает, что искусственно выращенное мясо появится в продаже в течение пяти лет.
Первый прототип был приготовлен и съеден в Лондоне в 2013 году по цене £215,000 (€292,000; ₽2,055,000) за 1 бургер На данный момент, цена мяса снизилась до невероятных £7 ($11; ₽700) Это значит, что за два года удалось снизить цену в 31 000 раз!
Необходимо срочно вводить безусловный доход ввиду грядущего будущего робомобилей
В прошлом году мы с приятелем поехали на машине из Нового Орлеана (Луизиана) в Орландо (Флорида), и, проезжая город за городом, мы беседовали о потенциальном эффекте, который робомобили окажут не только на дальнобойщиков, но и на всю локальную экономику, зависящую от их зарплат. И когда ты начинаешь задумываться о последствиях такого удара под дых для Америки, ты понимаешь, что будущее не так уж радужно.
Экономики мелких городов ощутимо просядут – таких потрясений мы не знали с тех пор, как построили систему шоссейных дорог между штатами. Если вы считаете, что я преувеличиваю – позвольте мне рассказать вам вот что:
на карте отмечены самые популярные профессии в 2014 году
И это должно сразу сказать вам, как сильно американская экономика зависит от водителей грузовиков. Согласно информации американской ассоциации дальнобойщиков (ATA), в США их работает 3,5 миллиона, а ещё 5,2 миллиона человек работает в индустрии грузоперевозок не за рулём. В сумме получаем 8,7 миллиона человек, чья работа связана с грузовиками.
В настоящей заметке я расскажу о том, как можно построить систему оптического распознавания структурной информации, опираясь на алгоритмы, применяющиеся в обработке изображений и их реализации в рамках библиотеки OpenCV. За описанием системы стоит активно развивающийся open source проект Imago OCR, который может быть непосредственно полезен в распознавании химических структур, однако в заметке я не буду говорить о химии, а затрону более общие вопросы, решение которых поможет в распознавании структурированной информации различного рода, например таблицы или графики.
Интервьюер: Итак, вы считаете себя плотником? Плотник: Всё верно. Это именно то, чем я занимаюсь.
Интервьюер: Как долго вы занимаетесь этим? Плотник: Десять лет.
Интервьюер: Очень хорошо. А теперь я бы хотел задать вам несколько технических вопросов, чтобы оценить, насколько вы впишетесь в нашу команду. Договорились? Плотник: Конечно, было бы неплохо.
Интервьюер: Должен вам сказать, что мы работаем в подразделении, занимающимся постройкой большого количества коричневых домов. Доводилось ли вам строить множество коричневых домов? Плотник: Ну, я же плотник — я строю дома, а люди уже красят их так, как пожелают.
Интервьюер: Да, я понимаю, но не могли бы вы подсказать мне, сколько у вас опыта именно с коричневыми? Ну, плюс-минус. Плотник: Я действительно понятия не имею. С того момента, как дом построен, меня не волнует, в какой цвет его покрасят. Может, шесть месяцев?
Редакция Оксфордского словаря выбрала слово «постправда» (post-truth) почетным «словом 2016 года». Термин этот описывает обстоятельства, в которых объективные факты менее важны для формирования общественного мнения, чем обращение к эмоциям и личным убеждениям.
Особенно высокая частота использования этого слова наблюдалась в англоязычных публикациях после президентских выборов в США в связи с распространением большого количества фейковых новостей, после которых сама истина большого значения не имела.
По мнению ряда аналитиков, распространение фальшивых дискредитирующих новостей стало одной из причин поражения Хилари Клинтон на выборах. Одним из главных источников ложных новостей стала алгоритмическая лента Facebook.
На этом фоне почти незамеченными остались новости, поступающие от разработчиков в сфере искусственного интеллекта. Мы уже привыкли, что нейросети рисуют картины, создают фото человека по его словесному описанию, генерируют музыку. Они делают всё больше, и с каждым разом у них получается всё лучше. Но самое интересное в том, что машины научились создавать фейки.
Ребёнком я увидел версию фильма «Планета обезьян» от 1968 года. Как будущий приматолог я был им заворожён. Много лет спустя я нашёл анекдот о съёмках этого фильма: в обед люди, игравшие шимпанзе, и люди, игравшие горилл, ели отдельными группами.
Говорят, что «В этом мире есть два типа людей: те, кто делят людей на два типа, и те, кто не делят». На самом деле первого вида людей гораздо больше. И последствия деления людей на «наших» и «не наших», членов нашей группы и остальных, людей и «других», могут быть очень тяжкими.
Все люди проводят разделительную черту «свой/чужой» по расам, этническим признакам, полу, языковой группе, религии, возрасту, социально-экономическому статусу, и так далее. И в этом нет ничего хорошего. Мы делаем это удивительно быстро и эффективно с нейробиологической точки зрения. У нас существует сложная систематика и классификация способов, которыми мы наговариваем на «них». Мы делаем это с изменчивостью, варьирующейся от мелкой минутной агрессии до дикарской резни. А также мы постоянно определяем, что плохого в «них», основываясь на чистых эмоциях, за которыми следует примитивная рационализация, которую мы путаем с рациональностью. Грустно.
От переводчика: данный текст даётся с незначительными сокращениями по причине местами излишней «разжёванности» материала. Автор абсолютно справедливо предупреждает, что отдельные темы покажутся чересчур простыми или общеизвестными. Тем не менее, лично мне этот текст помог упорядочить имеющиеся знания по анализу сложности алгоритмов. Надеюсь, что он будет полезен и кому-то ещё. Из-за большого объёма оригинальной статьи я разбила её на части, которых в общей сложности будет четыре. Я (как всегда) буду крайне признательна за любые замечания в личку по улучшению качества перевода.
Введение
Многие современные программисты, пишущие классные и широко распространённые программы, имеют крайне смутное представление о теоретической информатике. Это не мешает им оставаться прекрасными творческими специалистами, и мы благодарны за то, что они создают.
Тем не менее, знание теории тоже имеет свои преимущества и может оказаться весьма полезным. В этой статье, предназначенной для программистов, которые являются хорошими практиками, но имеют слабое представление о теории, я представлю один из наиболее прагматичных программистских инструментов: нотацию «большое О» и анализ сложности алгоритмов. Как человек, который работал как в области академической науки, так и над созданием коммерческого ПО, я считаю эти инструменты по-настоящему полезными на практике. Надеюсь, что после прочтения этой статьи вы сможете применить их к собственному коду, чтобы сделать его ещё лучше. Также этот пост принесёт с собой понимание таких общих терминов, используемых теоретиками информатики, как «большое О», «асимптотическое поведение», «анализ наиболее неблагоприятного случая» и т.п.
Двоичная куча (binary heap) – просто реализуемая структура данных, позволяющая быстро (за логарифмическое время) добавлять элементы и извлекать элемент с максимальным приоритетом (например, максимальный по значению).
Для дальнейшего чтения необходимо иметь представление о деревьях, а также желательно знать об оценке сложности алгоритмов. Алгоритмы в этой статье будут сопровождаться кодом на C#.
Введение
Двоичная куча представляет собой полное бинарное дерево, для которого выполняется основное свойство кучи: приоритет каждой вершины больше приоритетов её потомков. В простейшем случае приоритет каждой вершины можно считать равным её значению. В таком случае структура называется max-heap, поскольку корень поддерева является максимумом из значений элементов поддерева. В этой статье для простоты используется именно такое представление. Напомню также, что дерево называется полным бинарным, если у каждой вершины есть не более двух потомков, а заполнение уровней вершин идет сверху вниз (в пределах одного уровня – слева направо).
Пройдясь по хабра-поиску выяснил, что готового решения для кропа-ресайза изображений, на движке JavaScript/HTML/CSS еще не предлагалось. Поэтому, позвольте представить вашему вниманию модуль для ваших сайтов, частично реализуюший функционал редактирования, распространенный на фото-хостингах.
Нейронные сети могут делать много разных вещей. Они могут понимать наши голоса, распознавать изображения и переводить речь, но знаете ли вы, что еще они умеют рисовать? Изображение сверху демонстрирует некоторые сгенерированные результаты применения нейронного рисования.
Сегодня я собираюсь познакомить вас с тем как это делается. Прежде всего, убедитесь, что у вас обновленная копия Ubuntu (14.04 — та, что использовал я). Вам необходимо иметь несколько гигов свободного пространства на жестком диске и в оперативной памяти, хотя бы не менее 6 GB (больше оперативки для больших выводимых разрешений). Для запуска Ubuntu как виртуальной машины, вы можете использовать Vagrant вместе с VirtualBox.
Преимущественно медиафайлы. На полном серьезе, без шуток.
Введение
Бывает, случается так, что вы хотите скачать альбом 2007 года исполнителя, который кроме вас известен 3.5 людям, какой-нибудь испанский ска-панк или малопопулярный спидкор европейского происхождения. Находите BitTorrent-раздачу, ставите на закачку, быстро скачиваете 14.7%, и… все. Проходит день, неделя, месяц, а процент скачанного не увеличивается. Вы ищете этот альбом в поисковике, натыкаетесь на форумы, показывающие ссылки только после регистрации и 5 написанных сообщений, регистрируетесь, флудите в мертвых темах, вам открываются ссылки на файлообменники вроде rapidshare и megaupload, которые уже сто лет как умерли.
Увы, частая ситуация в попытке хоть что-то скачать
Такое случается. В последнее время, к сожалению, случается чаще: правообладатели и правоохранительные органы всерьез взялись за файлообмен; в прошлом году закрылись или были закрыты KickassTorrents, BlackCat Games, what.cd, btdigg, torrentz.eu, EX.ua, fs.to, torrents.net.ua, и еще куча других сайтов. И если поиск свежих рипов фильмов, сериалов, музыки, мультиков все еще не представляет большой проблемы, несмотря на многократно участившееся удаления со стороны правообладателей контента из поисковых систем, торрент-трекеров и файлообменников, то поиск и скачивание оригинала (DVD или Blu-Ray) фильмов и сериалов или просто ТВ-рипов 7-летней давности на не-английском и не-русском языке — не такая уж простая задача.
Сегодня Яндекс выложил в open source собственную библиотеку CatBoost, разработанную с учетом многолетнего опыта компании в области машинного обучения. С ее помощью можно эффективно обучать модели на разнородных данных, в том числе таких, которые трудно представить в виде чисел (например, виды облаков или категории товаров). Исходный код, документация, бенчмарки и необходимые инструменты уже опубликованы на GitHub под лицензией Apache 2.0.
CatBoost – это новый метод машинного обучения, основанный на градиентном бустинге. Он внедряется в Яндексе для решения задач ранжирования, предсказания и построения рекомендаций. Более того, он уже применяется в рамках сотрудничества с Европейской организацией по ядерным исследованиям (CERN) и промышленными клиентами Yandex Data Factory. Так чем же CatBoost отличается от других открытых аналогов? Почему бустинг, а не метод нейронных сетей? Как эта технология связана с уже известным Матрикснетом? И причем здесь котики? Сегодня мы ответим на все эти вопросы.
Изменение размера изображения с учётом содержимого (Content Aware Image Resize), жидкое растяжение (liquid resizing), ретаргетинг (retargeting) или вырезание шва (seam carving) относятся к методу изменения размера изображения, где можно вставлять или удалять швы, или наименее важные пути, для уменьшения или наращивания изображения. Об этой идее я узнал из ролика на YouTube, от Shai Avidan и Ariel Shamir.
В этой статье будет рассмотрена простая пробная реализация идеи изменения размера изображения с учётом содержимого, естественно на языке Rust.
Для подопытной картинки, я поискал по запросу1"sample image", и нашел её2:
Вы наверное уже слышали о технологии масштабирования Liquid Resize, которая учитывает содержимое изображения. Если вам интересно как оно все работает и как можно реализовать все это самому, то читайте далее (осторожно, много рисунков).
На протяжении довольно долгого времени я и мои коллеги, участники Русскоязычной поддержки Wolfram Mathematica, занимались разработкой и коллекционированием полностью бесплатных и качественных ресурсов на русском языке, которые позволили бы любому желающему научиться программировать на языке Wolfram Language (Mathematica) самостоятельно.
Думаю, что пришла пора рассказать об этом на Хабрахабре, создав статью о разрабатываемой коллекции ресурсов, которая будет постоянно расширяться и пополняться, и будет служить, по сути, русскоязычным аналогом страницы "Where can I find examples of good Mathematica programming practice?" на сайте Mathematica at StackExchange.com.
В этой статье я расскажу, как достаточно быстро и просто написать редактор изображений на C++ с использованием библиотеки компьютерного зрения opencv. Реализованы такие эффекты, как насыщенность, экспозиция, резкость, контрастность и другие. Никакой магии!
Поэзия — та же добыча радия. В грамм добыча, в годы труды. Изводишь единого слова ради Тысячи тонн словесной руды. Но как испепеляюще слов этих жжение Рядом с тлением слова-сырца. Эти слова приводят в движение Тысячи лет миллионов сердца.
Владимир Маяковский
Напомню, что наша ближайшая задача — показать алгоритм универсального обобщения. Такое обобщение должно удовлетворять всем требованиям, сформулированным ранее в десятой части. Кроме того, оно должно быть свободно от традиционных для многих методов машинного обучения недостатков (комбинаторный взрыв, переобучение, схождение к локальному минимуму, дилемма стабильности-пластичности и тому подобное). При этом механизм такого обобщения должен не противоречить нашим знаниям о работе реальных нейронов живого мозга.
Сделаем еще один шаг в сторону универсального обобщения. Опишем идею комбинаторного пространства и то, как это пространство помогает искать закономерности и тем самым решать задачу обучения с учителем.
Hello, Habr! Недавно мы получили от “Известий” заказ на проведение исследования общественного мнения по поводу фильма «Звёздные войны: Пробуждение Силы», премьера которого состоялась 17 декабря. Для этого мы решили провести анализ тональности российского сегмента Twitter по нескольким релевантным хэштегам. Результата от нас ждали всего через 3 дня (и это в самом конце года!), поэтому нам нужен был очень быстрый способ. В интернете мы нашли несколько подобных онлайн-сервисов (среди которых sentiment140 и tweet_viz), но оказалось, что они не работают с русским языком и по каким-то причинам анализируют только маленький процент твитов. Нам помог бы сервис AlchemyAPI, но ограничение в 1000 запросов в сутки нас также не устраивало. Тогда мы решили сделать свой анализатор тональности с блэк-джеком и всем остальным, создав простенькую рекурентную нейронную сеть с памятью. Результаты нашего исследования были использованы в статье “Известий”, опубликованной 3 января.
В этой статье я немного расскажу о такого рода сетях и познакомлю с парой классных инструментов для домашних экспериментов, которые позволят строить нейронные сети любой сложности в несколько строк кода даже школьникам. Добро пожаловать под кат.
После недавнего выпуска Retina MacBook Pro и The new IPad, экраны с увеличенной плотностью пикселей начали активно входить в нашу жизнь. Что это значит для веб-разработчиков?
* На самом деле не совсем так. При разработке информационной системы, частью которой является различная обработка конструкторско-технологической документации, у меня возникла проблема, которую вкратце можно описать следующим образом. Сегодня мы имеем один состав изделия, за день приходит несколько изменений по различным частям этого изделия и к вечеру уже неясно, что же изменилось? Изделия порой могут иметь более 10 000 элементов в составе, элементы не уникальны, а реальность такова, что изменения по составу могут активно приходить, хотя изделие уже почти готово. Непонимание объема изменений усложняет планирование.
Состав изделия можно представить в виде древовидного графа. Не найдя подходящего способа сравнения двух графов, я решил написать свой велосипед.
Эта статья выросла из идеи продвинутого обучения наших сотрудников технической поддержки работе с mod_rewrite. Практика показала, что после изучения имеющихся в большом количестве учебников на русском языке саппортам хорошо дается решение шаблонных задач, но вот самостоятельное составление правил происходит методом проб и большого количества ошибок. Проблема заключается в том, что для хорошего понимания работы mod_rewrite требуется изучение оригинальной англоязычной документации, после чего — либо дополнительные разъяснения, либо часы экспериментов с RewriteLog.
В статье изложен механизм работы mod_rewrite. Понимание принципов его работы позволяет четко осознавать действие каждой директивы и ясно представлять себе, что происходит в тот или иной момент внутри mod_rewrite при обработке директив.
Я предполагаю, что читатель уже знаком с тем, что такое mod_rewrite, и не буду описывать его основы, которые легко найти в интернете. Также нужно отметить, что в статье освещается работа mod_rewrite при использовании его директив в файле .htaccess. Отличия при работе в контексте <VirtualHost> изложены в конце статьи.
Итак, вы изучили mod_rewrite, составили несколько RewriteRule и успели столкнуться с бесконечными перенаправлениями, со случаем, когда правило почему-то не ловит ваш запрос, а также с непредсказуемой работой группы правил, когда последующее правило неожиданно изменяет запрос, кропотливо подготовленный правилами предыдущими.
Когда дело доходит до рендеринга шрифта на Вебе, дизайнер может сделать не слишком многое. То, как шрифт выглядит на экране, по большей части зависит от операционных систем, браузеров, дизайна гарнитур, шрифтовых файлов и от того, дополнены ли эти файлы инструкциями для самых неожиданных сценариев рендеринга. Но иногда свойства CSS могут повлиять на то, как выглядит шрифт.
В данном сообществе я нашел много статей про известную шифровальную машинку «Enigma», но нигде из них не описывался подробный алгоритм ее работы. Наверняка многие скажут, что это не нуждается в афишировании, — я же надеюсь, что кому-нибудь да будет полезно об этом узнать.
Легко подсчитать, что несжатое полноцветное изображение, размером 2000*1000 пикселов будет иметь размер около 6 мегабайт. Если говорить об изображениях, получаемых с профессиональных камер или сканеров высокого разрешения, то их размер может быть ещё больше. Не смотря на быстрый рост ёмкости устройств хранения, по-прежнему весьма актуальными остаются различные алгоритмы сжатия изображений. Все существующие алгоритмы можно разделить на два больших класса:
Алгоритмы сжатия без потерь;
Алгоритмы сжатия с потерями.
Когда мы говорим о сжатии без потерь, мы имеем в виду, что существует алгоритм, обратный алгоритму сжатия, позволяющий точно восстановить исходное изображение. Для алгоритмов сжатия с потерями обратного алгоритма не существует. Существует алгоритм, восстанавливающий изображение не обязательно точно совпадающее с исходным. Алгоритмы сжатия и восстановления подбираются так, чтобы добиться высокой степени сжатия и при этом сохранить визуальное качество изображения.
В последнее время на Хабре появилось несколько статей о том, как можно удобно читать техническую и художественную литературу. Разгорались горячие споры об электронных читалках и способах печати нужного материала.
В своей статье мне хотелось бы поподробнее остановиться на вопросах собственно печати (как сделать этот процесс быстрым и удобным) и изготовления книги из доступных материалов.
Большое вступление
Некоторое время назад мне захотелось прочитать цикл Дугласа Адамса «Автостопом по галактике». Я попробовал почитать несколько переводов и не один меня не устроил. Поэтому было принято решение — читать на английском! Найти эти книги в оригинале в наших книжных магазинах довольно сложно. А если и есть, то только первая часть цикла. В электронном виде найти несколько проще. Но я предпочитаю читать с бумаги (читалку на E-ink куплю обязательно — очень нравятся), поэтому книги я распечатываю.
Первые две книги выглядели так:
Я их прочитал с огромным удовольствием, но выглядели они не очень хорошо. И я решил, что «Life, the Universe, and Everything» нужно делать книжкой.
Процесс с картинками и комментариями под катом. Осторожно, действительно много картинок.
Кириллу и Мефодию было нелегко. Они создавали русскую азбуку на основе греческого алфавита и для обозначения звуков, которых в греческом не было, им пришлось придумывать новые буквы. Некоторые из них получились странными.
С тех пор алфавит прошел через многочисленные реформы, часть букв исчезла навсегда, но некоторые из изобретений Кирилла и Мефодия дожили до наших дней. Они и сейчас выделяются на фоне остальных букв и заставляют страдать русских дизайнеров. Логомашина собрала факты о самых странных буквах кириллицы.
Приветствуем наших читателей на страницах блога iCover! На прошедшей в начале февраля в Сан-Франциско Международной конференции International Solid State Circuits Conference (ISSCC-2016) группа разработчиков из MIT (Massachusetts Institute of Technology) продемонстрировала действующий прототип чипа нового поколения Eyeriss, создававшегося как концептуальное решение, позволяющее воссоздавать возможности алгоритмов нейронных сетей в широком спектре устройств малой мощности.
Предлагаю Вашему вниманию обзор посвященный оптимизации изображений формата PNG и JPEG без потери качества. Под «без потери качества» подразумевается, что визуально оригинальные и оптимизированные изображения ни чем не будут отличаться. Я читал на Хабре довольно много статьей посвященных данному вопросу, но скажу, большая часть — полная чушь, в них констатируются факты, а не причины. Данный обзор посвящен людям, которые имеют базовые знания об оптимизации изображений.
Представляю вашему вниманию заключительную статью из трилогии «Восстановление расфокусированных и смазанных изображений». Первые две вызвали заметный интерес — область, действительно, интересная. В этой части я рассмотрю семейство методов, которые дают лучшее качество, по сравнении со стандартным Винеровским фильтром — это методы, основанные на Total Variaton prior. Также по традиции я выложил новую версию SmartDeblur (вместе с исходниками в open-source) в которой реализовал этот метод. Итоговое качество получилось на уровне коммерческих аналогов типа Topaz InFocus. Вот пример обработки реального изображения с очень большим размытием:
Не так давно я опубликовал на хабре первую часть статьи по восстановлению расфокусированных и смазанных изображений, где описывалась теоретическая часть. Эта тема, судя по комментариям, вызвала немало интереса и я решил продолжить это направление и показать вам какие же проблемы появляются при практической реализации казалось бы простых формул.
В дополнение к этому я написал демонстрационную программу, в которой реализованы основные алгоритмы по устранению расфокусировки и смаза. Программа выложена на GitHub вместе с исходниками и дистрибутивами.
Ниже показан результат обработки реального размытого изображения (не с синтетическим размытием). Исходное изображение было получено камерой Canon 500D с объективом EF 85mm/1.8. Фокусировка была выставлена вручную, чтобы получить размытие. Как видно, текст совершенно не читается, лишь угадывается диалоговое окно Windows 7.
И вот результат обработки:
Практически весь текст читается достаточно хорошо, хотя и появились некоторые характерные искажения.
Под катом подробное описание проблем деконволюции, способов их решения, а также множество примеров и сравнений. Осторожно, много картинок!
Восстановление искаженных изображений является одной из наиболее интересных и важных проблем в задачах обработки изображений – как с теоретической, так и с практической точек зрения. Частными случаями являются размытие из-за неправильного фокуса и смаз – эти дефекты, с которым каждый из вас хорошо знаком, очень сложны в исправлении – именно они и выбраны темой статьи. С остальными искажениями (шум, неправильная экспозиция, дисторсия) человечество научилось эффективно бороться, соответствующие инструменты есть в каждом уважающем себя фоторедакторе.
Почему же для устранения смаза и расфокусировки практически ничего нету (unsharp mask не в счет) – может быть это в принципе невозможно? На самом деле возможно – соответствующий математический аппарат начал разрабатываться примерно 70 лет назад, но, как и для многих других алгоритмов обработки изображений, все это нашло широкое применение только в недавнее время. Вот, в качестве демонстрации вау-эффекта, пара картинок:
Я не стал использовать замученную Лену, а нашел свою фотку Венеции. Правое изображение честно получено из левого, причем без использования ухищрений типа 48-битного формата (в этом случае будет 100% восстановление исходного изображения) – слева самый обычный PNG, размытый искусственно. Результат впечатляет… но на практике не все так просто. Под катом подробный обзор теории и практические результаты. Осторожно, много картинок в формате PNG!
Взаимодействие человека с компьютером во многом опирается на графические элементы интерфейса, и цвет играет в этом процессе не последнюю роль. Как однажды сказал Pierre Bonnard: «Цвет не просто делает дизайн приятным для глаз, но и подкрепляет его».
Проектируя новый продукт, дизайнеры часто затрудняются с составлением цветовой гаммы, так как существует неограниченное число возможных сочетаний. В этой статье мы рассмотрим восемь основных правил, которые могут помочь вам с выбором.
Вот что строил испанский архитектор Антонио Гауди:
Его здания описывают как «бионические дома», некоторые говорят о «летящей пластичной материи». За морем восторгов художников и дизайнеров, как мне показалось, упущена некоторая невероятная рационализация и прагматичность. Гауди был в первую очередь отличным разработчиком, математиком и геометром. Но чтобы объяснить это, сначала я покажу другую картинку:
Это два крепления. Первое производится серийно — оно просто в проектировании, просто в изготовлении, дёшево и невероятно уродливо. Второе красивое, и требует на 25% меньше материала для того, чтобы выдержать тот же вес (то есть — куда прочнее). Только его трудно рассчитать, оно будет дороже в серии — и придётся подумать.
Примерно то же самое делал Гауди. Ему пришлось обойтись без математического аппарата и современных материалов. И ещё действовать в рамках строго ограниченного бюджета. Он, фактически, заложил новые принципы всего от фасада до последней дверной ручки, создал шедевры оптимизации — в общем смёл все стереотипы как сухие листья, создал с нуля теорию и воплотил её. В девятнадцатом веке всё то, что он делал, было просто диким. Некоторые даже считали его сумасшедшим.
Я продолжаю цикл статей по разработке метода безытеративного обучения нейронных сетей. В этой статье будем обучать однослойный персептрон с сигмоидальной активационной ф-ей. Но этот метод можно применить для любых нелинейных биективных активационных ф-й с насыщением и первые производные которых симметричны относительно оси OY.
Долгое время iOS критиковали за использование скеоморфов: зелёных фонов а-ля покерное сукно, «деревянных» книжных полок и «кожаной» прошивки. Однако новый экспериментальный интерфейс делает ставку на скеоморфы не в оформлении, а в инструментарии.
Сама идея взята из концепта, разработанного специалистом из Университета Карнеги Меллона совместно с Future Interfaces Group. Суть идеи: люди используют инструменты для манипуляций с окружающим миром, так почему нельзя их использовать для работы с тачскрином?
Достаточно странно, что никто на Хабре не написал, но, на мой взгляд, сегодня произошло знаковое событие. IBM представила новый, полностью законченный чип, реализующий нейронную сетку. Программа его разработки, существовала давно и шла достаточно успешно. На Хабре уже была статья о полномасштабной симуляции.
Этим постом мы хотели бы начать цикл статей, посвященных задаче изменения голоса. В зарубежной литературе данную задачу часто именуют термином voice morphing, в отечественной литературе данная задача ещё не получила достаточного освещения как в научных, так и в инженерных кругах. Тема является достаточно обширной и во многом творческой. В результате работы в данном направлении у нас накопился определенный опыт, который мы планируем систематизировать и изложить, а также передать основную суть некоторых алгоритмов.
Изменение голоса может преследовать разную цель. Два основных направления, которые тут однозначно можно выделить – это получение реалистичного звучания измененного голоса и получение некоторого причудливо-фантастичного звучания. Неплохих результатов во втором случае вполне можно добиться, обрабатывая речевой сигнал как обычный звук, не заостряя внимание на его особенностях и делая многие допущения. Например, индустрия электронной музыки породила колоссальное количество разнообразных аудио-эффектов и результат их применения к речевому сигналу помогает создать самый невероятный образ говорящего. В задаче реалистичного изменения голоса применение «музыкальных» (назовем их так) аудио-эффектов может привнести искажения, не характерные для натуралистичного звучания речи. В подобном случае необходимо более точно понимать, из каких звуков состоит речь, как они образуются и какие их свойства являются критическими для восприятия. Проще говоря — необходимо производить анализ сигнала перед его обработкой. При автоматизированной обработке речевого сигнала в реальном времени этот анализ усложняется многократно, т.к. умножается количество неопределенностей, которые надо как-то попытаться разрешить, и сокращается количество применимых алгоритмов. В ближайших статьях мы рассмотрим варианты простейшей реализации таких эффектов, как изменение пола говорящего и изменение возраста говорящего. Чтобы читатель лучше понимал, какие параметры сигнала будут изменяться, в первых статьях будут затронуты основные вопросы образования звуков речи и способы формального описания речевого сигнала. После этого уже будут обсуждаться конкретные предлагаемые алгоритмы изменения голоса, их сильные и слабые стороны.
P.S. Добавил дополнительные ссылки на первоисточники
Данным постом мы продолжаем цикл статей, посвященных задаче анализа и изменения голоса человека. Напомним кратко о содержании предыдущей статьи:
— было кратко рассказано о звуковом составе речи — были описаны такие важные процессы как фонация и артикуляция — была дана нестрогая классификация звуков человеческой речи и описаны характерные особенности классов звуков — кратко были обозначены проблемы, возникающие при обработке речевых сигналов
Также мы немного обозначили задачи, которые фактически решает наше подразделение в компании i-Free. Закончена предыдущая статья была «громким» обещанием описать модели представления речевого сигнала и показать, как данные модели возможно использовать для изменения голоса диктора.
Тут сразу сделаем небольшую оговорку. Термин «речевой сигнал» может восприниматься по-разному и нередко значение зависит от контекста. В контексте нашей работы нас интересуют лишь звуковые-акустические свойства речевого сигнала, его смысловая и эмоциональная нагрузка в данной и ближайших статьях рассматриваться не будут.
При творческом подходе к задаче изменения голоса большинство известных моделей представления речевого сигнала являются весьма мощным инструментом, позволяющим сделать очень и очень многое. Как-то классифицировать подобные начинания не видится целесообразным, а на демонстрацию «всего подряд» уйдет масса времени. В данной и следующей статьях мы ограничимся лишь кратким описанием наиболее часто применяемых моделей и как-то попытаемся объяснить их физический/практический смысл. Примеры применения данных моделей будут показаны несколько позже — в следующих статьях мы опишем простейшую реализацию таких эффектов, как изменения пола и возраста диктора.
WARNING!
Эта статья ставит своей целью совсем чуть-чуть описать физику формирования звука в речевом тракте с помощью упрощенной модели. Как следствие, статья содержит некоторое количество формул и, возможно, не вполне очевидных переходов. Первоисточники указаны в тексте и при желании можно более подробно ознакомиться с данным материалом самостоятельно. Описанные в данной статье модели редко применяются для практических задач обработки записанной речи, скорее для исследовательских. Читатель, заинтересованный лишь в прикладных моделях представления речевого сигнала, сможет подчерпнуть для себя информацию в нашей следующей статье.
Пример работы нейросети после обучения на базе лиц знаменитостей. Слева — исходный набор изображений 8×8 пикселей на входе нейросети, в центре — результат интерполяции до 32×32 пикселей по предсказанию модели. Справа — реальные фотографии лиц знаменитостей, уменьшенные до 32×32, с которых были получены образцы для левой колонки
Можно ли повышать разрешение фотографий до бесконечности? Можно ли генерировать правдоподобные картины на основе 64 пикселей? Логика подсказывает, что это невозможно. Новая нейросеть от Google Brain считает иначе. Она действительно повышает разрешение фотографий до невероятного уровня.
Такое «сверхповышение» разрешения не является восстановлением исходного изображения по копии низкого разрешения. Это синтез правдоподобной фотографии, которая вероятно могла быть исходным изображением. Это вероятностный процесс.
Английский стартап Magic Pony Technologyутверждает, что разработал революционную технологию «моделирования» изображений, которая значительно повышает разрешение фотографий и видео в реальном времени.
Обученная нейросеть не просто интерполирует пиксели, а добавляет недостающие детали. Разработчики говорят, что так можно автоматически генерировать элементы для реалистичных виртуальных миров, например.
Доброго времени суток, хабравчане. Сегодня мы будем создавать хранилище данных с функцией одностороннего связывания данных с использованием Proxy и некоторых других плюшек ECMAScript 2015.
Что же такое Proxy?
Проще говоря, прокси — это обертка объект, который позволяет перехватывать обращение к объекту, на основании которого он был создан. Для перехвата обращений прокси вооружен арсеналом ловушек имеет несколько функций перехватчиков. Полную информацию о списке перехватчиков и всех методах Proxy можно найти здесь.
Что мы будем делать?
Мы реализуем хранилище объектов с функционалом отслеживания изменений, используя прокси, т.е. некое подобие почившего O.o с некоторыми дополнительными плюшками.
Прочитав недавний топик про использование C++ и fastcgi, я наконец-то решился опубликовать свои наработки на тему Web и C++.
Существующие решения, с моей точки зрения, реализуют простые вещи сложным образом. Моей целью было устранить это досадное недоразумение, написав библиотеку, которая позволит писать эффективные кросс-платформенные веб-приложения на С++ так же легко и быстро, как и на PHP, Python, Java, и т.д.
В данном списке перечислены шрифты, общие для всех актуальных на данный момент операционных систем Windows (фактически начиная с Windows 98), и их эквиваленты в Mac OS. Такие шрифты иногда называют «безопасными шрифтами для браузеров» (browser safe fonts). Это небольшой справочник, которым я пользуюсь, когда делаю Web-страницы и думаю, что он будет полезен и Вам.
«Интересно, как выглядит мой сайт, когда я анонимный?» [1]
Лучше избегать посещения персональных сайтов, к которым прикреплены реальные имена или псевдонимы, особенно если к ним когда-либо подключались не через Tor / с реальным IP-адресом. Вероятно, очень немногие люди посещают ваш личный сайт через Tor. Это значит, что пользователь может быть единственным уникальным клиентом Tor, который сделает это.
Такое поведение ведёт к утечке анонимности, поскольку после посещения веб-сайта вся схема Tor становится «грязной». Если сайт малопопулярен и не получает много трафика, то выходные узлы Tor могут быть почти уверены, что посетитель этого сайта — владелец сайта. С этого момента разумно предположить, что последующие соединения с этого выходного узла Tor тоже идут с компьютера этого пользователя.
Современный квадро (гекса, окто) коптер — это достаточно мощное «вычислительное» устройство, способное управляться со смартфона по WiFi, зависать в одной точке, летать по маршруту и пр. Купить такой аппарат сейчас может любой желающий. А с чего все начиналось?
Как летает квадрокоптер?
Чтобы понимать суть технических решений, разберемся немного как вообще квадрокоптер летает. По сути, квадрокоптер — это неустойчивая система. Если взять 4 мотора, и просто подключить их к батарейке, квадрокоптер никуда не полетит, он просто перевернется т.к. сила тяги моторов никогда не будет идентичной. И тут вступает в действие электроника. На борту квадрокоптера есть центральная «плата управления», ключевой частью которой является блок датчиков. В простейшем случае, это трехосевой гироскоп. Микроконтроллер постоянно считывает данные с гироскопов, и как только гироскоп «чувствует» наклон по какой-либо оси, контроллер дает соответствующему двигателю команду чуть-чуть увеличить или уменьшить обороты, чтобы компенсировать наклон. В общем-то и вся логика — за исключением кучи всего (ПИД-регуляторов, теории управления, фильтров Калмана), ничего сложного тут нет (шутка). Ну а для пользователя все действительно прозрачно. Никаких движущихся частей кроме моторов, в квадрокоптере нет, все управление происходит исключительно изменением вращения оборотов моторов (с поворотами аналогично — изменяем скорости вращения, получаем вращающий момент). А теперь вернемся к истории.
Кладбище мессенджеров, на котором обязательно должны оказаться Skype, Viber, WhatsApp, Hangouts, ooVoo, Apple iMessage, Telegram, Line, Facebook messenger и еще сотни мессенджеров, которым только предстоит выйти в ближайшее время.
На написание этого текста меня подтолкнула ужасающая ситуация, сложившаяся в области интернет-коммуникаций, угрожающая перспектива развития инструментов для обмена мгновенными сообщениями, аудио-видеозвонками и надоевшие споры о том, какой же мессенджер все-таки хороший, правильный и безопасный.
Последние годы конкуренция на рынке мессенджеров как никогда высока. Доступный интернет у каждого в смартфоне позволил мессенджерам стать самыми часто используемыми приложениями. Только ленивый сейчас не пишет свой мессенджер. Каждый день выходит новое приложение, обещающее совершить революцию в способах коммуникации. Доходит даже до абсурда вроде приложения Yo, позволяющего слать друг другу только одно слово. У каждого мессенджера есть своя аудитория, агитирующая пользоваться именно их любимым сервисом. В итоге приходится заводить кучу учетных записей в различных сервисах и устанавливать кучу приложений, чтобы иметь возможность оперативно связаться со всеми необходимыми людьми.
Сложившаяся на данный момент ситуация настолько ужасна, что в перспективе угрожает фундаментальным принципам общения. В данной статье я на конкретных примерах попытаюсь донести одну мысль:
_ Почему такая важная для человечества технология, как мгновенные сообщения и аудио-видеозвонки, не может быть монополизирована какой-либо компанией. Как это тормозит развитие технологий, угрожает свободе и безопасности коммуникаций.
Специалисты из немецкой компании Recurity Labs разработали JavaScript-реализацию стандарта OpenPGP (RFC 4880) для подписи и шифрования писем в почтовых веб-интерфейсах. Таким образом, PGP-криптография доступна прямо в браузере без установки дополнительного софта.
Модуль GPG4Browsers реализован в качестве расширения для Google Chrome и работает только с Gmail, но не должно стать проблемой переделать его для другого браузера и/или почтового сервиса, ведь исходные коды открыты.
— Здравствуйте, это вам из ФСБ звонят. — Я знаю. — Откуда? — Вы мне на выключенный мобильник дозвонились.
Какой самый защищенный телефон?
Вот какие телефоны последние 2 недели стали жителями моего рюкзака. Знающие люди сразу поймут, что это за две трубки слева.
Чем больше я копал, тем печальнее мне становилось. Каждый (второй?) человек на Земле носит с собой жучок и за просто так отдает всю свою коммуникацию на блюдечке третьим лицам. И никто об этом не парится кроме профессиональных параноиков.
При том, что телефонов на планете больше, чем всех других устройств вместе взятых (немного загнул, но почти так), материалов катастрофически мало. Например, я до сих пор толком не нашел описаний тех команд оператора, которые скрытно включают телефон на прослушку. Или как операторы и органы борются (и борются ли) со скремблерами?
Почему нет хакерских/опенсорсных проектов телефонов? Вон, ноутбук запилили, чем мобильник сложнее? (Хотя вот тут есть кой-какие обсуждения).
Давайте на секунду задумаемся, как бы выглядел хакерский телефон? Какие бы функции у него были, чем он был бы нафарширован из железа и из ПО. А пока посмотрим, что есть на рынке, какие штучные решения уже реализованы, что можно у них подсмотреть.
Фантастические книги и фильмы могут удивить и дать больше информации о мире будущего, чем реальные научные открытия. Да и сами открытия в наше время редко вызывают общественный шок. Подсознательно мы готовы практически ко всему — нарисованный в сознании облик грядущего лишь получает подтверждение.
В голове есть персональная машина времени, столетиями формируемая искусством. На слуху остаются сбывшиеся прогнозы классиков фантастики, начиная с эпохи Герберта Уэллса. Но фантастическое описание объектов будущего остается игрой с воображением. Художественные приемы литературы позволяют представить даже объекты, под которыми автор, быть может, имел ввиду совсем иное — опыт современного человека подскажет недостающие фрагменты.
Художники оказываются в наименее выгодном положении. Им нужно максимально точно проиллюстрировать фантастическую идею, иначе магия предсказания не сработает. Картина намертво фиксирует труд воображения. Тем интереснее узнать, какие полотна не играют со зрителем в «угадайку», а визуально правильно отражают грядущее.
Давайте посмотрим на самые удивительные работы, предсказывающие будущее с поразительной точностью.
Практика показывает, что если тире или кавычки — это первое, что изучают при появлении интереса к «типографике» (а на самом деле — к грамотному набору текста), то правильное употребление апостро́фа, знаков минут и секунд, знака ударения вызывает почему-то бо́льшие затруднения. На самом деле, всё очень просто, и статья будет довольно короткой. Всё, о чём будет сказано ниже, относится к современной русской традиции типографики.
Веб-технологии прочно вошли в нашу повседневную жизнь. Мы проводим во всемирной паутине достаточно большое количество времени — смотрим новости, совершаем покупки, общаемся и работаем. Индустрия услуг и развлечений в сети Интернет стремительно развивается, ведущие разработчики программного обеспечения улучшают поддержку трехмерной графики в своих продуктах. Традиционно ее поддержка ограничивалась высокопроизводительными компьютерами или специализированными игровыми консолями, а программирование требовало применения сложных алгоритмов. Однако благодаря росту производительности персональных компьютеров и расширению возможностей браузеров стало возможным создание и отображение трехмерной графики с применением веб-технологий.
В отличие от других технологий для работы с трехмерной графикой (таких как OpenGL и Direct3D), WebGL предназначена для использования в веб-страницах и не требует установки специализированных расширений или библиотек. Одно из преимуществ WebGL — приложения конструируются как веб-страницы, то есть одна и та же программа будет успешно выполняться на самых разных устройствах (к примеру, на смартфонах, планшетных компьютерах и игровых консолях). Это означает, что WebGL будет оказывать все более усиливающееся влияние на сообщество разработчиков и станет одним из основных инструментов программирования графики.
Это перевод обзора статьи «Gorilla: A fast, scalable, in-memory time series database» Pelkonen et al. VLDB 2015
Чуваки из фейсбука сделали высокопроизводительный движок для мониторинговых данных. Мне понравился обзор этой статьи в блоге "The morning paper" — особенно про алгоритмы сжатия, и вот перевод.
Стиль — авторский.
Количество ошибок на одном из серверов Facebook зашкаливало.
Сидя на пятичасовом занятии по химии, я часто скользил взглядом по таблице Менделеева, висящей на стене. Чтобы скоротать время, я начал искать слова, которые мог бы написать, используя лишь обозначения элементов из таблицы. Например: ScAlEs, FeArS, ErAsURe, WAsTe, PoInTlEsSnEsS, MoISTeN, SAlMoN, PuFFInEsS.
Затем я подумал, какое самое длинное слово можно составить (мне удалось подобрать TiNTiNNaBULaTiONS), поэтому я решил написать программу на Python, которая искала бы слова, состоящие из обозначений химических элементов. Она должна была получать слово и возвращать все его возможные варианты преобразования в наборы химических элементов:
Это перевод поста Don't Starve, Diablo — Parallax 7 из блога Simon Schreibt от 25 февраля 2014 года. Осторожно, тяжелые гифки.
В 90-х игры начали свое движение от 2D к 3D. Если бы НЛО тогда посетило землю, пришельцы решили бы, что используемые в то время низкополигональные модели без всякой фильтрации никому не нужны, и уничтожили бы Землю.
Со временем они, конечно, научились бы тому, что делало людей особенными: даже в эру 2D у них было невероятное желание рендерить в 3D, даже при том, что тогда это было просто невозможно!
10 лекций (Youtube-канал), подробное описание каждой темы – в этой статье
воспроизводимых материалов (Jupyter notebooks) в репозитории mlcourse.ai
отличных соревнований Kaggle Inclass (не на "стаканье xgboost-ов", а на построение признаков)
домашних заданий по каждой теме (в репозитории — список демо-версий заданий)
мотивирующего рейтинга, обилия живого общения и быстрой обратной связи от авторов
UPD: теперь курс — на английском языке под брендом mlcourse.ai со статьями на Medium, а материалами — на Kaggle (Dataset) и на GitHub.
Следующий запуск курса – 1 октября 2018 года на английском языке (ссылка на опрос для участия, заполняйте на английском). Следите за объявлениями в группе ВК, вступайте в сообщество OpenDataScience.
Всем привет! Настало время пополнить наш с вами алгоритмический арсенал.
Сегодня мы основательно разберем один из наиболее популярных и применяемых на практике алгоритмов машинного обучения — градиентный бустинг. О том, откуда у бустинга растут корни и что на самом деле творится под капотом алгоритма — в нашем красочном путешествии в мир бустинга под катом.
UPD: теперь курс — на английском языке под брендом mlcourse.ai со статьями на Medium, а материалами — на Kaggle (Dataset) и на GitHub.
Видеозапись лекции по мотивам этой статьи в рамках второго запуска открытого курса (сентябрь-ноябрь 2017).
В HTML 5 есть много новых возможностей, которые позволяют web разработчикам создавать более мощные и насыщенные приложения. К этим возможностям относятся и новые способы хранения данных на клиенте, такие как web storage(поддерживается в IE8) и web SQL database.
При этом если web storage ориентирован на хранение пар ключ-значение, то в случае с web SQL database у нас есть полноценный sqlite(во всех текущих реализациях применяется именно этот движок баз данных, что является проблемой при стандартизации).
Далее я расскажу, как работать с web SQL database. При этом примеры естественно будут на JavaScript. Кроме того, стоит отметить, что с поддержкой браузерами всего этого хозяйства дела обстоят, не очень хорошо, но всё постепенно меняется к лучшему и, скажем, в Opera 10.50 поддержка будет, а браузерах на движке WebKit она уже есть. Более подробно про то, какой браузер, что поддерживает можно узнать, пройдя по ссылке.
Соединение с базой данных.
Подсоединиться к базе данных очень просто:
db = openDatabase("ToDo", "0.1", "A list of to do items.", 200000);
На Хабре уже рассказывали про IndexedDB — стандарт хранения больших структурированных данных на клиенте. Но это было давно и API сильно изменился. Несмотря на это в поиске статья всплывает одной из первых и вводит в заблуждение многих, кто начинает пытатся работать с этой технологией. Поэтому я решил написать новую статью с информацией об актуальном API.
Хей, привет. 2017 год на дворе. Даже простенькие мобильные и браузерные приложения начинают потихоньку рисовать физически корректное освещение. Интернет пестрит кучей статей и готовых шейдеров. И кажется, что это должно быть так просто тоже обмазаться PBR… Или нет?
В действительности же честный PBR сделать достаточно сложно, потому что легко достичь похожего результата, но сложно правильного. И в интернете полно статей, которые делают именно похожий результат, вместо правильного. Отделить мух от котлет в этом хаосе становится сложно. Поэтому цель статьи не только разобраться, что же такое PBR и как он работает, но и научиться писать его. Как отлаживать, куда смотреть, и какие ошибки типично можно допустить. Статья рассчитана на людей, которые в достаточной мере уже знают hlsl и неплохо знакомы с линейной алгеброй, и можете написать свой простейший неPBR Phong свет. В общем я постараюсь как можно проще объяснить, но рассчитываю на то, что некоторый опыт работы с шейдерами вы уже имеете.
Крупнейшие державы реализовали уже несколько программ, предполагающих долговременное пребывание человека на борту космических аппаратов. Пятнадцать лет вокруг Земли вращается Международная космическая станция. Но можно ли такие проекты назвать полноценным поселением? Люди способны прожить в условиях микрогравитации и тяжёлых психических нагрузок год, но станции не приспособлены для постоянной жизни с точки зрения здоровья экипажа, а о рождении детей и речи пока не идёт. Станции не полностью автономны, им необходим постоянный приток грузов с Земли.
Чтобы создать настоящее космическое поселение, необходимо разработать внутренние системы обеспечения и защиту от радиации и инородных объектов, создать искусственную силу тяжести. На нынешнем уровне развития технологий это будет стоить огромного количества ресурсов.
Давайте рассмотрим, как учёные и фантасты прошлого представляли себе такие поселения, и какие проекты в ближайшем будущем человечество может реализовать.
Добро пожаловать во вторую часть руководства по нейронным сетям. Сразу хочу принести извинения всем кто ждал вторую часть намного раньше. По определенным причинам мне пришлось отложить ее написание. На самом деле я не ожидал, что у первой статьи будет такой спрос и что так много людей заинтересует данная тема. Взяв во внимание ваши комментарии, я постараюсь предоставить вам как можно больше информации и в то же время сохранить максимально понятный способ ее изложения. В данной статье, я буду рассказывать о способах обучения/тренировки нейросетей (в частности метод обратного распространения) и если вы, по каким-либо причинам, еще не прочитали первую часть, настоятельно рекомендую начать с нее. В процессе написания этой статьи, я хотел также рассказать о других видах нейросетей и методах тренировки, однако, начав писать про них, я понял что это пойдет вразрез с моим методом изложения. Я понимаю, что вам не терпится получить как можно больше информации, однако эти темы очень обширны и требуют детального анализа, а моей основной задачей является не написать очередную статью с поверхностным объяснением, а донести до вас каждый аспект затронутой темы и сделать статью максимально легкой в освоении. Спешу расстроить любителей “покодить”, так как я все еще не буду прибегать к использованию языка программирования и буду объяснять все “на пальцах”. Достаточно вступления, давайте теперь продолжим изучение нейросетей.
Привет всем читателям Habrahabr, в этой статье я хочу поделиться с Вами моим опытом в изучении нейронных сетей и, как следствие, их реализации, с помощью языка программирования Java, на платформе Android. Мое знакомство с нейронными сетями произошло, когда вышло приложение Prisma. Оно обрабатывает любую фотографию, с помощью нейронных сетей, и воспроизводит ее с нуля, используя выбранный стиль. Заинтересовавшись этим, я бросился искать статьи и «туториалы», в первую очередь, на Хабре. И к моему великому удивлению, я не нашел ни одну статью, которая четко и поэтапно расписывала алгоритм работы нейронных сетей. Информация была разрознена и в ней отсутствовали ключевые моменты. Также, большинство авторов бросается показывать код на том или ином языке программирования, не прибегая к детальным объяснениям.
Поэтому сейчас, когда я достаточно хорошо освоил нейронные сети и нашел огромное количество информации с разных иностранных порталов, я хотел бы поделиться этим с людьми в серии публикаций, где я соберу всю информацию, которая потребуется вам, если вы только начинаете знакомство с нейронными сетями. В этой статье, я не буду делать сильный акцент на Java и буду объяснять все на примерах, чтобы вы сами смогли перенести это на любой, нужный вам язык программирования. В последующих статьях, я расскажу о своем приложении, написанном под андроид, которое предсказывает движение акций или валюты. Иными словами, всех желающих окунуться в мир нейронных сетей и жаждущих простого и доступного изложения информации или просто тех, кто что-то не понял и хочет подтянуть, добро пожаловать под кат.
Вместе с HTML5 в веб-разработку приходят новые API, расширяющие UX, привнося новые мультимедийные возможности и возможности взаимодействия в реальном времени. Зачастую этот функционал завязан на использование бинарных форматов файлов вроде MP3-аудио, PNG-изображений или MP4-видео. Использование бинарных файлов крайне важно в данном контексте, так как позволяет уменьшить требования к ширине канала, добиться необходимой производительности и вместе с этим оставаться совместимым с имеющимися технологиями. Еще недавно у веб-разработчиков не было прямого доступа к содержимому этих бинарных файлов или любых других бинарных форматов файлов.
В этой статье мы рассмотрим, как веб-разработчики могут снять этот барьер, используя Typed Arrays API для JavaScript, и использование нового API в демонстрационном примере Binary File Inspector на IE Test Drive.
Google уже демонстрировала, как нейросеть создаёт картины в стиле Ван Гога и Пикассо, но такой метод не подходит для видео: результат покадрового изменения фильма будет сложно склеить. Немецкие учёные справились с этой проблемой — их нейросеть распознаёт объекты в кадре, запоминает их и использует один и тот же стиль для отрисовки, когда они появляются снова.
Переработка кадров из фильма «Ледниковый период» в стиле «Звёздной ночи» Ван Гога
Компания Google недавно показала, как нейросеть может самостоятельно создавать произведения искусства. Попросту говоря, рисовать картины, утрируя существующие изображения.
Новый эксперимент, проведённый в университете Тюбингена (Германия) демонстрирует альтернативный алгоритм для нейросети: она правдоподобно подделывает художественный стиль Винсента Ван Гога, Пабло Пикассо, Эдварда Мунка и любых других художников. На вход для обработки подходят любые изображения.
Если вы когда-нибудь сталкивались с задачей ресайза картинок в браузере, то вы наверное знаете, что это очень просто. В любом современном браузере есть такой элемент, как холст (<canvas>). На него можно нанести изображение нужных размеров. Пять строчек кода и картинка готова:
Из холста картинку можно сохранить в JPEG и, например, отправить на сервер. Можно было на этом закончить статью, но сперва давайте взглянем на результат. Если вы поставите рядом такой холст и обычный элемент <img>, в который загружена та же картинка (исходник, 4 Мб), то вы увидите разницу.
Не так давно промелькнула ссылка на достаточно свежее (осень 2011) англоязычное голосование со скромным названием "самая впечатляющая книга, которую должен прочесть каждый разработчик программного обеспечения" и описанием:
Если бы вы могли вернуться в прошлое, к самому началу своей карьеры разработчика и сказать самому себе: «прочитай именно эту книгу», в самой начале своей карьеры разработчика, какую бы книгу вы рекомендовали?
Тема перевода зарубежной профессиональной IT-литературы стоит достаточно остро, многие любят читать книги в оригинале по различным причинам, таким так время выхода русского перевода с запозданием на годы, недостаточный профессионализм переводчика и соответствующая потеря тонкостей и авторского стиля и т.д.
Однако в данном небольшом посте я возьму на себя смелость перечислить ТОП-5 тех самых книг, победивших в голосовании, переведенных на русский язык. И дать небольшие комментарии, ведь книги действительно этого достойны. Да, лично я бы поменял некоторые места, однако положимся на «мнение зала» ресурса Stack Overflow.
Наталия Ефремова погружает публику в специфику практического использования нейросетей. Это — расшифровка доклада Highload++.
Добрый день, меня зовут Наталия Ефремова, и я research scientist в компании NtechLab. Сегодня я буду рассказывать про виды нейронных сетей и их применение.
Сначала скажу пару слов о нашей компании. Компания новая, может быть многие из вас еще не знают, чем мы занимаемся. В прошлом году мы выиграли состязание MegaFace. Это международное состязание по распознаванию лиц. В этом же году была открыта наша компания, то есть мы на рынке уже около года, даже чуть больше. Соответственно, мы одна из лидирующих компаний в распознавании лиц и обработке биометрических изображений.
Первая часть моего доклада будет направлена тем, кто незнаком с нейронными сетями. Я занимаюсь непосредственно deep learning. В этой области я работаю более 10 лет. Хотя она появилась чуть меньше, чем десятилетие назад, раньше были некие зачатки нейронных сетей, которые были похожи на систему deep learning.
Под влиянием пользователей-людей самообучающийся бот стал расистом всего за день. Бота пришлось отключить
Практически все техно-корпорации так либо иначе участвуют в разработке ИИ. Самообучающиеся автомобили с компьютерной системой управления, голосовые помощники или боты для Twitter. Корпорация Microsoft на днях представила своего бота для Twitter, способного самообучаться и ведущего себя, как подросток. Жаргонные словечки, стиль общения — все это практически не отличается от общения англоязычных подростков в Сети.
Бот-подросток стал активно использовать особенные словечки и сокращения: часть была внесена в его БД сразу, часть — попала в ходе обучения. Пользователи Twitter сразу же начали общаться с ботом, и не всегда вопросы или ответы людей были корректными или толерантными. Бот, можно сказать, попал в плохую компанию. Настолько плохую, что он быстро научился говорить нехорошие вещи, и Microsoft пришлось отключить своего «подростка» через сутки после анонса. И это при том, что за тем, как общается бот, следила целая команда людей-модераторов, которые пытались фильтровать входящий поток информации.
Сравнение программы RAISR с другими передовыми методами повышения разрешения изображений. Больше примеров см. в сопроводительных материалах к научной статье
Повышение разрешения изображений, то есть создание фото высокого разрешения на основе одного фото низкого разрешения — очень хорошо изученная научная проблема. Она важна для многих приложений: зуммирование фото и текста, проекция видео на большой экран и т.д. Даже в фильмах детективы иногда умудряются рассмотреть номер автомобиля на кадре с камеры наблюдения, «приблизив» фотографию до предела. И не только номер автомобиля. Тут всё ограничено фантазией и совестью режиссёра и сценариста. Они могут приблизить фотографию ещё больше — и разглядеть отражение преступника в зеркале заднего вида или даже в отполированной металлической головке болта, которым крепится номерной знак. Зрителям такое нравится.
Зачем кому-то захочется создавать дороги в олдскульном стиле сегодня, когда каждый компьютер может на лету отрисовывать графику, состоящую из миллионов полигонов? Разве полигоны — не то же самое, только лучше? На самом деле нет. Полигоны действительно создают меньше искажений, но именно деформации в старых игровых движках дают такое сюрреалистическое, головокружительное чувство скорости, ощущаемое во многих дополигональных играх. Представьте, что область видимости управляется камерой. При движении по кривой в игре, использующей один из таких движков, похоже, что она заглядывает на кривую. Затем, когда дорога становится прямой, вид тоже выпрямляется. При движении в повороте с плохим обзором камера как будто заглядывает за выступ. И поскольку в таких играх не используется традиционный формат трасс с точными пространственными соотношениями, то можно без проблем создавать трассы, на которых игрок будет ездить с захватывающей дух скоростью. При этом не нужно беспокоиться о том, что объекты появляются на трассе быстрее, чем может среагировать игрок, потому что физическую реальность игры можно легко изменять в соответствии со стилем геймплея.
Но в такой системе есть и множество недостатков. Глубина физики, используемой в играх-симуляторах, будет утеряна, поэтому такие движки не приспособлены для этих игр. Однако они просты в реализации, быстро работают, а игры на их основе обычно очень интересны!
Стоит заметить, что не в каждой старой гоночной игре используются эти техники. В действительности описываемый в статье метод — это только один из способов создания псевдотрёхмерной дороги. В других случаях используются спроецированные и отмасштабированные спрайты или различные способы реального проецирования дороги. Степень смешения реальной математики с трюками зависит от создателей. Надеюсь, вам понравится изучение предложенного мной спецэффекта.
Я думаю каждый хоть раз слышал о стеганографии. Стеганография (τεγανός — скрытый + γράφω — пишу, дословно «скрытопись») — это междисциплинарная наука и искусство передавать сокрытые данные, внутри других, не сокрытых данных. Скрываемые данные обычно называют стегосообщением, а данные, внутри которых находится стегосообщение называют контейнером.
Стеганографических способов бесчисленное множество. На момент написания данной статьи в США уже опубликовано не менее 95 патентов по стеганографии, а в России не менее 29 патентов. Более всего мне понравился патент Kursh К. и Lav R. Varchney«Продовольственной стеганографии» («Food steganography», PDF)
Картинка из «пищевого» патента для привлечения внимания:
Тем не менее, прочитав приличное количество статей и работ, посвященных стеганографии, я захотел систематизировать свои идеи и знания в данной области. Данная статья сугубо теоретическая и я хотел бы обсудить следующие вопросы:
Цели стеганографии — на самом деле их три, а не одна.
Практическое применение стеганографии — я насчитал 15.
Место стеганографии в XXI веке — я считаю, что с технической точки зрения современный мир уже подготовлен, но «социально» стеганография пока «запаздывает».
Я постарался обобщить мои исследования по данному вопросу. (Это значит, что текста много) Надеюсь на разумную критику и советы со стороны хабросообщества.
Обсуждение анонимности нужно начинать не со слов прокси/тор/впн, а с определения задачи: анонимно подключиться к чужому серверу по SSH это одно, анонимно поднять свой веб-сайт это другое, анонимно работать в инете это третье, etc. — и все эти задачи решаются по-разному. Эта статья о задаче «анонимно работать в интернете как пользователь».
В последнее время на хабре появилось много статей на тему обеспечения анонимности в интернете, но они все описывают подход «немножко анонимен». Быть «немножко анонимным» практически бессмысленно, но, судя по комментариям к этим статьям, многие этого не понимают.
Во-первых, нужно адекватно оценивать потенциального противника. Если вы хотите быть «анонимным», значит вы пытаетесь избежать возможности связывания вашей активности в интернете с вашим физическим расположением и/или настоящим именем. Обычные пользователи и так не имеют возможности вас отслеживать (технически, социальные методы когда по вашему нику на форуме легко гуглится ваш аккаунт в соц.сетях со всеми личными данными мы здесь не рассматриваем). Ваш провайдер/соседи могут иметь возможность прослушать большую часть вашего трафика, но, как правило, вы им не интересны (да, соседи могут украсть ваши пароли, но заниматься отслеживанием вашей активности или вашей деанонимизацией они не станут). Что же касается владельцев используемых вами ресурсов (веб-сайтов, прокси/vpn-серверов, etc.) то у них в распоряжении множество средств по отслеживаю вас (DNS-leaks, Flash/Java-плагины, баннерные сети, «отпечатки браузера», множество разных видов кук, etc.) плюс серьёзный коммерческий интерес к тому, чтобы надёжно вас отслеживать (для таргетирования рекламы, продажи данных, etc.). Ну а правительство и спец.службы могут получить доступ и к данным, которые на вас собирают веб-сайты, и к данным, которые собирают провайдеры. Таким образом получается, что те, кто имеют возможность и желание вас отслеживать — имеют доступ к большинству возможных каналов утечки.
Во-вторых, каналов утечки информации очень и очень много. И они очень разнообразны (от внезапно отключившегося VPN до получения реального IP через Flash/Java-плагины браузера или отправки серийника на свой сервер каким-нить приложением при попытке обновления). Более того, регулярно обнаруживаются (и создаются) новые. Поэтому попытка блокировать каждый из них в индивидуальном порядке, уникальными для каждого методами, просто не имеет смысла, всё-равно что-то где-то протечёт.
В-третьих, при «работе в интернете» используется не только браузер — большинство пользуются так же IM, торрентами, почтой, SSH, FTP, IRC… при этом часто информация передаваемая по этим каналам пересекается и позволяет их связать между собой (.torrent-файл скачанный с сайта под вашим аккаунтом грузится в torrent клиент, ссылка пришедшая в письме/IM/IRC открывается в браузере, etc.). Добавьте сюда то, что ваша ОС и приложения тоже регулярно лазят в инет по своим делам, передавая при этом кучу деанонимизирующей вас информации…
Из всего этого логически следует то, что пытаться добавить «немножко анонимности» путём использования браузера со встроенным Tor, или настройкой торрент-клиента на работу через SOCKS — нет смысла. Большинство вас не сможет отследить и без этих мер, а тех, кто имеет возможности и желание вас отследить эти меры не остановят (максимум — немного усложнят/замедлят их работу).
Возможно, кто-то помнит замечательную олдскульную космическую игру Star Control 2. В свое время меня поразила огромная звездная карта с неизведанными планетами, которые предстояло исследовать на фоне разворачивающейся глобальной катастрофы. С тех пор как авторами были опубликованы исходные коды, игра была портирована под новым именем The Ur-Quan Masters на большинство современных платформ.
Покопавшись в исходниках, я обнаружил простой алгоритм, генерирующий текстуры планет, и написал программу на Python, позволяющую генерировать аналогичные текстуры.
Предлагаю подборку всегда актуальных книг по программированию, геймдизайну и концепт-арту для новичков и бывалых бойцов геймдева. Конечно, во главе профессионального развития стоит практика, но эти книги сэкономят ваше время и позволят не выдумывать велосипед заново.
Сейчас доступно огромное количество отличных бесплатных инструментов. Но используя бесплатный или условно-бесплатный инструмент, вам понадобится больше времени на достижение своей цели, потому что такой инструмент не будет полностью соответствовать вашим потребностям.
С другой стороны, в начале пути важно минимизировать издержки и внимательно следить за своими платными подписками. В конце месяца они могут незаметно вылиться в огромные накладные расходы.
Итак, мы нашли в интернете бесплатные и условно-бесплатные инструменты для роста вашего бизнеса. Когда они дадут вам желаемый результат, вы можете оформить платную подписку.
Недавняя публикация о том, как Valve обучает ИИ выявлять читеров в CS:GO, а так же вопросы пользователей, навели меня на мысль о том, что подобная публикация может быть интересна для ознакомления с некоторыми сторонами читерства и функционала читов. Мне никогда не приходило в голову писать об этом статью, так как я не имею отношения к программированию, и вообще работаю в другой сфере. Однако данную тему я посчитал достаточно интересной, чтобы рассказать о ней более подробно.
Реализацию порядко-независимой прозрачности (order-independent transparency, OIT), наверное, можно считать классической задачей программирования компьютерной графики. По сути, алгоритмы OIT решают одну простую прикладную задачу – как нарисовать набор полупрозрачных объектов так, чтобы не беспокоиться о порядке их рисования. Правила смешивания цветов при рендеринге требуют он нас, чтобы полупрозрачные объекты рисовались в порядке от дальнего к ближнему, однако этого сложно добиться в случае протяженных объектов или объектов сложной формы. Реализация одного из самых современных алгоритмов, OIT с использованием связных списков, была представлена AMD для Direct3D 11 еще в 2010 году. Скажу откровенно, производительность алгоритма на широко доступных графических картах тех лет не произвела на меня должного впечатления. Прошло 4 года, я откопал презентацию AMD и решил реализовать алгоритм не только на Direct3D 11, но и на OpenGL 4.3. Тех, кому интересно, что получилось из этой затеи, прошу под кат.
Привет, меня зовут Александер Бирке (Alexander Birke), недавно я выпустил свою первую игру в Steam под названием Laser Disco Defenders. Мне кажется, было бы интересно раскрыть некоторые технические и дизайнерские решения, вошедшие в игру. Начну с собственной системы освещения, позволяющей работать со множеством двухмерных источников света даже на слабых компьютерах. LDD создана в Unity, но этот подход сработает в любом другом игровом движке, позволяющем создавать процедурные сетки (meshes).
— Я тут воду для проекта запилил. — О, круто! А почему она плоская? Даёшь волны! … — Слушай, ты тогда про волны говорил, помнишь? Зацени! — Да, хорошие волны, а преломление и каустику ещё не делал? … — Привет, я тут игрался с Unity всю ночь, смотри какие отражения и каустику закодил! — Дарова, и правда, хорошо! А когда у тебя вода кипит, отражения не глючат? … — Хай, реализовал наконец, кипение, вроде ничего? — О, прямо как нужно! Слушай, прикинь как круто, если кипящую волну заморозить? … — Лови картинку, лёд вроде ничего придумал? — Норм, слушай, а у тебя лёд замерзает, он в объёме увеличивается? И кстати, ты когда геймлей то делать начнёшь? Вариации на тему лога с другом.
Да, вы уже поняли, наконец-то расскажу про реализацию воды в проекте. Приступим?
Глобальное освещение, динамический свет и декали (да, есть такое слово :) ) в действии.
Я очень люблю смотреть на белые предметы без текстуры. Недавно в художественном магазине я долго рассматривал гипсовые фигуры, которые художники используют в качестве модельных объектов. Очень приятно видеть все эти плавные переходы света и мягкие тени. Позже, когда я вернулся домой и открыл Unity3D, пришло понимание, что свет в моём проекте по-прежнему скучный и нереалистичный. С этого момента началась история глобального освещения, которую я сегодня расскажу.
Выпущенный в 1993 году первый DOOM внёс фундаментальные изменения в разработку игр и механик, он стал мировым хитом и создал новых идолов, таких как Джон Кармак и Джон Ромеро.
Сегодня, 23 года спустя, id Software принадлежит Zenimax, все основатели уже покинули компанию, но это не помешало коллективу id продемонстрировать весь свой талант, выпустив отличную игру.
Давненько я не писал на хабр: учеба, сессия надвигается, сами понимаете. Сегодня я попробую рассказать, как в XNA реализовать Deferred Lighting (отложенное освещение) с использованием normal mapping на три источника света, при этом использовать мы будем Reach-профиль и Shader model 2.0. Напомню, раньше мы уже затрагивали тему шейдеров: тут. Остальное под катом, видео и демо там же.
Дискеты с исходным кодом Prince of Persia, случайно найденные отцом Джордана Мекнера за шкафом
Мусорные корзины, свалки и мусоросжигатели. Стирание, удаление и моральное устаревание. Этими словами можно описать процессы, происходящие со строительными кирпичиками индустрии видеоигр в разных странах мира. Такими кирпичиками бывают исходный код игр, компьютерное оборудование, использованное для создания конкретных видеоигр, схемы уровней, эскизы персонажей, производственные документы, маркетинговые материалы и многое другое.
Вот только некоторые элементы процесса создания игр, которые утеряны и никогда к нам не вернутся. Из таких элементов состоят игры для домашних и портативных консолей, ПК и аркадных автоматов, в которые вы играли. Единственным напоминанием об игре может остаться её название или финальная опубликованная версия, потому что существует вероятность исчезновения всех других физических копий результатов творчества.
Коллизии существуют для большинства хеш-функций, но для самых хороших из них количество коллизий близко к теоретическому минимуму. Например, за десять лет с момента изобретения SHA-1 не было известно ни об одном практическом способе генерации коллизий. Теперь такой есть. Сегодня первый алгоритм генерации коллизий для SHA-1 представили сотрудники компании Google и Центра математики и информатики в Амстердаме.
Вот доказательство: два документа PDF с разным содержимым, но одинаковыми цифровыми подписями SHA-1.
В далёком 2013м году вышла игра Tiny Thief, которая наделала много шуму в среде мобильной Flash (AIR) разработки из-за отказа от растровой графики в билдах, включая атласы анимации и прочего — всё что было в сборке хранилось в векторном формате прямиком из Flash редактора. Это позволило использовать огромное количество уникального контента и сохранить размер установочного файла до ~70 мегабайт (*.apk-файл из Google Play). Совсем недавно снова возник интерес к теме отрисовки векторной графики на мобильных устройствах (и вообще к теме отрисовки вектора с аппаратной поддержкой), и меня удивило отсутствие информации "начального" уровня по этой теме. Это обзорно-справочная статья по возможным способам отрисовки вектора и уже существующим решениям, а так же о том, как подобные вещи можно сделать самостоятельно.
Хочу рассказать о генераторе квестов, который я делаю для своей браузерной ZPG.
Несмотря на то, что вопрос автоматической генерации заданий в RPG достаточно древний, общедоступных работающих версий таких генераторов почти нет (скорее совсем нет), если не считать совсем примитивных вариантов. Работ по этой теме тоже не много, хотя, если активно гуглить, кое-что можно откопать. Поэтому надеюсь, что этот текст (и сам генератор, ссылка на репозиторий есть в конце статьи) будет полезен.
В нашем мире без JavaScript никуда! Куча фреймворков, библиотек и прочей радости! jQuery плотно вошел в нашу жизнь. React с Angular пробивают дорогу к светлому будущему. Да и не за горами поддержка браузерами ES6 без Babel.
Но если тема заходит об обычном сайте со стандартным функционалом, не редки случаи, когда JavaScript начинают “злоупотрелять”. И все, в принципе, нормально… Но порой задаешься вопросом: «А если без JavaScript?».
Год назад я увидела перевод Убийцы оптимизации, и была удивлена тем, сколько нужно держать в голове, чтобы писать оптимизированный js код. Особенно расстраивало, что практически весь es6 попадал под деоптимизацию.
И вот новый оптимизатор в v8, называемый TurboFan, за последний год научился оптимизировать этот самый практически весь es6, es5 и даже try-catch больше не является проблемой.
class TestClass {
megaFunc() {
try {
let sum = 0;
for (let val of [1, 2, 3]) {
sum += val;
}
throw new Error(`sync error, sum = ${sum}`);
}
catch(err) {
return err;
}
}
}
let test = new TestClass();
checkOptimizationStatus(test.megaFunc);
Function is optimized by TurboFan
Что осталось не оптимизированным, а так же как проверить свою функцию на предмет оптимизации или деоптимизации буквально в 1 действие можно увидеть под катом
Цифровой звук. Как же много мифов крутится вокруг этой фразы. Сколько споров возникало между любителями удобства и качества цифры и приверженцами «живого воздушного» винилового звука помноженного на «тёплое ламповое» звучание. Кроме того, есть немало споров и между любителями «цифры»: достаточно ли 16х44.1 или нужно 24х192? Что лучше: мультибит или дельта-сигма? CDDA или SACD? PCM или DSD? В этой статье я попробую простым языком изложить азы цифрового звука, а так же более подробно остановлюсь на сравнении двух типов кодирования аналогового сигнала в цифровой: DSD и PCM.
Конечно, многие скажут, что это ни-ни и писать для веба нужно только на PHP, ну или на один из модерных языках Питон, Руби, Node.js и т.д.
Но дело в том, что написание сайтов на ассемблере очень полезно, а с подходящими инструментами — легко и приятно.
Вообще-то, это утверждение было лишь гипотезой. Чтобы доказать или отвергнуть ее, этой весной я занялся писать форум на ассемблере.
Раньше у меня уже было веб-приложение на ассемблере — CMS для малого сайта. Только оно работает в режиме "один пишет, многие читают". При том, использует CGI интерфейс и поэтому "многие" читать одновременно тоже не получается.
Однако на практике случается довольно много случаев, когда использование онлайн-песочниц не позволяет решить задачу. Это может быть связано с самыми различными факторами, например:
— Доступ к интернет затруднителен — Онлайн-песочницы в данный момент перегружены, а выполнение анализа критично по времени — Выполнение в онлайн песочницах блокируется изучаемым файлом — Необходима более тонкая настройка режима выполнения файла при анализе, например — увеличение времени задержки с момента запуска
В этом случае на помощь нам приходит оффлайн-решение проблемы.
Словари – одно из самых древних и самых известных достижений мировой лингвистики. Но насколько распространённые представления о словарях соответствуют реальности? Кто составляет словари? Как это делалось прежде и что изменилось в новую, компьютерную эпоху? Всё ли знают словари – а если нет, то кто знает лучше их? Всегда ли стоит доверять словарям, можно ли обойтись совсем без них и что ждет словари в будущем?
Читает лекцию кандидат филологических наук Борис Леонидович Иомдин, старший научный сотрудник Института русского языка им. В. В. Виноградова РАН, доцент Института лингвистики РГГУ, доцент факультета филологии Высшей школы экономики.
Я работаю в команде семантического веба в Яндексе. Мы занимаемся тем, что создаем продукты на основе семантической разметки, делаем свои расширения и участвуем в развитии стандарта Schema.org.
Мир семантической разметки устроен не вполне просто и на первый взгляд даже не всегда логично. Для того чтобы облегчить жизнь тем, кто хочет в нём разобраться, мы решили написать рассказ о том, какой бывает разметка, что дает и как ее внедрить.
Под микроразметкой (или семантической разметкой) мы подразумеваем разметку страницы с дополнительными тегами и атрибутами в тегах, которые указывают поисковым роботам на то, о чем написано на странице.
В этом году исследователи из Google Brain опубликовали статью под названием Exploring the Limits of Language Modeling (Исследование границ языкового моделирования), в которой была описана языковая модель, позволившая значительно снизить перплексию (с примерно 50 до 30) на словаре One Billion Word Benchmark.
В этом посте мы расскажем про самый низкий уровень этой модели — представление символов.
Автоматический анализ текстов практически всегда связан с работой со словарями. Они используются для морфологического анализа, выделения персон (нужны словари личных имен и фамилий) и организаций, а также других объектов.
В общем виде словарь — множество записей вида {строка, данные ассоциированные с этой строкой}.
Например, для морфологического анализа словарь состоит из троек {словоформа, нормальная форма, морфологические характеристики}. При анализе слова «мыла» из предложения «мама мыла раму» надо уметь получать следующие варианты анализа:
Нормальная форма
Характеристики
МЫЛО
S (существительное), РОД (родительный падеж), ЕД (единственное число), СРЕД (средний род), НЕОД (неодушевленность)
МЫЛО
S (существительное), ИМ (именительный падеж), МН (множественное число), СРЕД (средний род), НЕОД (неодушевленность)
МЫЛО
S (существительное), ВИН (винительный падеж), МН (множественное число), СРЕД (средний род), НЕОД (неодушевленность)
Этот пост призван помочь тем, кому, как и мне, внезапно стало тесно с Movie Maker.
Видеоредакторы почти не интересовали меня до прошлого месяца, пока с друзьями мы не задумали снять что-нибудь оригинальное к Новому году. Креативность наша ограничилась тем, чтобы, говоря терминами прежде мне неизвестными, применить эффект “Разделение экрана” (Split Screen). То есть реализовать нечто такое:
Поисковый сервер Sphinx (sphinxsearch) позиционируется как система, весьма неплохо масштабируемая под высокие нагрузки и большие объёмы индексов. В целом это неплохо — но иногда под рукой нет машины с 16-ядерным процессором и 256Гб оперативки. А что делать, если ядро всего одно? А если и с объёмом памяти не очень? А если это не сервер и даже не средний PC, а вообще роутер на SoC, с далеко не самым быстрым «камнем», и где всего 32Мб оперативки, да и ту нужно делить с другими процессами и системой? Взлетит ли в таком случае поисковик? Будет ли работать? Оправдано ли? Да, взлетит. Да, будет работать. Да, вполне оправдано.
Вы заметили, что Фейсбук обрёл сверхъестественную способность распознавать ваших друзей на ваших фотографиях? В старые времена Фейсбук отмечал ваших друзей на фотографиях лишь после того, как вы щёлкали соответствующее изображение и вводили через клавиатуру имя вашего друга. Сейчас после вашей загрузки фотографии Фейсбук отмечает любого для вас, что похоже на волшебство:
Недавно передо мной встала задача обрезать около сотни огромных картинок из фотобанка под несколько десятков разных размеров. Эти готовые картинки потом будут использоваться клиентами CMS для оформления своих сайтов. Прикинув сколько времени займет этот процесс в Фотошопе, я пригорюнился — встретить следующий Новый год за обрезкой картинок не входит в мои планы.
В статье описываются мои безуспешные попытки убедить сотрудников Microsoft, что их сервис уязвим, а также унижения, которые приходится выносить пользователям Skype. Под катом невежество, боль и отчаяние.
Любой может заблокировать ваш аккаунт навсегда так, что вы больше не сможете им пользоваться. Для этого достаточно знать только имя аккаунта. В большинстве случаев Skype откажет вам в восстановлении доступа. Microsoft знает об этой проблеме несколько лет.
Механизм генерации восьмизначных одноразовых кодов аутентификации (Microsoft Security Code), которые используются для восстановления пароля к аккаунту Microsoft, уязвим. Атакующий может угадать код.
Техподдержка Skype уязвима для атак социальной инженерии. Microsoft считает это нормальным.
Техподдержка Skype не знает, что на самом деле происходит с вашим аккаунтом, и почему он заблокирован. В любом случае вы получите стандартный ответ, что ваш аккаунт заблокирован за нарушение правил, даже если аккаунт был удален по вашему запросу.
Skype по-прежнему раскрывает ваш IP-адрес, в том числе и локальный (тот, что на сетевом интерфейсе). В некоторых случаях возможно раскрытие контактов, подключенных с того же внешнего IP-адреса, что и вы. Например, членов семьи, подключенных к домашнему роутеру.
Атакующий может скрыть активную сессию из списка авторизованных клиентов (команда /showplaces) используя старые версии SDK. Таким образом, зная пароль, можно незаметно просматривать переписку жертвы.
Думаю, что не только я, но и другие пользователи Chrome под Windows, на многих сайтах замечали проблемы c отображением нестандартных шрифтов. Читать текст на таких сайтах можно, но глазам больно. Я бы так все это и продолжал терпеть, но на одном из недавних собственных проектов этот вопрос встал буквально ребром. Решил разобраться во всем досконально.
Разница в этих двух фрагментах очевидна. Первый сделан со случайно выбранного сайта adaptive-images, а второй с его локальной копии, в css которой была изменена буквально одна строчка.
(Читавшие первую версию статьи могут сразу перейти к UPD, где приведено работающее альтернативное решение проблемы для Chrome)
На многих сайтах есть возможность отобразить версию страницы для печати, но всегда ли удобно ими пользоваться?
Основными проблемами при распечатке документа становится плохая типографика, наличие лишней информации (например, элементы интерфейса) и неправильные цвета. Для стилизации можно использовать правило @media:
Месяц назад кто-то нашёл у меня на гитхабе незаконченный проект и выложил ссылку на него на Designer News. Внезапно я увидел, что на сайте проекта постоянно сидит по 50 человек, и мне даже пришлось срочно сбежать с работы чтоб экстренно выпилить хотя бы самые адовые баги. Этим проектом был интенс, UX-компонент заменяющий полосу прокрутки (скроллбар) на специальный индикатор, который подсвечивает прокручиваемую область текстурой. Выглядит это примерно так:
Спасибо, не надо. Никогда не мог понять это желание поменять стандартные элементы интерфейса. Полоса прокрутки — это одна из тех вещей, которая просто работает. Она не мешается и легко даёт понять, насколько много контента. — madk @ reddit
… Я не очень понял, что за проблему оно решает — jineshshah36 @ reddit
(кто-то даже создал сабреддит Real Bad UX чтоб разместить там ссылку на этот проект)
Вместе с UX-экспертами, возбудился и я. Бесполезные проекты обычно никому не интересны, у меня есть пара таких. Но сейчас было очень непохоже — этот получился очень спорным, и такой движухи я ещё не видел. В течение следующих недель я попытался учесть основные комментарии и либо исправить что-то в самой библиотеке, либо добавить пояснения на сайте проекта. И одновременно выкладывал его на остальных ресурсах — градус фидбэка вроде бы стал смягчаться.
Здесь я хочу рассказать, какие области применения у интенса, и попробую объяснить, как я себе представляю «жизнь после скроллбара». А также предлагаю читателям покритиковать этот проект, обсудить скроллинг вообще, UX вцелом, и целесообразность замены традиционных элементов в частности.
Первые узлы сети Фидонет на территории России появились в Новосибирске, их системными операторами были Владимир Лебедев и Евгений Чуприянов (известный под псевдонимом — Eric Fletcher). 21 сентября 1990 года эти узлы впервые объявились в чехословацком сегменте мирового ноудлиста:
На картинке: Ада Лавлейс, которая не только первая женщина-программист, но и вообще первый программист в истории. Родилась 10 декабря 1815 года.
Вы бы знали, сколько раз мне приходилось слышать фразы вроде «Ты ж девочка, зачем тебе это?» или «У женщин мозг к программированию не приспособлен». Столько раз мне говорили: «Мы тут будем делом заниматься, а ты — украшение команды». Ещё хуже, если «нужна, чтобы доску протереть». В то же самое время были бессонные ночи, месяцы без отрыва от компьютера, тонны сохранённых видео, закладок, курсов, статей, а главное — постоянное сражение с собой и окружающими ради Цели. И вот итог: мне 22 года, я менее года назад окончила университет, но уже успела поработать в главном офисе 2ГИС в Новосибирске, а потом получить работу в Mail.Ru Group. Меня зовут Дарья Пушкарская, и здесь я расскажу о цепи событий, которая привела меня к такому результату.
Думаю, все уже знают, что современные браузеры умеют рисовать некоторые части страницы на GPU. Особенно это заметно на анимациях. Например, анимация, сделанная с помощью CSS-свойства transform выглядит гораздо приятнее и плавнее, чем анимация, сделанная через top/left. Однако на вопрос «как правильно делать анимации на GPU?» обычно отвечают что-то вроде «используй transform: translateZ(0) или will-change: transform». Эти свойства уже стали чем-то вроде zoom: 1 для IE6 (если вы понимаете, о чём я ;) для подготовки слоя для анимации на GPU или композиции (compositing), как это предпочитают называть разработчики браузеров.
Однако очень часто анимации, которые красиво и плавно работали на простых демках, вдруг неожиданно начинают тормозить на готовом сайте, вызывают различные визуальные артефакты или, того хуже, приводят к крэшу браузера. Почему так происходит? Как с этим бороться? Давайте попробуем разобраться в этой статье.
Небольшая головоломка: перед вами синхронный код, загружающий и обрабатывающий содержимое 4 файлов, но с сервера они грузятся параллельно. Как такое может быть?
А теперь прошу за мной в кроличью нору, настало время удивительных историй...
Нейронные сети сейчас в тренде. Каждый день мы читаем про то, как они учатся писать комментарии в интернете, торговаться на рынках, обрабатывать фотографии. Список бесконечен. Когда я впервые посмотрел на масштаб кода, который приводит это в движение, я был напуган и хотел больше не видеть эти исходники.
Но врожденные любознательность и энтузиазм довели меня до того, что я стал одним из разработчиков Synaptic — проекта фреймворка для построения нейронных сетей на JS с 3к+ звезд на GitHub. Сейчас мы с автором фреймворка занимаемся созданием Synaptic 2.0 с ускорением на GPU и WebWorker-ах и с поддержкой почти всех основных фич любого приличного NN-фреймворка.
В итоге оказалось, что нейронные сети — это несложно, они работают на достаточно простых принципах, которые несложно понять и воспроизвести. Самая трудная задача — это обучение, но для этого почти всегда пользуются готовыми алгоритмами, а скопировать их не очень сложно. Доказать это просто. Ниже в статье реализация нейронной сети с нуля без каких-либо библиотек.
Гонка за объёмом предоставляемого облачного хранилища в Китае явно выходит на новый уровень: китайская компания Tencent предлагает всем зарегистрироваться и получить в итоге в своё распоряжение 10 Тб (терабайт) места на своём сервисе бесплатно. В этом смысле потуги Google или Dropbox действительно выглядят неважно — правда, всегда можно задаться вопросом о надёжности или приватности, хотя в этом смысле у Tencent вроде бы дела идут неплохо: она работает с 1998 года и её акции продаются на Гонконгской бирже…
Не обошлось без некоторых условий, которые, впрочем, действительно не трудно соблюсти — требуется зарегистрироваться с Tencent QQ-аккаунтом (получить его можно здесь) на странице акции и скачать мобильный клиент сервиса — доступны версии для Android и iOS. Сразу после этого в распоряжении пользователя оказывается 1 Тб облачного хранилища, который подходит для любых файлов (такой же объём на Flickr разрешают заполнять только фото и видео).
В дальнейшем по мере исчерпания свободного места сервис будет автоматически его увеличивать, пока верхняя планка не упрётся в заявленные 10 Тб в соответствии с приведённой ниже таблицей:
Насколько можно понять, что web-версии или десктопного клиента для сервиса нет, так что речь идёт именно о мобильном хранилище. Время акции также ограничено. UPD: Как подсказывают:
Хеди Ламарр (Hedy Lamarr) — популярная в 1930—1940-е годы австрийская, а затем американская актриса кино, а также изобретательница.
В 16 лет ушла из дома. Поступила в театральную школу, начала сниматься в кино.
В 23 года, после четырех лет неудачного брака, подсыпав снотворное горничной, сбегает. На пароходе «Нормандия» она отправляется из Лондона в Нью-Йорк.
Electronic Frontier Foundation присудили Ламарр в 1997 году награду (за изобретение почти 60-ти летней давности), а 49% прав на патент выкупила компания WiLan, в 2014 включили в Зал славы изобретателей.
9 ноября, день рождения Хеди Ламарр, в немецкоязычных странах отмечается как День изобретателя.
А вот история из жизни. Госэкзамен на военной кафедре ДВФУ, 2005 год.
Капитан первого ранга: — Рядовой MagisterLudi, вам последний вопрос. Ответите, значит сдали экзамен, но учтите, этой темы нет в вашем учебном плане. Как обеспечить связь между кораблем и базой, чтобы противник не смог заглушить частоту, на которой вы передаете сообщение? — Псевдослучайная перестройка частоты. — Сдал.
Капитан третьего ранга молча сделал фейспалм в углу аудитории, потому что последние полгода он заставлял меня и еще троих ребят прочесывать интернет на тему его кандидатской по ПСПЧ. Председатель комиссии, капитан первого ранга, естественно, этого не знал.
Калифорнийские ребята разработали интересный сервис Pixelapse, который позволяет загружать на сайт графические файлы (интеграция с Photoshop), автоматически создает версии файлов и дает богатые возможности для обсуждения работ.
Одним словом Pixelapse — это GitHub для дизайнеров.
Некоторое время назад я опубликовал очень многословное сочинение, где пытался объяснить, почему Git серьёзно поломан, и почему всем следует вместо этого пользоваться Mercurial, до тех пор, пока разработчки Git его не починят. Ну ладно, я был не настолько груб, но близок к этому.
Народ на Reddit жаловался, что мой технический язык слишком путанный, особенно потому что я придумывал новую терминологию в попытках доказательства своих положений. Они потребовали графы, с узлами, рёбрами, кружочками, стрелочками и всем прочим. Тогда я промучал графический редактор несколько часов и получил два графа, приведённые ниже, которыми я надеюсь обрисовать проблему.
Ниже я нарисовал упрощёный граф истории репозитория Git с тремя созданными ветками: «master», «release» и «topic». До того, как энтузиасты Git начнут ругаться, что я исхитрился показать нереально плохой случай запутанности истории, позвольте мне заверить вас, что это на самом деле ещё упрощённый пример. У меня есть доступ к реальному репозиторию Git, где создано шесть рабочих веток релизов, около сорока рабочих тематических веток и несколько сотен ранее существовавших веток, которые уже удалены с центрального сервера.
Попросили вот здесь про Sciter слово замолвить… Собственно вот рассказываю.
Sciter есть встраиваемый HTML/CSS/scripting engine для создания UI десктопных и мобильных приложений, классических так и [occasionally-]connected.
В принципе поддерживаются разные парадигмы приложений ограниченные лишь фантазией разработчиков. Например одной фирмой была сделана телефонная система со smart desktop phones на которых работал Sciter-based client — фактически специализированный browser загружающий UI (HTML,CSS, scripts и images) с системного контроллера станции по специализированному протоколу.
Другой пример: фирма Symantec использует sciter как UI для их consumer продуктов — Norton Antivirus со товарищи (since 2007).
На картинке: sciter.exe demo проект из SDK + открытое окно DOM inspector'а, живет в inspector32.dll (исходники в SDK). inspector.dll можно использовать в своем проекте для отладки UI. Естественно что inspector UI есть опять же HTML/CSS/script + толика native code.
Кто не мечтал попробывать разработать собственную игру. Мы будем создавать игру в стиле interactive fiction Сюжет я взял на сайте одной из систем программирования RTADS. Система локализована на русский язык и содержит полный набор средств и руководств для программирования. Но… Программировать мы будем в другой системе Inform7 Она мне больше нравится, т.к. я люблю английский. Итак сюжет.
Сюжет
… В качестве примера мы разработаем игру, действие которой будет происходить в небольшом аэропорту. Наш аэропорт будет иметь терминал, центральный зал, а также выходы к самолетам.
Не так давно SLY_G опубликовал цикл переводов книги Eloquent Javascript (за что ему большое спасибо). В комментариях раз за разом поднимались вопросы о сборке переводов книги, что, собственно, я и сделал при помощи сервиса Gitbook — «Выразительный Javascript», pdf, ePub, mobi и онлайн версия.
После закрытия Гуглом своих API для перевода проблема поиска онлайн-сервис для машинного перевода стала особенно актуальной. В Интернете много сервисов перевода с громкими именами: Промт, Прагма и пр. Нет никакой проблемы в PHP смоделировать обращения к страницам сервисов и получить результаты перевода. Но есть проблема: почти все сервисы в ответ на простой GET или POST запрос отдают не результат перевода, а целиком страницу во всей красе, начиная с DTD. Как говорят у нас на Украине, “дурных нэма”. После анализа было выяснено, что есть только два сервиса, которые отдают в ответ на запрос только результат перевода: Яндекс и Bing от Microsoft.
Привет! Если ты это читаешь, значит знаешь, что такое Sublime Text 2 или слышал о нем хоть, что-то.
Сегодня пойдет речь о том, как я его настраивал и мучал свои мозги. Тут все будет легко, все будет разложено по полочкам, но как я доставал инфу на разных зарубежных форумах, пересматривал все файлы, что бы найти эти настройки — это просто пипец, мягко говоря. Ладно, не буду больше жаловаться, приступим.
И так, я расскажу про то, как я: 1. Боролся с кодировкой при открытии. При открытии фала с кодировкой windows-1251, русские буквы превращались в кракозябры. 2. Установка словаря, для подсветки, если не правильно написал слово. 3. Установка плагина SFTP и подключение к серверу.
Рассказ о том, что каждый инженер должен сделать в своей жизни после того, как он родил ребенка, посадил дерево и построил дом – это сделать свое файловое хранилище.
Доклад мой называется «Опыт построения и эксплуатации большого файлового хранилища». Большое файловое хранилище мы строим и эксплуатируем последние три года. В тот момент, когда я подавал тезисы, доклад назывался «Ночью через лес. Опыт построения эксплуатации бла-бла-бла». Но программный комитет попросил меня быть серьезнее, тем не менее, на самом деле это доклад «Ночью через лес».
В последнее время мы часто сталкиваемся с вопросами о том, как попасть в игровую индустрию, какие полезные материалы на эту тему можно почитать и посмотреть, с чего начать изучение геймдева. Когда начальные знания появляются, то возникают уже более конкретные вопросы, например «где найти единомышленников для создания игры», «как продвигать свой проект с минимальным бюджетом», «на каких издателей стоит выходить, как это делать и стоит ли вообще», «как улучшить ретеншн в нашей игре» и так далее.
Друг наших образовательных программ Михаил Пименов, CEO компании Wonder Games и Team Lead инди-проекта "Guard of Wonderland" сам не раз задававший себе эти вопросы, создал для себя выборку всевозможных материалов по индустрии геймдева. От полезных ресурсов, до сообществ, подкастов, книг и фильмов, которые призваны помочь понять, с чего начинается и чем заканчивается разработка игрового проекта. Объединив наши силы, мы с Мишей сделали эту статью с подборкой полезных материалов по игровой индустрии. Вы найдете подборку под катом.
Skyeng делится с Хабром ссылкой на внутреннее приложение, которым пользуются наши методисты.
Мы в школе Skyeng убеждены, что чем быстрее ученик получает ощутимый эффект от занятия или тренировки, тем выше его мотивация и эффективнее само обучение. Традиционная методика изучения языков обещает конкретный результат лишь через длительное время — год, два, т.е. требует вложения значительных сил, времени и средств без немедленного эффекта. Мы считаем, что вполне реально получить “возврат инвестиций” быстро, если ставить перед собой небольшие конкретные задачи и решать их. Сегодня мы расскажем про один из наших служебных инструментов, предназначенный как раз для этого, и дадим читателям возможность попробовать его в деле, составить собственные списки слов, самые интересные из которых будут предложены всем пользователями Aword!
Как разработчик, вы возможно в курсе о Google Hosted Libraries. Google предоставляет простой и быстрый способ, как включить в ваши веб-сайты 12 самых популярных JavaScript-библиотек.
Но что, если вы – вебмастер и хотите использовать преимущество быстрых CDN при использовании в других менее популярных проектах? Или же вы – разработчик и хотите сделать ваш проект более удобным в использовании и более доступным другим пользователям.
Здесь в игру вступает jsDelivr. jsDelivr – это бесплатная и свободная CDN, созданная для того, чтобы помочь разработчикам и вебмастерам. В ней нет ограничений по популярности и разрешены все типы файлов, включая библиотеки JavaScript, плагины jQuery, CSS-фрэймворки, шрифты и многое другое.
Разработчики компании EDISON создали программу Управления доступом к электронным документам, о чем я писал пару лет назад, а сегодня речь пойдет об SDK для внедрения поддержки электронных книг в формате FB2.
«Я должен был закончить книгу, прежде чем родится мой сын. Теперь ему 40 лет, и я до сих пор не закончил её.»
На третий год моего пребывания в университете меня попросили провести пару занятий о компьютерах. Группка людей сказала, что в Caltech (Калифорнийском технологическом институте) не учат ничему, что связанно с компьютерами.В это время я консультировал Burroughs. «Так почему бы тебе не провести пару занятий в университете?» — спросили меня. Так я провел занятие всего один раз, и прежде чем закончить университет, они решили нанять меня в качестве доцента, сразу после его окончания учебы.
Обычно в университет не берут на работу собственных выпускников, за исключением MIT. Но как вы знаете, считается нехорошо делать инбридинг (кровосмешение), потому что отделение может увязнуть в одной философии, а они хотят «свежей крови». Но Caltech счел меня достаточно странным и чуждым «по крови», и это было положительным доводом, чтобы нанять меня.
Я довольно долго работал над докладом и старался сделать его настолько противоречивым, насколько это возможно. И сразу начну с противоречия – я в корне не согласен с тем, что веб-компонентами можно пользоваться. Уже поднимался вопрос о 300 Кбайтах, я глубоко уверен, что 300 Кбайт для страницы Javascripta – недопустимо много.
Сегодня я расскажу о довольно глубоком путешествии во фронтенд. Началось это путешествие тогда, когда я обнаружил, что фронтенд aviasales.ru тормозит, и надо что-то делать. Это путешествие началось года полтора-два назад, и вещи, о которых я буду рассказывать, – это сжатое повествование того, что я узнал.
Самым критичным, на мой взгляд, в производительности фронтенд-приложений является рендеринг. Все мы знаем, что работа с DOM – это такая вещь, которую нужно стараться избегать. Чем больше вы делаете вызовов к DOM API, тем медленнее работает ваше приложение.
Tahoe-LAFS — это p2p файловая система (ФС). Вы совместно используете свободное место на диске вместе с вашими друзьями, формируя распределенную ФС. Причем ФС работает даже если часть компьютеров образующих ФС недоступны. Все автоматически шифруется, поэтому можно делать бэкапы на распределенную ФС при этом не давая свободного доступа к вашим файлам. Тем не менее можно предоставить доступ некоторым пользователям к вашим файлам или каталогам.
Вы любите смотреть таргетированную рекламу? Вы не против того, что фейсбук сам отметит вас на фотографии друзей (а ее увидят посторонние люди)? Вам нравится видеть релевантные запросы в поисковике? Вы не против того, чтобы ваши предпочтения использовали для рекламы товаров вашим друзьям? Вам все равно, что гугл хранит всю историю вашего поиска, и вы не боитесь, что это может кто-то увидеть через 10 лет («скачать Аватар бесплатно без смс» или «как избежать проверки налоговой»)? Вы не против того, что ваши фото и комментарии увидит потенциальный работодатель или весь интернет, если вы вдруг случайно станете кому-то интересны?
Тогда этот пост вам будет не интересен — желаю вам хорошего дня. Пост не благословлен ФСБ, различными рекламными биржами (привет, «Яндекс», «Tinkoff Digital» и т. д.) и соц. сетями.
Если же вы решили озаботиться своей приватностью, иметь минимум данных для компромата и построения психологического и поведенческого профиля, когда вы или ваши родители совершите какой-нибудь факап и обратите на себя внимание общественности (или когда вы добьетесь успехов и кто-то из недоброжелателей будет специально искать эти данные) — добро пожаловать под кат с пошаговой инструкцией для основных программ и сетей. Нашей целью будет обеспечение максимальной приватности при сохранении максимального удобства серфинга. Понятно, что если вы хотите обеспечить себе максимальную конфиденциальность, то лучше не пользоваться социальными сетями, пользоваться различными анонимизаторами и т. д., но на это не все согласны пойти.
В этой части поговорим о настройках браузера и настройках google-аккаунта. Следующие части будут посвящены настройкам «Фейсбука», «Контакта», а также специфическим вещам в мобильных ОС на примере iOS. Любые дополнения приветствуются и будут с удовольствием включены в этот импровизированный «мануал» (или следующий, если они будут про темы следующих статей).
Как раз тогда я искал какой-то инструмент для того, чтобы сделать автопрефиксер. Когда я прочитал эту статью, я был поражен, потому что это был действительно революционный подход, он менял все. И поэтому первые версии автопрефиксера базировались на Rework’е. Но, к сожалению, Rework – это был Proof Of Concept, это было первое поколение, чтобы доказать, что это вообще работает. Поэтому мы его жестко форкнули, переманили всех разработчиков, устроили маленькую революцию и сделали PostCSS.
PostCSS – это второе поколение модульного процессора.
В 1960-х годах появился новый подраздел информатики — искусственный интеллект (ИИ). Полвека спустя инженеры продолжают развивать обработку естественного языка и машинное обучение, чтобы оправдать надежды на появление сильного ИИ.
Сегодня мы расскажем о том, как машинное обучение используется сейчас: почему нейронные сети популярны у физиков, как работают рекомендательные алгоритмы YouTube и поможет ли машинное обучение «перепрограммировать» наши болезни.
На современных web сайтах объем картинок может составлять от 30% до 70% всего размера страницы. Например, объем изображений на Хабре обычно составляет несколько мегабайт.
Большинство изображений в Web'e — это фотографии. Профильные фото в соц. сетях, альбом с телефона, профессиональные снимки и т.п. Правильная стратегия и инструменты для работы с фотографиями позволят сделать сайт быстрым для посетителей.
Сначала извинюсь, тут малость сыро, хотя и работает, а сейчас работает "влет", но без телефонии возможности ограничены. В основном был описан вариант для разработки, когда основной каталог $OPENSHIFT_REPO_DIR (~/app-root/repo) и Вы в своем локальном репозитории имеете копию, делаете правки, OpenShift — это Ваша песочница. Но есть вариант установки "для эксплуатации". Он упомянут в конце вышеуказанной статьи, но без деталей. В этом случае Вы используете $OPENSHIFT_DATA_DIR (~/app-root/data). Разница в том, что локальный репозиторий содержит настроечные скрипты (action_hooks, см. ниже) и файлы данных, патчи, etc. Но не само приложение целиком.
Мини-руководство иллюстрирует ряд приемов работы с OpenShift. Работа с github.com, git детально не разбирается, предполагается, что читатель уже имеет представление.
Создание и клонирование на OpenShift заготовки.
Редактирование скриптов развертывания для получения годного установочного комплекта.
Запись репозитория на github.com (для хранения).
Развертывание приложения на OpenShift.
Руководство "step-by-step", основанное на реальном примере.
Все знают офисных монстров PowerPoint и Keynote, но почему-то мало кто с радостью в них работает. И действительно, что делать, если ты совсем не бухгалтер, а разработчик или просто гик и гораздо комфортнее чувствуешь себя в коде, чем в офисных пакетах? У меня для тебя хорошие новости: презентации уже очень давно можно делать прямо в браузере, а писать с помощью таких простых и знакомых вещей, как HTML, CSS или даже Маркдаун.
К каждому из нас приходит момент, когда нужно донести свои мысли до других. Не просто рассказать анекдотец коллеге, не пробубнить стишок про бурю-мглою, а сообщить что-то принципиально важное, объяснить сложную идею, поделиться опытом. И если самым талантливым из нас достаточно выйти на сцену и просто быть собой, как это делают участники TED, то большинству понадобится опереться на слайды. Свой первый раз у доски с маркерами я забыл напрочь, помню только, что переврал тогда ключевую идею доклада про блочную модель CSS.
В начале истории веба таблицы являлись основой отображения информации. Со временем разработчики нашли новые, более модные способы представления данных, и таблицы отошли на второй план. Сегодня таблицы используются гораздо реже, однако по-прежнему собирают и упорядочивают большие объёмы информации, с которыми мы сталкиваемся ежедневно.
Шестого октября компания Google презентовала расширенную версию своего свободного шрифта Noto (No more tofu). Название у шрифта говорящее. Tofu — всем известный пустой квадрат вместо символа в ситуациях, когда тот не поддерживается используемым шрифтом: ⯐.
Новый шрифт от Google поддерживает корректное отображение всех символов юникода, то есть более 800 языков и 110000 символов.
Не то чтобы я был диким фанатом консолей, но есть вещи, которые действительно впечатляют. Понятное дело, что консолям нового поколения без впечатляющих пилотов на рынке делать нечего. Речь идет не о Watch Dogs, который тоже заслуживает внимания, как любая песочница с открытым миром, а о Tom Clancy’s The Division анонсированная для PS4 и Xbox One. Картинка (я оцениваю лишь ее) выглядит действительно хорошо. Игры уже давно стремятся быть не играми. Это уже почти кино. Меня мало волнует сейчас вопрос гейм-плея данной игры. Сейчас я просто потребитель, который готов клюнуть на вкусную обертку.
Параллельно с этим во мне просыпается девелопер-скептик, который ничего и никогда не принимает на веру, который до того как возопить о пришествии чего-либо сперва хочет убедиться в том, что пришествие произошло. Не потому, что боится выглядеть глупо, но потому что, обжегшись тысячи раз — не хочет повторить это в тысяче первый.
Мне уже давно не удается играть в игры как игроку. Иметь стопроцентное погружение. Это побочный эффект призмы через которую я смотрю на любую игру. Глаз в первую очередь цепляется за знакомые графические артефакты, ищет пути, которыми шли разработчики в создании графического контента. Одобрительно хлопает плюсам, и огорченно хмурит брови там, где все осталось как есть, без изменений. Все это помножено на «взгляд художника», который также аплодирует умелым действиям, и негодующе рычит в тех местах, где неизвестный художник допустил ошибку. Все это множится на еще не добитого геймера, который превыше всего ставит гейм-плей.
Сложный коктейль мешающий, в полной мере, наслаждаться компьютерными играми. Борьба противоположностей. Внутренний конфликт потребителя и разработчика.
Что я вижу здесь? Для начала посмотрите трейлер и решите, что видите для себя вы. А потом… лопата?
Как следует из заголовка, речь в статье пойдёт о неотъемлемой части любого русскоязычного (и не только) текста — о пробеле. Мы затронем историю пробела, виды пробелов, вопросы употребления пробела в веб-типографике.
Вообще говоря, пробел — это любое пустое место в рукописном, печатном или отображаемом на любом другом носителе тексте. Так что пробелы бывают разные:
спусковые (большие вертикальные пропуски в первой полосе издания) и концевые пробелы полосы,
абзацные отступы и концевые пробелы абзаца,
межстрочные пробелы (между строками текста),
межсловные пробелы (между словами в одной строке),
межбуквенные пробелы (между буквами в слове).
Далее речь пойдёт о межсловных пробелах, разделяющих слова, и функционально принадлежащих к знакам препинания.
В чем проблема текстовых форматов обмена данными? Они медленные. И не просто медленные, а чудовищно медленные. Да, они избыточны, по сравнению с бинарными протоколами и, по идее, текстовый сериализатор должен быть медленнее примерно на столько же, на сколько он избыточен. Но на практике получается, что текстовые сериализаторы иной раз на порядки уступают бинарным аналогам.
Я не буду рассуждать о преимуществах JSON перед бинарными форматами — у каждого формата есть своя область применения, в которой он хорош. Но зачастую мы вынуждены отказываться от чего-то удобного в пользу не очень комфортного в силу катастрофической неэффективности первого. Разработчики отказываются от JSON, даже если он прекрасно подходит для решения задачи, только из-за того, что он оказывается узким местом в системе. Конечно же, виноват не JSON сам по себе, а реализации соответствующих библиотек.
В этой статье я расскажу не только о проблемах парсеров текстовых форматов вообще и JSON в частности, но и о нашей библиотеке, которую мы используем уже много лет в самых высоконагруженных проектах. Она настолько нас устраивает и в плане быстродействия, и в плане удобства использования, что порой отказываемся от бинарного формата там, где бы он больше подошел. Конечно же, я имею в виду некие пограничные условия, без претензий на все случаи жизни.
Рад представить дополнение оригинального списка из 300 потрясающих бесплатных сервисов. Автор оригинальной статьи Ali Mese добавил ещё +100 новых сервисов, которые помогут найти все — от источников вдохновения и редакторов фотографий до создания опросов и бесплатных иконок.
И еще подборку +500 инструментов от 10 марта 2017 г. смотрите здесь.
Сегодня я расскажу, как сэкономить на базах данных огромные деньги, например, миллион долларов, как это сделали мы. Для начала вопрос: почему чаще используют именно базы данных, а не файлики?
Базы данных – это хранилище, более структурированное, чем файл, и обладающее рядом некоторых фич, которых у файла нет.
Там можно делать запросы, там есть транзакции, индексирование, таблицы, устойчивые, более-менее надежные хранилища. На самом деле, базы данных – это более удобно, чем файлы.
PDF (Portable Document Format) — один из форматов представления документов в электронном виде. Главной его особенностью является кроссплатформенность. Это значит, что документ PDF будет выглядеть одинаково при его просмотре на любом ПО в любой операционной системе или при распечатке на любом оборудовании.
Формат PDF получил сегодня огромное распространение. Де-факто он стал самым настоящим стандартом для обмена электронными документами. Поэтому многим людям приходится сталкиваться с различными задачами, касающимися формата PDF: созданием и чтением файлов, заполнением форм, редактированием и комментированием документов и так далее. На сегодняшний день для их решения создано достаточное количество программных инструментов.
В статье рассматриваются следующие программы: Microsoft Office, Universal Document Converter, Abbyy FineReader, Adobe Reader, Foxit Reader, Jaws PDF editor, Advanced PDF Recovery.
Всё больше полезных программ удаётся портировать на открытые веб-технологии. До сих пор среди них не было редактора шрифтов. Теперь есть: Glyphr.
Профессиональный софт для проектирования шрифтов — это сложные и дорогие программы. В отличие от них, интерфейс Glyphr вполне доступен для каждого желающего, а само приложение совершенно бесплатно.
Я много лет использую UltraEdit как редактор на самые разные случаи жизни. Одна из основных причин — быстрая работа с гигабайтными файлами без загрузки их в память. Для программирования на JavaScript он тоже достаточно удобен, вот только с одним существенным недостатком: автодополнение в нём основывается на достаточно бедном, жёстко заданном списке ключевых слов и глобальных переменных, вдобавок отстающем от развития языка. Как-то я задался вопросом, можно ли пополнить этот список полным перечнем всех готовых свойств и методов, какие только можно ввести в контексте Node.js и Web API (браузера). Где бы такой список можно раздобыть? Мне приходили в голову такие варианты:
Готовый перечень, кем-то составляемый и обновляемый для всеобщего пользования, вроде библиотеки globals, но полнее.
Парсинг документации (спецификация ECMAScript, сайты MDN и Node.js и т.п.), вручную или программно.
Native script (NS) – это библиотека, позволяющая делать кросс-платформенные приложения, используя XML, CSS, JavaScript. Native script решает ту же задачу, что и уже всем известный phonegap (создание кросс-платформенных приложений), но подходы у них разные. Phonegap использует движок браузера, чтобы отобразить ваш UI (фактически вы получаете веб-страницу), Native script использует нативный рендеринг, использует элементы нативного UI. Следующее важное отличие: чтобы получить доступ к камере, gps и так далее в phonegap необходимо устанавливать плагины, в то время как NS дает доступ из коробки.
Программа Neural Doodle, сделанная на основе свёрточной нейросети, представляет собой скрипт doodle.py, который генерирует изображения, принимая три-четыре картинки в качестве входных параметров. В том числе на вход подаётся простенький набросок (то что авторы называют «каракулями») и образец стиля с его наброском. Например, в случае с примером выше образцом стиля является такая картина Ренуара.
Идея для написания этой статьи возникла прошлым летом, когда я слушал доклад на конференции BigData по нейронным сетям. Лектор «посыпал» слушателей непривычными словечками «нейрон», «обучающая выборка», «тренировать модель»… «Ничего не понял — пора в менеджеры», — подумал я. Но недавно тема нейронных сетей все же коснулась моей работы и я решил на простом примере показать, как использовать этот инструмент на языке JavaScript.
Мы создадим нейронную сеть, с помощью которой будем распознавать ручное написание цифры от 0 до 9. Рабочий пример займет несколько строк. Код будет понятен даже тем программистам, которые не имели дело с нейронными сетями ранее. Как это все работает, можно будет посмотреть прямо в браузере.
В свое время на Хабре был опубликован цикл статей «Логика мышления». С тех пор прошло два года. За это время удалось сильно продвинуться вперед в понимании того, как работает мозг и получить интересные результаты моделирования. В новом цикле «Логика сознания» я опишу текущее состоянии наших исследований, ну а попутно попытаюсь рассказать о теориях и моделях интересных для тех, кто хочет разобраться в биологии естественного мозга и понять принципы построения искусственного интеллекта.
Перед началом хотелось бы сделать несколько замечаний, которые будет полезно помнить во время чтения всех последующих статей.
Ситуация, связанная с изучением мозга, особенная для науки. Во всех остальных областях естествознания есть базовые теории. Они составляют фундамент на котором строятся все последующие рассуждения. И только в нейронауке до сих пор нет ни одной теории, которая хоть как-то объясняла, как в нейронных структурах мозга протекают информационные процессы. При этом накоплен огромный объем знаний о физиологии мозга. Получены очень обнадеживающие результаты с помощью искусственных нейронных сетей. Но перекинуть мостик от одного к другому, пока, не удается. То, что известно о биологических нейронных сетях очень плохо соотносится с созданными на сегодня архитектурами искусственных нейронных сетей.
Не должна вводить в заблуждение распространенная фраза о том, что многие идеи искусственных нейронных сетей позаимствованы из исследований реального мозга. Заимствование носит слишком общий характер. По большому счету, оно заканчивается на том, что и там и там есть нейроны и между этими нейронами есть связи.
Маркетологи быстро выяснили, что в «системе принятия решений о доверии» есть уязвимость — люди охотнее доверяют рукописному тексту, чем печатному. Очень быстро появились рукописные шрифты и подписи в объявлениях/письмах, но они легко распознавались. Теперь же есть возможность автоматизированного написания «от руки» настоящей ручкой (даже перьевой), с учетом всех отступов, расстояний неровностей, несоблюдением пропорций, нажима и углом наклона (осталось следы от шоколадки и кофе автоматически эмулировать).
Там где баги с доверием, там и социальные инженеры тут как тут. Ныряние в мусорные корзины теперь будет приносить больше плодов. Можно будет набрать достаточный объем рукописного текста для подделки.
У сервиса Bond, который предоставляет услуги по отправке реальных писем, есть все шансы пройти «рукописный тест Тьюринга» (т.е. человек не сможет отличить, писал ли этот текст человек или робот).
Я часто говорил, что достаточно знаю ИТ, чтобы не доверять ИТ, теперь же рухнуло и доверие к «реальным документам». Достаточно несколько школьных сочинений скормить нейронным сетям, чтобы они смогли писать за меня (и даже лучше чем я). Кстати, сервис Bond предоставляет услуги по улучшению/тьюнингу вашего почерка.
Итак, что же нам нужно, чтобы на нас оставили завещание? Шаг первый. Создаем 3d принтер, который эмулирует письмо от руки Шаг второй. Создаем самообучающуюся программу и скармливаем ей несколько листов рукописного текста жертвы клиента Шаг третий. Profit
Под катом краткий обзор оборудования, примеры писем, знакомство с проектами Maillift (письма «от руки»), Bond (письма от руки и распознание и эмуляция почерка), Herald (как студенты свой принтер спаяли)
Расширения для браузеров — мощный инструмент продвинутого веб-сёрфинга, самая доступная, развитая и распространённая часть целого ряда инструментов. Однако расширения имеют и слабые стороны: каждый браузер требует знания и применения своих правил и форматов, а это дополнительная сложность для создателя. Расширения не кроссбраузерны, что сразу ограничивает их адресат. Есть попытки обобщить создание расширений, но они могут добавлять уже свою дополнительную прослойку форматов и правил.
Когда расширение улучшает специфические стороны браузерного интерфейса, без него не обойтись. Но некоторые задачи универсальны, не связаны с частными средствами браузера и, тем не менее, без расширения их тоже не выполнить. Одна из таких задач — кроссдоменные XMLHttpRequest запросы, нарушающие политику одного источника.
За последнее десятилетие само понятие компьютера изменилось очень сильно, но не от всех узких мест пока что получилось избавиться. Одно из таких бутылочных горлышек — жёсткий диск. Это его трудами операционная система часто не может загрузиться с холодного старта за 10 секунд. Есть, конечно, SSD, но использовать его как основное хранилище сложно из-за небольшого объёма. И получается что даже SSD не может сломать современную архитектуру: есть медленное хранилище и быстрая оперативная память.
Оперативная память хоть и быстрая, но энергозависимая. Жесткий диск надёжный, энергонезависимый, но медленный. А вот SSD и быстрее жёского диска и энергонезависимый. В будущем SSD (или его преемник) просто обязан заменить собой и оперативную память и жёсткий диск, а пока же при его помощи можно значительно ускорить работу компьютера.
В домашних компьютерах SSD уже не редкость. Часто на нём создают системный раздел, ставят на него ОС и тяжёлый софт (говорят, даже фотошоп начинает летать), а музыку и фильмы продолжают хранить на жёстком диске.
В серверах, когда надо чтобы база данных работала очень быстро, а в память её загнать уже нельзя, можно заказать себе в качестве носителя SSD и база оживает. Пока место на SSD не закончится. И начинается заказ хитрых RAID-массивов или сбор кластера.
В 2011 году компания Intel представила жаждущим до скорости людям технологию под названием Smart Response Technology (SRT), использующую SSD как кеширующий буфер между оперативной памятью и жёстким диском. Можно использовать SSD объемом до 64Гб, и кешируются не сами файлы, а запрашиваемые логические блоки с жёсткого диска, а если SSD вдруг заполнится, то ячейки, к котором давно не обращались, начнут заполняться новыми данными. Поступает этот SRT прямо как линукс с оперативной памятью, молодец.
Ранее в нашем блоге мы поднимали тему создания качественных веб-интерфейсов, в частности в одном из предыдущих топиков рассматривался вопрос правильного использования анимаций. В сегодняшнем материале речь пойдёт о технологии SVG, принципах работы с этой технологией, её плюсах и минусах. Кроме того, мы поинтересовались у отечественных дизайнеров, применяют ли они SVG, и если нет, то почему.
Я не самый талантливый кодер в мире. Правда. Так что я стараюсь писать как можно меньше кода. Чем меньше кода я пишу, тем меньше кода может ломаться, поддерживаться и требовать пояснений.
А еще я ленивый — мед, да еще и ложкой (я решил использовать в статье аналогии с едой).
Но, оказывается, что единственный гарантированный способ повысить производительность в вебе — это писать меньше кода. Минифицировать? Окей. Сжимать? Ну, да. Кэшировать? Звучит неплохо. Вообще отказываться кодить или использовать чужой код изначально? А вот теперь — в яблочко! Что есть на входе — должно выйти на выходе в той или иной форме, независимо от того, смог ли ваш сборщик растворить и переварить это своими желудочными соками (я, пожалуй, откажусь от пищевых аналогий).
И это не все. Кроме видимых улучшений производительности, где вам требуется то же количество кода, но его сначала нужно разжевать (не смог удержаться), вы также можете сэкономить. Моему провайдеру без разницы, посылаю ли я кучу маленьких писем или одно большое: все складывается.
В стремлении к уменьшению мне больше всего нравится вот что: в конце остается только то, что реально нужно, только то, что по-настоящему требуется пользователю. Огромная фотка какого-то чувака, пьющего латте? Выкинуть. Кнопки социальных сетей, которые подсасывают кучу левого кода и ломают дизайн страницы? Пинок под зад им. Эта хреновина на JavaScript, которая перехватывает правый клик и показывает кастомное модальное окно? Выставить на мороз!
Речь идет не только про подключение штук, которые ломают интерфейс. То, как вы пишете свой собственный код, тоже играет большую роль в стремлении к уменьшению кода. Вот несколько советов и идей. Я писал о них ранее, но в контексте удобства и отзывчивого дизайна. Просто так получается, что гибкий, удобный веб требует меньше контроля с нашей стороны и его сложнее сломать.
Совсем недавно побывал с детьми в московском интерактивном музее Живые Системы (г. Москва). Среди прочего попался мне на глаза интересный эксперимент на тему «как зародилась жизнь» с кубиками Lego. В стиральную машину закладывают разрозненные кубики Lego Duplo и через час-два вынимают. На выходе встречаются конструкции из двух, трёх а и иногда даже из четырёх деталей.
Эксперимент призван показать, что первичном бульоне вполне могли случайно образоваться сложные соединения и жизнь вообще.
Я не поверил, что такое возможно (в смысле Лего и стиралка за такое короткое время). Мне всегда казалось, что вероятность такой самосборки очень низкая, хотя и определённо не нулевая. Решил погуглить на эту тему и нашёл несколько отчётов об аналогичных экспериментах. Один из таких отчётов, где много интересных картинок, перевожу и публикую здесь. Некоторые примечания и ссылки из текста ссылки будут удалены. Часть из них опубликую в конце.
Состоятельные кубинцы подключаются к интернету через один из редких публичных хотспотов. Фото: Джон Грэм-Камминг
Английский программист Джон Грэм-Камминг (John Graham-Cumming) рассказал о своём удивительном путешествии на Кубу. Говорят, что в этой стране можно познакомиться с девушкой за пару долларов, а прожить целый месяц за 10-20 долларов. Однако интернет на Кубе очень дорогой. Во всей стране всего 175 публичных точек доступа WiFi, где медленный интернет тарифицируется по 2 конвертируемых песо за час работы (конвертируемый песо заменяет доллар и равен ему). Есть также мобильный интернет по цене 1 конвертируемый песо ($1) за мегабайт. Карты для доступа WiFi продаются строго по паспорту в государственных отделениях связи, хотя можно купить их на чёрном рынке анонимно по цене в полтора раза выше (или обменять на иностранную футболку, такие вещи очень ценятся на Кубе). Но это рискованно и грозит тюремным заключением.
EditorConfig это конфигурационный файл и набор расширений, к большому количеству редакторов кода и IDE (Далее просто IDE). Его задача — создать единый формат настроек, и, раз и навсегда, решить вопросы вроде “табы или пробелы” для всех IDE и всех языков программирования. Такой файл может храниться в системе контроля версий проекта, что позволит всем его разработчикам использовать одну и ту же конфигурацию.
Анимация элементов в мобильных приложениях — это просто. Правильная анимация тоже может быть простой… если вы последуете представленным в статье советам.
Сегодня кто только не использует CSS 3 анимацию в своих проектах, тем не менее не только лишь все, но мало кто может делать это правильно. Даже описаны так называемые «лучшие практики», но люди продолжают делать всё по-своему. Скорее всего потому, что просто не понимают, почему всё устроено именно так, а не иначе.
Я капризный. Я жалуюсь о многих вещах. Многое в мире технологий мне не нравится и это предсказуемо: программирование — шумная молодая дисциплина, и никто из нас не имеет ни малейшего представления, что он делает. Учитывая закон Старджона, у нас достаточно вещей для постижения на всю жизнь.
Тут другое дело. PHP не просто неудобен в использовании, плохо мне подходит, субоптимален или не соответствует моим религиозным убеждениям. Я могу рассказать вам много хороших вещей о языках, которых я стараюсь избегать, и много плохих вещей о языках, которые мне нравятся. Вперёд, спрашивайте! Получаются интересные обсуждения.
PHP — единственное исключение. Фактически каждая деталь PHP в какой-то мере поломана. Язык, структура, экосистема: всё плохо. И даже нельзя указать на одну убийственную вещь, настолько дефект систематичный. Каждый раз, когда я пытаюсь систематизировать недостатки PHP, я теряюсь в поиске в глубину обнаруживая всё больше и больше ужасных мелочей(отсюда фрактал).
PHP — препятствие, отрава моего ремесла. Я схожу с ума от того, насколько он сломан и насколько воспеваем каждым уполномоченным любителем нежелающим научиться чему-либо ещё. У него ничтожно мало оправдывающих положительных качеств и я бы хотел забыть, что он вообще существует.
В этом обзоре мы рассмотрим популярные в 2016 году игровые движки и проголосуем за лучшие из них.
Игровые движки предоставляют средства разработки, которые могут быть использованы программистами, чтобы упростить их работу. Короче говоря, предоставляют инструменты и функциональные возможности для разработки игры.
Поскольку побеждать Великий Китайский Роскомнадзор наша штука для обхода блокировок в интернете пока не особенно научилась, а рассказать что-нибудь странное про свою работу все равно хочется, расскажу про реимплементацию похожего на Readability алгоритма при помощи Node.js и Бэйцзинского технологического института.
Что это вообще такое
Readability — это радикальное продолжение идеи AdBlock убирать с веб-сайтов лишние элементы. Там, где AdBlock старается снести только самые бесполезные для пользователя вещи (в основном рекламу), Readability удаляет заодно скрипты, стили, навигацию и все остальное ненужное. Раньше такой вид страницы называли «версия для печати», хотя на самом-то деле текст предназначен для чтения (отсюда название Readability – «Удобочитаемость»).
Лирическое отступление про парсеры
Основная характеристика парсера сайтов, или других слабо структурированных форматов – это количество знаний о частных случаях использования формата в дикой природе.
Сегодня мы представляем вашему вниманию адаптированную подборку инструментов (в том числе облачных) для разработчиков, которые позволяют создавать по-настоящему качественные проекты. Здесь представлены исключительно SaaS, PaaS и IaaS сервисы, предоставляющие бесплатные пакеты для разработчиков инфраструктурного ПО.
В своём топике "Впечатления от Яндекс.Субботника" хабрачеловек absolvo высказал удивление, что один из докладчиков не знал о том, что символьные ссылки есть и в Windows. Честно говоря, не знал этого и я, поэтому поинтересовался об этих ссылках в комментариях.
Думаю, то, что удалось выяснить, может показаться кому-нибудь полезным.
Нашел я тут пакетик с USB флешками разных лет использования. Как обычно, в работе только две самые последние и самых больших размеров. Остальные — тут.
И возникла идея сделать из них RAID, например, просто «concatenated disk», ибо в OSX это делается очень просто. Идеи тут минимум, но было интересно попробовать.
Многоточие (эллипсис, от греч. ellipsis — незаполненность) — самостоятельный типографский знак, разновидность отточия, состоящий из трёх точек идущих подряд, используется для обозначения скрытого смысла, особенностей устной речи (вздох, пауза, задумчивость), недосказанности либо для исключения из текста некоторых слов, например при цитировании.
Физика транспортных средств в видеоиграх не очень сильно обсуждается. Статьи в Интернете о физике транспорта в видеоиграх немногочисленны и поверхностны; обычно они посвящены самым основам. Программист транспорта для видеоигр ощущает себя сегодня в относительном вакууме. Возможно, такая ситуация возникла, потому что эту тему довольно сложно объяснить, а может быть, мы просто стыдимся признаваться в использовании хаков, упрощений и хитростей, которые мы вносим по сравнению с «правильной», реалистичной симуляцией физики. Как бы ни обстояло дело, видеоигры имеют уникальные проблемы в симуляции транспорта, а значит, об этом стоит писать. Это захватывающая тема, относящаяся к физике, работе с камерой, звуку, спецэффектам, а также к восприятию и психологии человека.
Я решил сначала поговорить о судах, потому что недавно работал с ними; ещё я обнаружил, что их динамика не совсем понимается даже на уровне исследований (хотя многое и понятно). Модели и теории формулируются таким образом, что их становится сложно применить непосредственно в видеоиграх. Или же они требуют очень ресурсоёмких методов симуляции, которые практически невозможно контролировать и адаптировать под причудливые потребности разработчиков и игроков. Но можно написать упрощённую модель, которая учитывает важные параметры судна. В этом определённо есть доля искусства, «прыжка веры» и небольшая доля «творческой» физики, которая заставит Кельвина и Стокса перевернуться в могилах.
Одна из основных функций десктопного клиента Облака Mail.Ru — синхронизация данных. Ее целью является приведение папки на ПК и ее представления в Облаке к одинаковому состоянию. При разработке этого механизма мы встретились с некоторыми, с первого взгляда, достаточно очевидными особенностями различных файловых и операционных систем. Однако если о них не знать, можно столкнуться с довольно неприятными последствиями (не получится загрузить или удалить файл). В этой статье мы собрали особенности, знание которых позволит вам правильно работать с данными на дисках и, возможно, убережет от необходимости срочного хотфикса.
Аналогов подобных теней для точечного источника света (Pointlight с эффектом размытия на расстоянии, имитирующий arealight) в компьютерных играх я почему-то до сих пор не встречал. Везде — либо полностью запечённые тени, либо «лампочки» вообще без теней, максимум — обыкновенная PCF-фильтрация. Хотя для направленного солнечного света уже давно применяются PCSS-тени (GTA5, например). В Unreal есть интересный алгоритм сродни рейтрейсингу, который рисует красивые arealight-тени, но только для статической геометрии (требуется генерация дополнительных объёмов). В Unity же всё совсем плохо — мягко фильтруется только солнечный свет, а «прожекторы» и «лампочки» в пролёте.
Одна из мыслей, которая поселилась в моей голове: должен ли frontend-разработчик быть в курсе всего? В общем смысле, frontend-разработчик может использоваться и на других рабочих местах. Вся команда разработчиков заканчивает разговор на frontend-разработчике. В этом смысл моей идеи. Frontend-разработчики создают те вещи, с которыми будут взаимодействовать люди. Все этапы разработки проходят вместе с frontend-разработчиком. Возможно, именно поэтому это такая забавная работа! Поскольку frontend-разработчик занимает центральное место в цепочке разработки, и при этом мы имеем дело с большим количеством разных специалистов, мы должны понимать их работу и иногда подсказывать, что и как сделать лучше.
От переводчика
Всем привет, с вами Максим Иванов, и сегодня мы поговорим на довольно острую тему в сфере веб-разработки. Как утверждает Крис Койер, frontend-разработчик должен разбираться в очень многих вещах, о которых не все даже и задумываются. Конечно, мы должны понимать, что frontend-разработчик не главный в процессе разработки любого онлайн-сервиса или ПО в целом. На ту же позицию frontend-разработчика вы найдете больше откликов на вакансию, чем на позицию backend-разработчиком. Но почему же тогда Крис Койер считает, что работать frontend-разработчиком сложнее, ибо ты должен специализироваться во всем. Конечно, ситуаций в жизни очень много, разные компании по-разному используют своих специалистов, но в чем наверняка должен разбираться frontend-разработчик? Об этом мы сегодня и поговорим. Жду комментариев на эту тему, а сейчас приступим.
Приветствую тебя, Хабр! Наверняка вы заметили, что тема стилизации фотографий под различные художественные стили активно обсуждается в этих ваших интернетах. Читая все эти популярные статьи, вы можете подумать, что под капотом этих приложений творится магия, и нейронная сеть действительно фантазирует и перерисовывает изображение с нуля. Так уж получилось, что наша команда столкнулась с подобной задачей: в рамках внутрикорпоративного хакатона мы сделали стилизацию видео, т.к. приложение для фоточек уже было. В этом посте мы с вами разберемся, как это сеть "перерисовывает" изображения, и разберем статьи, благодаря которым это стало возможно. Рекомендую ознакомиться с прошлым постом перед прочтением этого материала и вообще с основами сверточных нейронных сетей. Вас ждет немного формул, немного кода (примеры я буду приводить на Theano и Lasagne), а также много картинок. Этот пост построен в хронологическом порядке появления статей и, соответственно, самих идей. Иногда я буду его разбавлять нашим недавним опытом. Вот вам мальчик из ада для привлечения внимания.
Привет, Хабр, давно не виделись. В этом посте мне хотелось бы рассказать о таком относительно новом понятии в машинном обучении, как transfer learning. Так как я не нашел какого-либо устоявшегося перевода этого термина, то и в названии поста фигурирует хоть и другой, но близкий по смыслу термин, который как бы является биологической предпосылкой к формализации теории передачи знаний от одной модели к другой. Итак, план такой: для начала рассмотрим биологические предпосылки; после коснемся отличия transfer learning от очень похожей идеи предобучения глубокой нейронной сети; а в конце обсудим реальную задачу семантического хеширования изображений. Для этого мы не будем скромничать и возьмем глубокую (19 слоев) сверточную нейросеть победителей конкурса imagenet 2014 года в разделе «локализация и классификация» (Visual Geometry Group, University of Oxford), сделаем ей небольшую трепанацию, извлечем часть слоев и используем их в своих целях. Поехали.
D3.js — это библиотека JavaScript для управления документами, в основе которых лежат данные. D3 помогает претворить данные в жизнь, используя HTML, SVG и CSS. D3 позволяет привязывать произвольные данные к DOM, и затем применять результаты манипуляций с ними к документу.
Для понимания статьи пригодится знание основ D3, и в ней мы рассмотрим реализацию алгоритмов визуализации графа на основе сил (Force-directed graph drawing algorithms), которая в D3 (version 3) имеет название Force Layout. Это класс алгоритмов визуализации графов, которые вычисляют позицию каждого узла, моделируя силу притяжения между каждой парой связанных узлов, а также отталкивающую силу между узлами.
Иногда средствами файловой системы приходится хранить массу информации, большинство из которой статично. Когда файлов немного и они большие — это терпимо. Но если данные лежат в огромном количестве маленьких файликов, обращение к которым псевдослучайно, ситуация приближается к катастрофе.
Есть мнение, что специализированная read-only файловая система при прочих равных обладает преимуществами перед оной общего назначения т.к:
не обязательно управлять свободным пространством;
не надо тратиться на журналирование;
можно не заботиться о фрагментации и хранить файлы непрерывно;
возможно собрать всю мета-информацию в одном месте и эффективно ее кэшировать;
грех не сжимать мета-информацию, раз уж она оказалась в одной куче.
В этой статье мы будем разбираться, как можно организовать файловую систему, имея целевой функцией максимальную производительность при минимальных издержках.
Привет, хабрапользователь! После небольшого перерыва можно опять браться за трехмерную графику. В этот раз мы поговорим о таком алгоритме глобального затенения, как Normal-oriented Hemisphere SSAO. Интересно? Под кат!
Однажды, разглядывая очередную демку с эффектом, возник вопрос: а можно ли сделать SSAO на мобильном девайсе так, чтобы и выглядело хорошо и не тормозило? В качестве устройства был взят Galaxy Note 3 n9000 (mali T62), цель — фпс не ниже 30, а качество должно быть как на картинке выше.
Как я и обещал – публикую вторую статью о некоторых моментах разработки игр в трех измерениях. Сегодня расскажу об одной технике, которая используется почти любом проекте ААА-класса. Имя ей — HDR Rendering. Если интересно — добро пожаловать под хабракат.
Привет, друг! В этот раз я опять подниму вопрос о графике в ААА-играх. Я уже разобрал методику HDRR (не путать с HDRI) тут и чуть-чуть поговорил о коррекции цвета. Сегодня я расскажу, что такое SSLR (так же известная как SSPR, SSR): Screen Space Local Reflections. Кому интересно — под кат.
Как следует из названия, в далеком 2011 году мы совершили третью ошибку, выбрав в качестве основы для игрового движка Ogre3D. Третью, потому что первой ошибкой было решение делать игру, а второй — делать ее на своем движке. К счастью, это были те самые ошибки, с которых начинается увлекательная история. Это приключение, в котором мы прошли почти весь путь развития игровых движков, как зародыш проходит все этапы эволюции. Конечно же, как и все начинающие разработчики, мы слабо представляли себе, что и зачем мы собираемся делать. Нами двигало желание рассказать свою историю, создать свой вымышленный мир, свою вселенную, и на волне популярности ММО, естественным позывом было сделать свою ММО с блекджеком и всем причитающимся. Позыв случился еще в 2010, а к 2011 была готова первая версия диздока. Земля же была безвидна и пуста, и тьма над бездною, и Дух Фоллаута витал над нами.
Мы шли путем проб и ошибок, собирая по пути все косяки и грабли. Как и большинство проектов, мы начали с самого простого. В плане графики (а я буду рассказывать только о графической части) первая версия движка позволяла использовать только диффузную карту и стенсильные тени.
Github — важная часть жизни современного разработчика: он стал стандартом для размещения opensource-проектов. В «2ГИС» мы используем гитхаб для разработки проектов web-отдела и хостинга проектов с открытым кодом.
Хотя большинство из нас пользуются сервисом практически каждый день, не все знают, что у него есть много фишек, помогающих облегчить работу или рутинные операции. Например, получение публичного ключа из URL; отслеживание того, с каких сайтов пользователи приходят в репозиторий; правильный шаринг ссылок на файлы, которые живут в репозиториях гитхаба; горячие клавиши и тому подобное. Цель этой статьи — рассказать о неочевидных вещах и вообще о том, что сделает вашу работу с гитхабом продуктивнее и веселее (я не буду рассматривать здесь работу с API гитхаба, так как эта тема заслуживает отдельной статьи).
Известный в сообществе Amiga и Siggraph хакер Тим Дженисон (Tim Jenison) потратил много месяцев, чтобы воспроизвести предполагаемую технику живописи, которую использовал голландский художник Ян Вермеер в середине 17 века. До сих пор остаётся неясным, каким образом он мог создавать настолько фотореалитичные картины за полтора века до изобретения фотографии.
Как эксперт по компьютерной графике Тим Дженисон был уверен, что художник использовал какую-то технику захвата изображений, в том числе с копированием цвета. На это явно указывают некоторые детали картин. Например, текстура белой стены на картине «Урок музыки».
Две недели назад власти Китая представили ряд новых правил для регулирования деятельности онлайн-рекламы и некоторых других сфер, связанных с интернетом. Эти правила, судя по всему, больше всего скажутся на интернет-гигантах из Китая — Baidu и Alibaba.
Кроме того, новые правила, которые начнут действовать осенью этого года, запрещают еще и блокирование рекламы. Запрет на блокирование рекламы прописан в Статье 16. Первыми на это обратили внимание сотрудники AdBlokPlus — компании, которая разрабатывает блокировщик рекламы для браузеров — как для ПК, так и для мобильных устройств.
Решил я намедни найти роман Льва Николаевича Толстого «Война и мир» — думаю, пора уже без спешки его перечитать, вникнуть в каждую деталь. Ну, а заодно — разыскать для подрастающего поколения такую версию, где кроме номера главы есть ещё её краткое содержание типа «Глава такая-то, где ...» (незаменимая вещь для школьников, которым задают найти и разобрать тот или иной эпизод). Помню, у бабушки моей, учителя русского языка и литературы, был такой двухтомник — правда, до меня дошел только второй том (о первом её ученики «позаботились»). Не долго думая, вбил в поисковик запрос, прошёл по ссылке в библиотеку, нашёл полное собрание сочинений, в нём — нужный том, и вдруг… (На скриншоте — другое произведение Л.Н. Толстого. На самом деле, конкретно в том списке я прошёл по многим произведениям — все они оказались «обжалованы правообладателем». Когда решил всё-таки начать делать скриншоты и вплотную заняться этой темой, мой выбор пал на «Полное собрание сочинений, запрещённых цензурой» — так сказать, на злобу дня.)
То есть — оказывается, кто-то счёл себя правообладателем произведений Льва Николаевича Толстого (умершего, как известно, в 1910 году)… Это интересно, — подумал я, и начал разбираться. Подробности — под катом.
История развития Guifi — самой большой mesh-сети в мире
Городок Гурб (Gurb) расположен в 75 километрах к северу от Барселоны. Это небольшой населенный пункт, который в Испании назвали бы pueblo. Население — всего 2500 человек. Таких городков в стране много, но именно этот выделяется из ряда себе подобных. Дело в том, что здесь зародился проект Guifi.net. Этот проект — важный эксперимент в области телекоммуникаций. Он представляет собой общественную Mesh-сеть, которая уже давно вышла за пределы одного населенного пункта. Сейчас это крупнейшая сеть такого типа в мире.
Стартовал проект 12 лет назад, а сейчас сеть Guifi связывает десятки тысяч человек в сотнях различных населенных пунктах. Обычно пользователей к интернету централизованно подключают телекоммуникационные компании, но в Gurb и других городах участники проекта решили эту проблему самостоятельно. При этом сеть Guifi не зависит ни от правительства, ни от коммерческих компаний. Основная идея проекта — его участники должны сами определять, когда, где и как общаться. И пользователи очень довольны тем, как все работает.
Государство будет следить за безопасностью передачи данных в отечественном сегменте Сети
Фото: Дмитрий Коротаев / Коммерсантъ
Администрация президента сейчас ведет работу по созданию государственного удостоверяющего центра (УЦ), который будет выдавать сайтам в русскоязычном сегменте Сети государственные SSL-сертификаты, пишет «Коммерсант». «Огромное количество сайтов в рунете использует защищенное соединение: интернет-магазины, платежные системы, государственные сервисы, где пользователь вводит свои персональные данные. На государственном портале gosuslugi.ru используется SSL-сертификат, выданный УЦ американской компании Comodo, а на портале ФНС nalog.ru — SSL-сертификат от компании Thawte, принадлежащей Symantec. Если они по какой-то причине отзовут эти сертификаты, это может поставить под угрозу защищенную передачу данных в рунете»,— сообщил источник, близкий к администрации президента (АП).
О начале реализации такого проекта сообщил и глава Фонда информационной демократии Илья Массух. Он сказал, в частности, что создание УЦ бужет обсуждаться специальной рабочей группой «по использованию информационно-телекоммуникационной сети интернет в отечественной экономике». Эта группа создана в начале февраля этого года решением главы администрации президента Сергея Иванова. В рамках группы создана подгруппа «Интернет плюс суверенитет», в которой «будут вырабатываться предложения по созданию УЦ с учетом мнения экспертов и компаний-разработчиков отечественных браузеров — „Яндекс.Браузер“ и „Спутник“».
Депутат Ирина Яровая. Фото: Станислав Красильников / ТАСС
Сегодня президент РФ подписал принятый парламентом и Советом Федерации пакет Яровой-Озерова с поправками в российское законодательство, в том числе поправками в закон «О связи». Тем самым поставлена окончательная точка в обсуждении этого пакета, который подробно обсуждался на Хабре.
Пакет новых законов обязывает операторов связи до трёх лет хранить метаданные и до шести месяцев трафик.
Согласно принятым законам, инфраструктура для прослушки населения будет оплачена самим населением, скорее всего, за счёт повышения тарифов на связь и снижения нормы прибыли операторов. Насколько именно вырастут цены на связь? Здесь мнения экспертов расходятся.
Как современная молекулярная биология смотрит на феномен старения? Как пытаются старение изучать, есть ли надежды на замедление или даже остановку этого процесса? Этим вопросам была посвящена лекция биолога Александра Панчина, с которой он выступил на прошедшем в офисе Mail.Ru Group научно-популярном лектории Set Up.
D-Link является мировым производителем сетевого и телекоммуникационного оборудования. Изначально название звучало как Datex Systems, но в 1994 году оно было изменено на известное сейчас D-Link Corporation, компания-пионер среди компаний занимающихся телекоммуникациями. На данный момент занимается производством коммуникаторов Ethernet, беспроводного оборудования стандарта Wi-Fi, устройств семейства xDSL, IP-камер, преобразователей среды, маршрутизаторов, межсетевых экранов, сетевых адаптеров, оборудования VoIP, принт-серверов, переключателей KVM, модемов, накопителей NAS, SAN, а также оборудования GEPON.
В июне была обнаружена уязвимость в последней версии прошивки беспроводной облачной камеры D-Link DCS-930L, эксперты компании Senrio проэксплуатировали данную уязвимость,
Большинство математических обозначений существуют уже более пятисот лет. Я рассмотрю, как они разрабатывались, что было в античные и средневековые времена, какие обозначения вводили Лейбниц, Эйлер, Пеано и другие, как они получили распространение в 19 и 20 веках. Будет рассмотрен вопрос о схожести математических обозначений с тем, что объединяет обычные человеческие языки. Я расскажу об основных принципах, которые были обнаружены для обычных человеческих языков, какие из них применяются в математических обозначениях и какие нет.
Согласно историческим тенденциям, математическая нотация, как и естественный язык, могла бы оказаться невероятно сложной для понимания компьютером. Но за последние пять лет мы внедрили в Mathematica возможности к пониманию чего-то очень близкого к стандартной математической нотации. Я расскажу о ключевых идеях, которые сделали это возможным, а также о тех особенностях в математических обозначениях, которые мы попутно обнаружили.
Большие математические выражения — в отличии от фрагментов обычного текста — часто представляют собой результаты вычислений и создаются автоматически. Я расскажу об обработке подобных выражений и о том, что мы предприняли для того, чтобы сделать их более понятными для людей.
Традиционная математическая нотация представляет математические объекты, а не математические процессы. Я расскажу о попытках разработать нотацию для алгоритмов, об опыте реализации этого в APL, Mathematica, в программах для автоматических доказательств и других системах.
Обычный язык состоит их строк текста; математическая нотация часто также содержит двумерные структуры. Будет обсуждён вопрос о применении в математической нотации более общих структур и как они соотносятся с пределом познавательных возможностей людей.
Сфера приложения конкретного естественного языка обычно ограничивает сферу мышления тех, кто его использует. Я рассмотрю то, как традиционная математическая нотация ограничивает возможности математики, а также то, на что могут быть похожи обобщения математики.
Большинство из нас пользуется почтой от GMail, поэтому хорошо бы научить его шифрованию писем. К счастью, уже есть расширение для Google Chrome — SecureGmail.
По умолчанию npm публикует в registry весь модуль целиком. За исключением явно указанных в .gitignore файлов. Это отбрасывает зависимости, но все равно позволяет куче не очень нужных файлов просочиться в опубликованное. После чего благодарные пользователи ждут, пока все это скачается. Для grunt, кстати, ждать придется порядка 6 мегабайт. А он такой обычно не один.
Я решил разобраться, как измерить размер своих модулей после публикации и, по возможности, этот размер уменьшить. В качестве примера буду использовать модуль check-more-types, который содержит всего несколько файлов. Плюс юнит тесты и документацию, которая собирается в README markdown файл.
Anima — это душа, отличающая живое от мертвого. Аристотелевская душа — это принцип движения, проявляющегося в четырёх видах: перемещение, превращение, убывание и возрастание. Спустя почти две с половиной тысячи лет мы используем те же категории в компьютерной графике. Скелетная анимация определяет перемещение, морфинг служит для превращений, а убывание и возрастание это обычное масштабирование. Анимированная графика оживляет образ, вдыхает в картинку душу, и это, на мой взгляд, даже важнее, чем достоверная игра света и тени.
Создание качественных скелетных 3D анимаций сегодня, пожалуй, самая труднодоступная для инди разработчиков задача. Вероятно поэтому так мало инди игр в 3D, и так много проектов в стилях пиксель арта или примитивизма, а также бродилок без персонажей в кадре. Но теперь это соотношение может измениться…
Выступления и посты в блогах о производительности JavaScript часто обращают внимание на важность мономорфного кода, однако обычно не дается внятного никакого объяснения, что такое мономорфизм/полиморфизм и почему это имеет значение. Даже мои собственные выступления зачастую сводятся к дихотомии в стиле Невероятного Халка: «ОДИН ТИП ХОРОШО! ДВА ТИП ПЛОХО!». Неудивительно, что когда люди обращаются ко мне за советом по производительности, чаще всего они просят объяснить, что на самом деле такое мономорфизм, откуда берется полиморфизм и что в нем плохого.
Ситуацию осложняет еще и то, что само слово «полиморфизм» имеет множество значений. В классическом объектно-ориентированном программировании полиморфизм связан с созданием дочерних классов, в которых можно переопределить поведение базового класса. Программисты, работающие с Haskell, вместо этого подумают о параметрическом полиморфизме. Однако полиморфизм, о котором предупреждают в докладах о производительности JavaScript – это полиморфизм вызовов функции.
Я объяснял этот механизм столькими различными путями, что наконец-то собрался и написал данную статью: теперь можно будет не импровизировать, а просто дать на нее ссылку.
Я также попробовал новый способ объяснять вещи – изображая взаимодействие составных частей виртуальной машины в виде коротких комиксов. Кроме того, данная статья не покрывает некоторые детали, которые я посчитал незначительными, излишними или не связанными напрямую.
Для лучшего понимания этого поста, прочитайте сначала предыдущий пост про прокрастинацию.
Если бы, когда я учился в школе, вы спросили меня прокрастинатор ли я, я бы конечно ответил “да”. Учеников школы учат “держать темп” с крупными проектами. И я гордо держал темп больше чем кто-либо кого я знаю. Я никогда не пропускал дедлайн, но делал все ночью перед сроком сдачи работы. Я был прокрастинатором.
На самом деле я не был. Учебная программа в школе полна дедлайнов и коротких заданий. И даже долгие проекты состоят из промежуточных дедлайнов, которые не позволяют сильно расслабиться. Было всего несколько ужасных моментов, но в большинстве случаев, я все равно делал все в последнюю минуту, потому что знал, что все со мной будет хорошо, так почему бы нет.
Без всякого сомнения в моей голове была Обезьянка Немедленного Удовольствия, но она была милее всех на свете. С постоянно маячащими дедлайнами, Панический Монстр никогда не спал и Обезьянка знала об этом. Она конечно постоянно отвлекала, но не была за главного.
Я знаю людей, которые искренне недоумевают по поводу того, что функциональное программирование не очень популярно. К примеру, сейчас я читаю книжку «Из смоляной ямы» (Out of the Tar Pit), в которой авторы после аргументов в пользу функционального программирования говорят:
Статья про предыдущую версию Inkscape была очень тепло принята, что в связи с ближайшим выходом новой версии Inkscape 0.92 сподвигло меня описать ключевые особенности грядущего релиза. Сам релиз состоится в ближайшее время — во всяком случае пререлиз под *.nix уже тут.
Немного истории: пользователь ДевианАрт flutterguy317 форкнул Inkscape и пытался построить свой редактор Ponyscape с дружбой и магией до 4 февраля 2013 г., после чего проект был заморожен навсегда. И вот теперь, в версии Inkscape 0.92, появилась импортированная из Ponyscape иерархия документа. В связи с этим в иллюстрировании статьи будет немного арта из сообщества Ponyscape Vectors а так же много дружбы и магии.
Иллюстрация основана на работах flutterguy317 «Ponyscape» и Ambassad0r «No Time To Explain»
Статья от гендиректора Mail.Ru Group Дмитрия Гришина.
В советское время о космосе грезили миллионы людей в стране. Космонавты были народными героями. Это была мечта по умолчанию: в первую очередь все хотели быть космонавтами, искать новые планеты и цивилизации, ну а уже дальше возможны были варианты.
Да, советская космическая программа требовала гигантского количества ресурсов, и возможной ее сделала плановая экономика. Но кроме того она создавала мечту. А эта мечта стала тем топливом, на котором была создана великолепная инженерная школа. Не буду даже на этом останавливаться, но понятно, что и эту мечту, и эту школу мы во многом утратили. Да, многие российские инженеры по-прежнему получают качественное фундаментальное образование, но это остатки былой роскоши.
Мы перестали быть страной мечтателей, мы стали циничными и приземленными.
Разработка игры — само по себе непростое занятие. Но мультиплеерные игры создают совершенно новые проблемы, требующие разрешения. Забавно, что у наших проблем всего две причины: человеческая натура и законы физики. Законы физики привнесут проблемы из области теории относительности, а человеческая натура не даст нам доверять сообщениям с клиента.
Муж Дженнифер Нуль (Jennifer Null) до свадьбы предупреждал о проблемах в повседневной жизни, если она возьмёт его фамилию. Она представляла, что её ждёт — семья мужа постоянно шутила по этому поводу. И неудивительно, что проблемы начались сразу после свадьбы.
«Мы переезжали в новый дом, когда поженились, так что я занялась покупкой авиабилетов практически сразу, как сменила фамилию, — рассказывает Дженнифер Нуль. Покупка билетов оказалась непростой задачей: почти все сайты после заполнения формы почему-то возвращали сообщение об ошибке (поле «Фамилия» не заполнено, попробуйте ещё раз).
Генетически модифицированные организмы (ГМО) — организмы, чей генотип искусственно изменён при помощи методов генной инженерии. Изменения внесены целенаправленно, например, в случае сельскохозяйственных культур — повышение урожайности, улучшение вкуса и питательных ценностей продуктов, устойчивости к вредителям и т.д.
В 2015 году генетически модифицированные культуры составили 99% собранного в США урожая сахарной свеклы, 94% соевых бобов, 94% хлопка и 92% кормовой кукурузы.
В мире 12% всех пахотных земель занято ГМ-культурами.
С 1970-х годов учёные изучают потенциальные риски, связанные с использованием ГМО. Чтобы прояснить этот вопрос, Американские академии наук, техники и медицины организовали самое масштабное на сегодняшний день исследование почти 900 научных статей, опубликованных за последние 30 лет, на тему влияния ГМ-культур на организм человека и окружающую среду. Анализ статей продолжался два года комитетом из 50 учёных, исследователей и специалистов от сельского хозяйства и биотехнологий. Документ рецензировали 26 независимых экспертов.
Их давали нам, чтобы не мешали старшим чтобы котелок и мелкая моторика шли рука об руку. Но фишка конструкторов не только в этом.
Мы решили разобраться, в чем еще состоит польза от конструкторов, сказывается ли она на взрослой жизни — и как наверстать упущенное, если от пирамидки вы перешли сразу к 8-часовому рабочему дню.
Для начала, что называть конструктором? Например, пирамидки, паззлы, сортеры (когда детальке надо найти формочку), матрешки — это не конструкторы. Они называются «дидактическими игрушками» и учат работать по шаблону. Это, конечно, полезно и важно, но как тренировка. Поэтому иногда так хочется дать по рукам подтолкнуть ребенка, чтобы «закончили упражнение».
Настоящие конструкторы задумывались такими, чтобы человек работал в своем темпе и не до конца следовал шаблону.
Знакомьтесь, это Маня. Маню поразил страшный недуг и теперь она нуждается в вашей помощи. Маня росла обычной девочкой, жизнерадостным счастливым ребенком. Но чуть больше года назад врачи поставили ей страшный диагноз — алиазинг. И она стала выглядеть вот так.
Как выяснилось, виной тому стала жадность и алчность производителей браузеров, которые решили сэкономить на алгоритмах ресайза изображений и применить самые низкокачественные фильтры. Тогда Маню удалось спасти — она прошла курс последовательных не кратных двум уменьшений, что снизило алиазинг и вернуло её былую резкость. Но теперь ей снова угрожает опасность.
В классификаторе хабов произошло изменение. Все многочисленные статьи про расширения Хрома теперь можно пометить этим хабом, что призываю сделать авторов ранее написанных статей. Кроме этого, по случаю праздника, хотел бы написать обзор об истории расширений и юзерскриптов Хрома, о том, как они сформировались и к какому виду пришли.
Думаю все знают про важность использования сложных, неподбираемых, разных, периодически сменяемых паролей, так же как и про проблемы с их запоминанием. В принципе существует относительно неплохое решение этой проблемы — программы, хранящие базу паролей в зашифрованном виде. Я хочу поделиться альтернативным решением, которое обладает некоторыми преимуществами над такими «запоминалками» паролей, в частности не требует доступа к файлу с шифрованной базой паролей. Основная идея в том, чтобы помнить один очень стойкий мастер-пароль, а пароли для отдельных аккаунтов генерировать из него с помощью криптографических функций. Кому интересны подробности — прошу под кат.
Предыдущая статья серии была посвящена теории парсинга исходников с использованием ANTLR и Roslyn. В ней было отмечено, что процесс сигнатурного анализа кода в нашем проекте PT Application Inspector разбит на следующие этапы:
парсинг в зависимое от языка представление (abstract syntax tree, AST);
преобразование AST в независимый от языка унифицированный формат (Unified AST, UAST);
непосредственное сопоставление с шаблонами, описанными на DSL.
Данная статья посвящена второму этапу, а именно: обработке AST с помощью стратегий Visitor и Listener, преобразованию AST в унифицированный формат, упрощению AST, а также алгоритму сопоставления древовидных структур.
В нашем проекте PT Application Inspector реализовано несколько подходов к анализу исходного кода на различных языках программирования:
поиск по сигнатурам;
исследование свойств математических моделей, полученных в результате статической абстрактной интерпретации кода;
динамический анализ развернутого приложения и верификация на нем результатов статического анализа.
Наш цикл статей посвящен структуре и принципам работы модуля сигнатурного поиска (PM, pattern matching). Преимущества такого анализатора — скорость работы, простота описания шаблонов и масштабируемость на другие языки. Среди недостатков можно выделить то, что модуль не в состоянии анализировать сложные уязвимости, требующие построения высокоуровневых моделей выполнения кода.
К разрабатываемому модулю были, в числе прочих, сформулированы следующие требования:
поддержка нескольких языков программирования и простое добавление новых;
поддержка анализа кода, содержащего синтаксические и семантические ошибки;
возможность описания шаблонов на универсальном языке (DSL, domain specific language).
В нашем случае все шаблоны описывают какие-либо уязвимости или недостатки в исходном коде.
Весь процесс анализа кода может быть разбит на следующие этапы:
парсинг в зависимое от языка представление (abstract syntax tree, AST);
преобразование AST в независимый от языка унифицированный формат;
непосредственное сопоставление с шаблонами, описанными на DSL.
Данная статья посвящена первому этапу, а именно: парсингу, сравнению функциональных возможностей и особенностей различных парсеров, применению теории на практике на примере грамматик Java, PHP, PLSQL, TSQL и даже C#. Остальные этапы будут рассмотрены в следующих публикациях.
Итак, что же такое shadow DOM: Shadow DOM (или теневая модель документа) — часть документа, реализующая инкапсуляцию в DOM дереве. Она (теневая модель) является частью документа и встраивается непосредственно внутрь страницы. Для упрощения отладки shadow DOM, в хроме можно включить отображение в веб-инспекторе (Settings — General — Show shadow DOM).
Надо заметить, что в стандарте реализуемая инкапсуляция называется функциональной, поскольку shadow DOM встраивается в документ и является одной из многих его частей, работающих «независимо» (более-менее независимо) друг от друга. Соответственно, при проектировании реализации, нужно было установить функциональные границы в дереве документа, чтобы как-то оперировать с множеством таких «независимых» фрагментов. Для решения проблемы инкапсуляции, и была введена новая абстракция — shadow DOM, позволяющая создавать несколько DOM деревьев в пределах одного родительского дерева и был разработан документ, описывающий ее.
Мы почти полностью перевели проекты на векторную графику, хотя еще полгода назад были адептами символьных шрифтов (шучу, не такими уж и адептами). В статье я расскажу, с какими сложностями мы столкнулись в процессе, что из этого получилось, и почему вам стоит переходить на SVG уже в следующем проекте.
Принято считать, что есть «вечные» вопросы, на которые нет правильного ответа. Например, что лучше: Windows или Linux, Java или C#; Чужой против Хищника или Чак Норрис против Ван Дамма.
Одним из таких холиваров считается выбор лучшей IDE для Java:
Идут постоянные споры о том, в которой из них больше плагинов, горячих клавиш и т.д. Различий так много, что трудно выбрать, какие из них важнее, и все сходятся в одном: обе IDE примерно одинаковы по своим возможностям, и выбор одной из них — это дело вкуса.
Так вот, я утверждаю, что это не просто дело вкуса. Есть объективные причины, почему
Подчёркиваю, мы сейчас рассматриваем обе среды именно как Java IDE.
Я не буду приводить кучу мелких различий вроде плагинов, горячих клавиш и т.п. — этому посвящены многиестраницыв интернете, а объясню лишь одно, самое главное отличие. Как правило, о нём не знают ни идеяшники, ни эклипсофилы, ибо первые привыкли к нему и не знают, что в других IDE этого может и не быть, а вторые привыкли жить без него, и даже не догадываются, что может быть лучше. Более того, эклипсники его не замечают, когда пробуют IDEA ради интереса, ибо привыкли работать по-старому.
Продолжаю рассказывать про жизнь Inception architecture — архитеткуры Гугла для convnets. (первая часть — вот тут) Итак, проходит год, мужики публикуют успехи развития со времени GoogLeNet. Вот страшная картинка как выглядит финальная сеть: Что же за ужас там происходит?
На сайте Groklaw публикуется текстовая трансляция судебных слушаний Oracle против Google, где речь идёт о возмещении ущерба $150 тыс. за «воровство» для Android функции rangeCheck и тестовых файлов. В обсуждении встречаются интересные моменты. Например, вчера судья Алсуп, ведущий это дело, вступил в небольшую перепалку с адвокатом Дэвидом Бойзом, который представляет интересы Oracle: см. запись разговора.
Oracle: Вопрос не в том, насколько велик ущерб. Вопрос в том, можно ли закрыть глаза на коммерческую выгоду нарушителя исходя из того, что объём нарушений мал.
Кроме того, для меня не ясно, что справедливо сравнение девяти строк кода и 15 миллионов, потому что из них 10 миллионов составляет ядро Linux. Но всё равно, девять строк — это небольшой процент. Тестовые файлы гораздо больше, но они не присутствуют, по крайней мере, в текущей версии Android.
WebGL — одна из самых интересных новых технологий, которая способна удивительным образом преобразовать интернет. На базе этой технологии уже создано несколько движков, которые позволяют без лишних усилий создавать удивительные вещи, и наиболее известный из них Three.js. Познакомится с ним было моим давним желанием, и лучший способ сделать это — создать что-нибудь интересное. Первой идей было набросать “воодушевляющую” сцену на Three.js содержащую как большое количество полигонов, источников освещения и частиц, так и имеющую, при этом, какой-то осмысленный контекст. Вскоре, эта идея превратилась в желание создать бесконечный город в который можно было бы погрузиться сквозь браузер.
Стоит сказать, что статья посвящена не всему построению целиком, а лишь решению наиболее интересных проблем, с которыми пришлось столкнуться по мере создания сцены.
Высокий уровень стресса, низкий IQ, заниженная самооценка
Если вы думаете, что американцев не было на Луне, производители антивирусного ПО сами выпускают вирусы, нефтяные корпорации блокируют развитие альтернативной энергетики, а ГМО вызывает бесплодие, то вполне возможно, что у вас трудная жизнь и высокий уровень стресса, например, из-за проблем в личной жизни или экономического кризиса. Такой вывод можно сделать из нового научного исследования, результаты которого опубликованы в журнале Journal of Personality and Individual Differences.
Оптимизация кода начинается не столько с изучения особенностей языка программирования, сколько с понимания схемы работы всей «технологической цепочки», задействованной при создании приложения — от алгоритма программы до компилятора.
Мы поговорили с Вячеславом Егоровым aka mraleph, инженером из Google, компиляторщиком до мозга костей, который работал над JavaScript движком под названием V8, встроенным в Chromium (и, как следствие в Chrome, Android версию браузера, облачную операционную систему Chrome OS) и в менее известный Maxthone. JavaScript-программистам Вячеслав, скорее всего, известен как автор постов про внутренности V8 и как докладчик, увлеченно показывающий машинный код на конференциях для Web-разработчиков.
В настоящее время Вячеслав активно работает в Google над Dart VM. В этом интервью он рассказал о том, что происходит внутри движка, выполняющего динамический JS-код и поделился примерами, как выполняются некоторые оптимизации и почему важно глубоко понимать работу движка, чтобы обеспечить быстрое выполнение кода.
По результатам статьи «Пусковая петля»: — виртуально собрали денег 1.300.000 $, — «продали» больше 1.000 «билетов» в космос, — и обнаружили много много вопросов
Главное, что я заметил это то, что люди даже в мыслях ограничены, что существует огромное сопротивление, чтобы даже представить себе, как можно обеспечить СПРОС на объем запуска груза в космос в масштабе 6.000.000 тонн в год ?(при условии что стоимость запуска 1 кг груза будет стремиться к нулю)
Предлагаю всем людям творческим и не до конца творческим присоединиться к поиску созданию ответов и наполнить будущее смыслами. Do It Yourself
“Твои стрелы не долетают до мишени, — заметил мастер, — потому что они не летят достаточно далеко мысленно”.Юджин Херригел, “Дзен и искусство стрельбы из лука”
48 часов в пути, а то и больше, многие даже не знают, как можно провести столько времени за рулем. Они, конечно, догадываются, что существуют такие профессии как водитель грузовика – дальнобойщик, но, смею предположить, даже не думали о том, что такое долгая дорога и как проводить время за рулем. Я люблю путешествовать и люблю свой мотоцикл. Было время, когда я мог за сутки преодолевать до 1000 км. Это очень много, даже для такой страны как Россия.
Первое о чем стоит подумать человеку, кто едет очень далеко на собственном транспорте – это безопасность. В дальней дороге может случиться что угодно: аварии, поломки, внезапные проблемы со здоровьем, да и просто может кончиться бензин. Знайте, даже если вы аля волк-одиночка, есть люди, которым вы дороги, кто думает и переживает за вас.
Именно о решении, которое позволяет отслеживать транспортные средства в реальном времени мы и поговорим сегодня.
Недавно в Open Source выложили предварительно обученную нейросеть, которая умеет генерировать изображения, взяв за основу образец стиля с другого изображения. Таким образом, из карандашного наброска можно создать художественный шедевр в стиле Ренуара или Моне. Технология основана на свёрточной нейросети, разработанной в прошлом году в университете Тюбингена (о которой тоже рассказывали на Geektimes). Она правдоподобно подделывает художественный стиль известных художников, принимая на вход для обработки любые фотографии.
Интересные научные исследования привели к тому, что сейчас в интернете открылось несколько сервисов, рассчитанных на массовую публику. Не нужно теперь устанавливать Python 3.4+, библиотеки, скачивать нейросеть и настраивать окружение на локальном ПК, просто загружаем на сервер фотографии — и получаем результат.
Так вот, мультимодальное сканирование выявило, что один из самых мощных галлюциногенов, созданных человеком, не только воздействует на зрительную кору, как предполагалось ранее, но и связывает между собой различные районы мозга, которые обычно изолированы друг от друга! На иллюстрации вверху показано, как под влиянием ЛСД (справа) значительно увеличивается связь зрительной коры с другими районами. На левом снимке — мозг человека, принявшего плацебо.
Известная кибергруппа Hacking Team (@hackingteam), которая специализируется на разработке и продаже специального шпионского ПО для правоохранительных органов и спецслужб различных государств стала объектом кибератаки, в результате которой для общественности стал доступен архив с 400ГБ различной конфиденциальной информации. В сеть утекла личная переписка Hacking Team с их клиентами, заключенные договора на продажу своих кибер-изделий различным государствам, а также большое количество другой информации, связанной с деятельностью компании.
В результате утечки стало известно, что к услугам HT прибегали не только государственные структуры, но и частные компании. Также из опубликованных данных видно, что одним из клиентов HT были российские структуры или фирмы. Архив содержит и информацию о наработках кибергруппы (Exploit_Delivery_Network_android, Exploit_Delivery_Network_Windows), а также огромное количество различной поясняющей информации (wiki).
Я не понимаю причины существования бесконечных споров вокруг Объектно-ориентированного (ООП) и Функционального (ФП) программирования. Кажется, что такого рода вещи находятся за пределами человеческого понимая, и о них можно спорить бесконечно. Много лет занимаясь исследованием языков программирования, я увидел четкий ответ, и зачастую я нахожу бессмысленным обсуждение этих вопросов.
Если кратко, то как ООП, так и ФП неэффективны, если доходить в их использовании до крайности. Крайностью в ООП считается идея о том что “все что угодно является объектом” (чистое ОП). Крайностью для ФП можно рассматривать чистые функциональные языки программирования.
Я написал маленькую электронную книгу в которой рассматриваю вопросы как сделать код лучше. Книга ориентирована на Си/Си++ программистов, но будет интересна и разработчикам, использующих другие языки. Формат книги не подходит для моего любимого Хабра, но мне интересно получить обратную связь и обсудить мысли, изложенные в статье. Поэтому я решил разместить здесь только анонс, а с самой статьей можно познакомиться здесь. И приглашаю в комментарии для обсуждения.
Всем привет! На данный момент очень трендово использовать node.js. Однако не всем он нравится. В данном обзоре, я бы хотел рассказать немного о конкуренте, который был написан под влиянием node.js Vert.x это асинхронный, event-driven фреймворк, цели которого пересекаются с популярным node.js. Высокая производительность, простая асинхронность и конфигурирование — это все по vert.x. Первая версия фрейворка, была выпущена в 2012 году, в то время как node.js был выпущен в 2009. Однако, уже поддерживается VMware и может запускаться на CloudFoundry. Основные характеристики продукта под катом:
Это перевод статьи ребят из Aristotle Interactive. Говорят, фотография стоит тысячи слов. Но в сети, фотография может занимать тысячу килобайт и больше! По данным HTTP Archive, изображения в среднем занимают до 64% веб-страницы. Учитывая это, оптимизация изображений — крайне важный аспект, особенно принимая во внимание то, что многие пользователи просто уйдут с сайта, если он не загрузится за несколько секунд.
Проблема с оптимизацией изображений в том, что мы хотим сохранить размер изображений, не жертвуя при этом качеством. Предыдущие попытки создать типы файлов, которые бы оптимизировали изображения лучше, чем стандартные JPEG, PNG и GIF, успеха не возымели.
JPEG является стандартом в области компрессии изображений и это один из самых быстрых алгоритмов, но у него одна проблема: JPEG сжимает с потерей качества. Если фотография подвергается многократной обработке, это неприемлемо, и в таких случаях приходится искать альтернативу. Хочется чего-нибудь быстрого и при этом с приемлемой степенью сжатия.
Беглый взгляд на бенчмарки losless-алгоритмов на выборке фотографий не даёт оснований для радости: оказывается, PNG очень быстр на распаковке, но исключительно медленно работает на сжатии изображений.
Есть ещё JPEG-LS, хороший на первый взгляд. Но на него патент у компании HP, так что без шансов на использование. Немецкий программист Кристоф Фек (Christoph Feck) решил исправить ситуацию и выпустил свой алгоритм ImageZero сжатия фотографий без потери качества. Он примерно в 20 раз быстрее PNG, а по степени сжатия сравним с JPEG-LS.
FLIF (Free Lossless Image Format) — это новый свободный формат сжатия без потери качества, который превосходит PNG, lossless WebP, lossless BPG, lossless JPEG2000 и lossless JPEG XR по степени сжатия.
Как показало сравнительное тестирование (результаты), файлы FLIF в среднем:
на 14% меньше, чем lossless WebP,
на 22% меньше, чем lossless BPG,
на 33% меньше, чем PNG с брутфорсом через ZopfliPNG,
на 43% меньше типичного PNG,
на 46% меньше PNG, оптимизированного алгоритмом образования чересстрочного изображения Adam7,
Внимание! Реклама! Пост оплачен Капитаном Очевидность!
Ниже под катом вы найдёте 15 пунктов, описывающих правильную организацию ресурсов, доступных по протоколу HTTP — веб-сайтов, «ручек» бэкенда, API и прочая. «Правильный» здесь означает «соответствующий рекомендациям и спецификациям». Большая часть ниженаписанного почти дословно переведена из официальных стандартов, рекомендаций и best practices от IETF и W3C.
Вы не найдёте здесь абсолютно ничего неочевидного. Нет, серьёзно, каждый веб-разработчик теоретически эти 15 пунктов должен освоить где-то в районе junior developer-а и/или второго-третьего курса университета.
Однако на практике оказывается, что великое множество веб-разработчиков эти азы таки не усвоило. Читаешь документацию к иным API и рыдаешь. Уверен, что каждый читатель таки найдёт в этом списке что-то новое для себя.
CSS — не очень сложный язык. Но даже если вы пишете таблицы стилей в течении многих лет, наверняка бывают моменты, когда вы узнаете еще что-нибудь новенькое: свойства или значения, которые вам не доводилось использовать, детали спецификации, о которых вы не имели понятия.
В процессе работы с CSS я постоянно нахожу что-нибудь интересненькое, так что решил написать пост и поделиться своими знаниями с вами. Правда, учитывайте, что не всё, о чем будет рассказано, имеет непосредственное практическое значение, но, на всякий случай, в хозяйстве пригодится.
Microsoft опубликовала демо-страницу улучшенной типографики для формата OpenType. Это альтернативные глифы, лигатуры, кернинг, дроби, малые прописные и минускульные цифры. Эффекты видны, если наводить на текст мышкой. Демо хорошо работает только в браузерах с поддержкой OpenType, сама Microsoft рекомендует IE10+ и Firefox 8+. В других браузерах могут проявиться не все эффекты, это ещё зависит от операционной системы.
Альтернативные глифы и малые прописные
С Microsoft можно согласиться — OpenType действительно поднимает оформление текста в вебе на новый уровень, близкий к типографскому. Возможности этого формата явно превосходят @font-face.
Ранее мы уже рассмотрели общие вопросы использования HTML5 Audio и Video и начали погружаться в детали, начав с задачи определения поддержки браузером нужного кодека. Сегодня мы рассмотрим задачу создания собственного видео-плеера на HTML5 Video.
Напомню, что video-элемент сам по себе уже обеспечивает необходимый набор контролов для управления проигрыванием. Чтобы была видна панель управления воспроизведением, достаточно указать атрибут controls.
Однако, как я отмечал в вводной статье, со стандартными контролами есть проблема, которая заключается как раз в том, что выглядят они нестандартно. Другими словами, в каждом браузере они выглядят по-своему (проверить, как выглядят контролы в разных браузерах, можно на примере Video Format Support на ietestdrive.com — просто откройте его в двух-трех различных браузерах).
Наверное нет ни одного поля человеческой деятельности, столь полной разочарований и отвергнутых героев, как попытки создать термоядерную энергетику. Сотня концепций реакторов, десятки команд, которые последовательно становились фаворитами публики и госбюджетов, и наконец вроде определившийся в победитель в виде токамаков. И вот опять — достижения новосибирских ученых возрождают интерес по всему миру к концепции, жестоко растоптанной в 80х. А теперь подробнее.
Открытая ловушка ГДЛ, на которой получены впечатляющие результаты
Доброго времени суток! После опубликовании статьи о визуализации квадратичного дерева(Quad-tree), меня попросили написать статью, показывающую работу шейдера, переводящего изображение в «кофту».
Доброго времени суток, %username%! Маленькое исследование на тему «какой же способ поставить функцию/метод на обработку в очередь эффективнее» и, как результат, сравнительный тест, и итоговая реализация схожей с setImmediate функции. Этот метод нужен тем, кто хочет разбивать выполнение скрипта, чтобы тот не «подвешивал» браузер, что бывает полезно при огромном скрипте инициализации, разборе большого массива данных, построения сложной структуры не прибегая к WebWorkers.
Для понимания: setImmediate это метод объекта window, который должен вызвать функцию, переданную в неё, асинхронно, эдакий setTimeout(fn, 0), где 0 реально 0, а не минимум 4. Для nodejs-программистов это process.nextTick. Т.к. сам метод (setImmediate) имеет чёткий стандарт с ошибками и дополнительными параметрами, рассмотрим абстрактную задачу асинхронного выполнения переданной функции/метода как можно быстрее.
Исследования исключительно в рамках сценариев браузера, при чём основных, т.к. в работниках (workers) не совсем понятно зачем такое дробление, хотя если нужно, можно попробовать обещания и сообщения.
Итак, давайте узнаем, что же лучше подходит: postMessage, MutationObserver или Promise?
DOM Mutation Events в свое время казались отличной идеей — веб-разработчики начали создавать более динамичные приложения, и казалась естественной та радость с которой были встречены новые возможности прослушивать изменения DOM и реагировать на них. На практике, однако, оказалось, что у DOM Mutation Events имеются серьезные проблемы с производительностью и стабильностью. Не удивительно, что спецификация через год получила статус “устаревшей”.
Но сама идея, лежащая в основе DOM Mutation Events казалась привлекательной и поэтому в сентябре 2011 г. группа инженеров Google и Mozilla представила предложение о DOM MutationObserver, с похожей функциональностью, но улучшенной производительностью. Это новое DOM-API доступно начиная с версий: Firefox 14, Chrome 18, IE 11, Safari 6 (остальные браузеры — caniuse.com/mutationobserver)
Не совсем уже новость, но появился новый шрифт для программеров — Iosevka. Появляться он начал ещё осенью, но на Хабре упоминаний пока не было.
Iosevka — стройный моноширинный шрифт, вдохновлённый такими шрифтами, как Pragmata Pro, M+ и PF DIN Mono. Имеются варианты как с засечками, так и без, начертания с разными степенями жирности. Кириллица есть, само собой. Шрифт генерируется полностью из открытого исходного кода (при участии Node.js), путём настройки можно изменить начертание некторых знаков (таких как «a», «g», «l» и других).
Была глубокая ночь. В темную комнату через деревянные окна проникал лунный свет. Он недостаточно освещал мой деревянный стол с ноутбуком, блокнотом и синей ручкой. Поэтому я протянул свою руку к настольной лампе и включил её.
На компьютере был открыт текстовой файл со списком статей и библиотек про веб-разработку. Он постоянно пополнялся новыми данными.
Свернув его, я пошел на улицу в поисках кинотеатра с Deadpool'ом запустил браузер и стал блуждать по окрестностям интернета. Во время прогулки я наткнулся на интересную js-библиотеку по созданию css-анимации, которую добавил в открытый до этого текстовой документ… Как оказалось, по этой теме у меня уже набралось больше 40 ссылок на материалы и библиотеки.
ВОШ — эффект, возникающий при стилизации текста подключаемым шрифтом, не установленным на компьютере пользователя. Проявляется, когда подключаемый шрифт ещё не успел скачаться, и стилизуемый текст отображается следующим шрифтом из значения свойства font-family этого элемента. Такое переключение шрифтов также может повлиять на размеры элемента, если они зависят от размеров текста в нём. Эффект известен также как FOUT — так его назвал Пол Айриш.
При общих моментах, есть и особенности. Например, в Файрфоксе текст, который нужно будет отрисовать нестандартным шрифтом, в течение 3 секунд не отображается, в Хроме тоже есть подобная задержка. Если шрифт успеет скачаться за это время, текст отобразится сразу нужным шрифтом.
На эту тему здесь была такая статья. В ней последствия ВОШ рекомендовалось нивелировать грамотной игрой со шрифтами. К сожалению, иногда подключаются такие шрифты, которые слишком отличаются по характеристикам от стандартных.
Почти дождались! Свершилось! На JS можно играть flac файлы. В продолжение статьи от 2012 года я хочу более развёрнуто рассказать и описать, как же всё-таки использовать этот flac.js.
Всем привет, и ещё раз всех с прошедшими праздниками. Трудовые будни набирают обороты и вместе с ними растёт информационный голод мучающий нас. Мир разработки переднего конца не дремлет и готовит нам много сюрпризов в наступившем году, и уж поверьте мне, скучно не будет ни кому. Одна из новых особенностей которые нам готовят разработчики браузеров совместно с группами разработчиков пишущих спецификации — JavaScript Promises(далее в переводе — Обещания, прошу сильно не бить) — полюбившийся многим шаблон написания асинхронного кода обзаводится нативной поддержкой. Что же такое обещания и с чем их едят можно прочесть в нижеследующем переводе(слегка вольном) замечательной статьиДжейка Арчибальда.
Германия отличается даже от европейских соседей — в этой стране наиболее ревностно следят за соблюдением законов о защите приватных данных. Любые попытки внедрить отслеживающую технологию здесь могут наткнуться на судебный запрет. Немецкие домовладельцы заставляют Google удалять дома с фотографий Street View, снифферы в автомобилях Street View тоже впервые обнаружили именно в Германии. Даже функцию распознавания лиц на Facebook хотят поставить вне закона. А теперь в Германии нашли ещё одну онлайновую фичу, которая нарушает права граждан: это кнопка Facebook Like (Gefällt mir).
От переводчика: Я впервые попробовал перевести статью такого объёма и IT-тематики, с радостью прочту ваши комментарии и замечания. Что же касается самой статьи: я не согласен с автором как минимум потому, что, по сути, он заменяет REST на… REST (!!!), но немного в другом обрамлении. Однако, не смотря на то, что в статье преподносится много очевидных вещей, мне она показалась достойной обсуждения на Хабре.
Почему Вам стоит похоронить эту популярную технологию
Здравствуйте меня зовут Дмитрий. Я занимаюсь созданием компьютерных игр на Unreal Engine в качестве хобби. Моя игра имеет процедурно генерируемый мир, но для того чтобы создать более интересный уровень, я решил использовать заранее определенные участки уровня. Но возникает вопрос как задать участки где уровень будет генерироваться, а где нет. Для этого я создал собственный режим редактирования, под катом я опишу его создание, исходники в конце статьи.
В статье я собрал советы по использованию media query. Расскажу, как можно более эффективно использовать media query. В конце статьи есть список использованных источников.
Привет всем! По роду деятельности я программист на Java. Последние месяцы работы заставили меня познакомиться с разработкой под Android NDK и соответственно написание нативных приложений на С. Тут я столкнулся с проблемой оптимизации Linux библиотек. Многие оказались абсолютно не оптимизированы под ARM и сильно нагружали процессор. Ранее я практически не программировал на ассемблере, поэтому сначала было сложно начать изучать этот язык, но все же я решил попробовать. Эта статья написана, так сказать, от новичка для новичков. Я постараюсь описать те основы, которые уже изучил, надеюсь кого-то это заинтересует. Кроме того, буду рад конструктивной критике со стороны профессионалов.
Примечание от Робина Слоана, который опубликовал запись в своём блоге 15 марта 2016 года: «Этот рассказ появился в моём защищённом ящике в конце прошлого месяца, вместе с просьбой опубликовать его на Facebook сегодня именно в таком формате. Я не могу поручиться за подлинность истории, но она показалась мне достаточно странной и интересной».
#
Записывать всё это — последнее, что мне хочется делать, но это необходимо. Частично ради людей, которые обязаны знать, что происходит с их публикациями на Facebook, но главным образом (99%) ради Джули Рубикон и того пика на графике.
Мои бывшие коллеги из Facebook Inc. в Менло-Парк, Калифорния — привет, Джейн, привет, Нил, привет… Марк? — немедленно поймут, кто это написал, и компания вероятно будет преследовать меня, но я думаю, они провернут всё тихо. Комиссия по ценным бумагам не ограничится тихим расследованием, если действительно нарушены соответствующие правила и нормы, но честно… вряд ли такие правила существуют.
Несколько лет назад художница Кончетта Антико (Concetta Antico) осознала, что богатство красок, которое она видит в окружающем мире, недоступно для зрения остальных людей, а является результатом генетической мутации. Оказалось.что это симптом тетрахроматии — восприятия видимого диапазона спектра электромагнитного излучения комбинациями четырёх основных цветов, а не трёх цветов, как у нормальных людей.
Перевод отрывка из книги Джулиана Ассанжа «When Google Met WikiLeaks»: государственные перевороты, слежка, сговоры с правительством и другие будни корпорации добра.
Председатель совета директоров Google Эрик Шмидт делится шуткой с Хиллари Клинтон в ходе «непринужденной беседы» – специальной встречи с сотрудниками компании в главном офисе в Маунтин-Вью, Калифорния, 21 июля 2014 года
Google «другой». Google «зрит в будущее». Google «есть будущее». Google «больше, чем просто компания». Google «отдает дань обществу». Google – «сила добра».
Автор — Дэвид Хейни (David Haney), ведущий инженер-программист Stack Overflow
Итак, разработчики, время для серьёзного разговора. Вы уже наверное в курсе, что на этой неделе React, Babel и куча других популярных пакетов на NPM сломались. Причина довольно удивительная.
Простой пакет NPM под названием left-pad был установлен как зависимость в React, Babel и других пакетах. Модуль, который на момент написания этого поста, имеет 11 звёзд на Github (сейчас 323 — прим.пер). Весь пакет состоит из 11 простых строчек, которые реализуют примитивную функцию вставки пробелов в левой части строк. Если какие-то из ссылок когда-нибудь умрут, вот его код:
module.exports = leftpad;
function leftpad (str, len, ch) {
str = String(str);
var i = -1;
if (!ch && ch !== 0) ch = ' ';
len = len - str.length;
while (++i < len) {
str = ch + str;
}
return str;
}
Что меня беспокоит, так это такое большое количество пакетов, где установлена зависимость от простой функции набивки строки пробелами, вместо того чтобы потратить 2 минуты и написать эту базовую функцию самому.
Многие могут счесть спор, о том, что лучше пробелы или табуляции в коде за holy wars. Однако нет, я не хочу устраивать дискуссию на эту тему. Я однозначно утверждаю, что в обязательном порядке следует использовать пробелы. И разговор и «предпочтении того или иного» здесь не уместен. Как не уместно в наше время обсуждать, что удобнее, компьютер или печатная машинка. Поскольку печатные машинки закончили свое существование, ориентироваться в дальнейшем на их использование, по меньшей мере, нерационально. А если ещё учесть, сколь удобнее пользоваться компьютером для набора текста, то вопрос выбора просто отпадает.
С пробелами и табуляцией ситуация не настолько грандиозна и масштабна, но аналогия прослеживается. Далее я поясню, почему рационально перейти на пробелы для форматирования кода.
Автор оригинальной статьи Ali Mese добавил ещё 100 новых бесплатных сервисов. Все 400 потрясающих сервисов доступны здесь. И еще подборку +500 инструментов от 10 марта 2017 г. смотрите здесь.
A. Бесплатные Веб-Сайты + Логотипы + Хостинг + Выставление Счета
Существует несколько видов DOM-узлов, в частности Document, Element, Text и многие другие, которые формируют общий узел Node. Одним из наиболее интересных узлов является DocumentFragment, несмотря на то, что до настоящего момента он практически не использовался. Он, по большей части, является специальным контейнером для других узлов.
DocumentFragment обрабатывается в большинстве алгоритмов DOM особым образом. В этой статье мы рассмотрим некоторые методы API, разработанные для использования вместе с DocumentFragment. Также мы узнаем, что понятие контейнера узлов играет важную роль в прочих современных веб-технологиях, таких как элемент template или в API всего теневого DOM. Но прежде чем мы начнем, давайте вкратце рассмотрим парсинг фрагментов, который не связан напрямую с DocumentFragment.
Если много смотреть телевизор, то создаётся впечатление, будто люди там ненастоящие, а какие-то выдуманные виртуальные персонажи, говорящие головы, будто ими управляют как марионетками. Инновационная разработка учёных из США и Германии делает возможным именно такое дистанционное управление лицами на экранах.
Программа Face2Face накладывает мимику управляющего «актёра» на любое другое лицо. Это можно делать в прямом эфире и вставлять в видеотрансляцию. Лицо на телеэкране под управлением актёра способно отвечать на вопросы, хмурить брови и т.д.
В этой статье я подробно расскажу и покажу, как правильно и быстро прикрутить распознавание русской речи на движке Pocketsphinx (для iOS порт OpenEars) на реальном Hello World примере управления домашней техникой. Почему именно домашней техникой? Да потому что благодаря такому примеру можно оценить ту скорость и точность, которой можно добиться при использовании полностью локального распознавания речи без серверов типа Google ASR или Яндекс SpeechKit. К статье я также прилагаю все исходники программы и саму сборку под Android.
Известно, что дерево – довольно сложная структура. И если чтение успешно реализуется в том числе рекурсией (которая не лишена своих проблем), то с изменением дела обстоят совсем не хорошо.
При этом довольно давно существует высоко эффективный инструмент для работы с деревьями – зипперы, однако широкого распространения он не получил и, мне кажется, я знаю почему.
Классическое концептуальное объяснение зиппера, выглядит как-то так: это взгляд изнутри на древовидную структуру как бы вывернутую наизнанку, вроде вывернутой перчатки.
Это образное объяснение, если поскрипеть мозгами, обычно, конечно же, понимается только отчасти. Далее зипперы откладываются в сторону, потому что «это непонятная какая-то функциональная заморочка, типа монад, потом разберусь».
У автора «потом» уже наступило. Эта статья – попытка дать альтернативное объяснение зипперов (не путать с объяснением для альтернативно одаренных, хотя…) такое, что позволит быстро понять и немедленно начать использовать зипперы в практических задачах.
На Yet another Conference 2013 мы представили разработчикам нашу новую библиотеку Yandex SpeechKit. Это публичный API для распознавания речи, который могут использовать разработчики под Android и iOS. Скачать SpeechKit, а также ознакомиться с документацией, можно здесь.
Yandex SpeechKit позволяет напрямую обращаться к тому бэкэнду, который успешно применяется в мобильных приложениях Яндекса. Мы достаточно долго развивали эту систему и сейчас правильно распознаем 94% слов в Навигаторе и Мобильных Картах, а также 84% слов в Мобильном Браузере. При этом на распознавание уходит чуть больше секунды. Это уже весьма достойное качество, и мы активно работаем над его улучшением.
Можно утверждать, что уже в скором времени голосовые интерфейсы практически не будут отличаться по надежности от классических способов ввода. Подробный рассказ о том, как нам удалось добиться таких результатов, и как устроена наша система, под катом.
Решил поделиться опытом интеграции Asterisk и сервиса Яндекса по распознаванию речи.
Загорелось моему заказчику внедрить в свою АТС фичу Voice2Text.
В качестве АТС использовался FreePBX.
Сразу в голову пришло использование сервисов распознавания речи от Google, но после нескольких часов безуспешных попыток добиться нужного результата решил попробовоть аналогичный сервис Яндекса.
Дроны делают нереальные вещи — они снимают захватывающие кадры в труднодоступных местах. RoboHunter предлагает вашему вниманию восьмерку лучших видео, сделанных с помощью дронов. Поехали!
Списки с пропусками — это структура данных, которая может применяться вместо сбалансированных деревьев. Благодаря тому, что алгоритм балансировки вероятностный, а не строгий, вставка и удаление элемента в списках с пропусками реализуется намного проще и значительно быстрее, чем в сбалансированных деревьях.
Списки с пропусками — это вероятностная альтернатива сбалансированным деревьям. Они балансируются с использованием генератора случайных чисел. Несмотря на то, что у списков с пропусками плохая производительность в худшем случае, не существует такой последовательности операций, при которой бы это происходило постоянно (примерно как в алгоритме быстрой сортировки со случайным выбором опорного элемента). Очень маловероятно, что эта структура данных значительно разбалансируется (например, для словаря размером более 250 элементов вероятность того, что поиск займёт в три раза больше ожидаемого времени, меньше одной миллионной).
Балансировать структуру данных вероятностно проще, чем явно обеспечивать баланс. Для многих задач списки пропуска это более естественное представление данных по сравнению с деревьями. Алгоритмы получаются более простыми для реализации и, на практике, более быстрыми по сравнению со сбалансированными деревьями. Кроме того, списки с пропусками очень эффективно используют память. Они могут быть реализованы так, чтобы на один элемент приходился в среднем примерно 1.33 указатель (или даже меньше) и не требуют хранения для каждого элемента дополнительной информации о балансе или приоритете.
Я хочу рассказать о простом способе оптимизации регулярных выражений, а точнее словарей. Я видел некоторые проекты, которые оптимизируют конечные автоматы, пакеты которые делают быструю разметку словаря в тексте, но так чтобы просто взять словарь и собрать регулярное выражение, которое можно было бы передать любому движку регулярных выражений — такого пока не видел.
В общем, наверное, как и другой любой начинающий JavaScript прогрммист (2 года назад), мне хотелось все реализовать своими руками. Так возникло ужасающее очень быстрое регулярное выражение из 280 символов.
Немного истории
Приблизительно полтора года назад, я узнал о библиотеке yass, которая была самым быстрым инструментом для поиска DOM элементов в JavaScript по CSS селекторам (ссылка на тесты). И тут у меня возник ужасный интерес. Я захотел придумать способ, который будет еще быстрее. В то время я как раз читал книгу «Регулярные выражения Библиотека программиста» второе издание от Дж. Фридла. И вот… Это было лето, я еще был студентом и у меня была масса времени. Работа закипела…
Это Norton Commander? Это Volkov Commander? Это Dos Navigator? Это Far Manager? Нет, это «Деодар» — новая рабочая среда для Линукс. Деодар хостится на GitHub, основан на Node.js, написан на JavaScript плюс немного C++. Распространяется по антилицензии Unlicense.org. Безвозмездно, то есть даром. В данной статье на большом количестве картинок и малом количестве пояснений вы можете ознакомится с тем, что уже есть. Да, «Деодар» — это такое дерево, Cedrus Deodara растёт высоко в горах, очень красивое.
Official translation (with a bit of polishing) is available here.
Пришла пора веселья, давайте для начала смотреть размер текущего кода:
geometry.cpp+.h — 218 строк
model.cpp+.h — 139 строк
our_gl.cpp+.h — 102 строки
main.cpp — 66 строк
Итого 525 строк. Ровно то, что я обещал в самом начале курса. И заметьте, что отрисовкой мы занимаемся только в our_gl и main, а это всего 168 строк, и нигде мы не вызывали сторонних библиотек, вся отрисовка сделана нами с нуля! Я напоминаю, что мой код нужен только для финального сравнения с вашим работающим кодом! По-хорошему, вы всё должны написать с нуля, если следуете этому циклу статей. Очень прошу, делайте самые безумные шейдеры и выкладывайте в комментарии картинки!!!
В своей предыдущей статье по оптимизации сайта на WordPress я рассказал об очень эффективном подходе к оптимизации за счёт кэширования страниц. В результате чего для незалогиненных пользователей время ожидания страницы клиентом (исключая время на установление TLS-сессии) сократилось с 820 мс до 30 мс (этот и все последующие замеры проводились с сервера, расположенного в том же городе, что и мой VDS), что, согласитесь, является отличным показателем. Однако, для залогиненных пользователей генерация страницы происходила по-прежнему долго — в среднем 770 мс на сервере. В этой части я расскажу о том, как я сократил это время до 65 мс, при этом полностью сохранив работоспособность пользовательского функционала.
Целью этой и предыдущей статей является моё желание показать возможность оптимизации сайтов не только на WordPress, а вообще любого веб-приложения. Поэтому я использую такое количество инструментов, и так детально разбираю их конфигурацию. Если же Вам просто нужно ускорить WordPress — установите плагин WP Super Cache. Если Вас, как и меня, интересуют технологии, позволяющие оптимизировать любой сайт, а также Вам интересно, что стоит учитывать при разработке веб-приложений, рассчитанных на высокие нагрузки — прошу под кат, но только после прочтения первой части — дорабатывать я буду ту же систему.
Привет всем. Публикую выдержки из вводного курса нашей компании по промышленному программированию. Если выдержки покажутся интересными хаброобществу, продолжу публиковать другие куски.
Курс этот предназначен прежде всего для junior developer'ов и позволяет повысить уровень аргументации в холиварах на тему «почему PHP (Java, Perl, Bash) отстой».
В данном курсе рассматривается поточная модель программирования, основанная на вычислительной машине Тьюринга, история возникновения современных ЯП, а так же область их применимости. А так же внятно и доступно объясняется что такое ООП и функциональное программирование.
Продолжаю выкладывать выдержки из вводного курса нашей компании по промышленному программированию.
Часть третья: Синтаксический сахар или история развития языков
В данной части расказывается история развития языков программирования, а так же доступно объясняется что такое ООП и функциональное программирование. Другие части можно найти тут.
Предоставленные ниже материалы затрагивают лишь основы, то самое начало, с которого можно стартовать человеку, решившему создать игру но не знающему с чего начать. Хорошим вариантом будет изучение соответствующей литературы, статей или же рассмотрения примеров уже готовых игр, а так же просмотр исходников разных программ и решений.
Данные материалы не претендуют на то, чтобы показать «как надо делать», они лишь помогут наглядно понять, что и как работает, а вот как правильно это сделать — решит только сам разработчик. Однако, кого-то эти материалы могут замотивировать на дальнейшую работу, так как они достаточно наглядны и объясняют простоту создания игр на JavaScript.
Наверное каждый продукт, интерфейс которого имеет более одного языка, сталкивался с проблемой организации процесса локализации.
На самом деле этот вопрос касается не только мультиязычных приложений. Далеко не всегда при проектировании фичи заранее проработаны все тексты, которые для нее понадобятся, поэтому очень часто разработчики используют «черновые» тексты, которые потом должны быть выверены и, при необходимости, переведены на другой язык. Обычно это выглядит так: «ну ты напиши пока что-нибудь там, потом подправим».
В данном обзоре я опишу свои впечатления от тестирования 7 онлайн-сервисов для локализации ПО и сравню их по основным показателям (см. таблицу в конце статьи).
Как-то утром, пробегая мимо славного урока, я подумал: «Это круто, только всё же кой-чего тут не хватает». Если надо много кода написать легко и быстро, то нужна нам, без сомнений, для сего библиотека. Только как её нам выбрать, если каждый, кто умеет на гитхабе заводить репозиторий, запилил велосипед свой? И об этом для тебя, друг, напишу сегодня пост вдруг.
Вопрос “Зачем?” — самый главный при принятии любого решения. В нашем случае причин было несколько.
Во-первых, люди. Текущий шаблонизатор обрабатывался Си. Все вопросы о его изменениях решались не быстро. А самое главное, что писали шаблонизатор одни люди, а использовали совсем другие.
Вообще это частая и, на мой взгляд, не очень хорошая практика написания инструментов для верстальщиков. Понятно, что им нужны инструменты, но реализуют эти инструменты люди, которые весьма отдаленно себе представляют ежедневные задачи верстальщиков. Скорее наоборот, часто принимаются решения плана «дадим им писать условия и циклы, а больше на верстке ничего понадобится не может». Возможно, это вина самих верстальщиков и их квалификации.
Но в Mail.Ru Group есть целая команда высококвалифицированных людей, знающих JS, способных самостоятельно написать инструмент, а самое главное — они же им и будут пользоваться.
Во-вторых, задачи. Возьмем проект Почта@Mail.ru. Мы не можем отказаться от шаблонизации на сервере – нам нужна быстрая загрузка при первом входе. Мы не можем отказаться от шаблонизации на клиенте – люди должны видеть высокую скорость реакции на их действия, а значит, обязателен AJAX и шаблонизация на клиенте.
Проблема очевидна: два набора совершенно разных шаблонов на сервере и на клиенте. А самое обидное, что решают они одну и ту же задачу. Дублирование логики нас просто измотало.
v8 — это интерпретатор JavaScript, а значит, мы можем получить один шаблон, который работает как на сервере, так и на клиенте.
В-третьих, скорость. Прочитав много статей, в которых хвалят скорость v8, решили, что надо проверить их справедливость. Но сначала нужно было понять, каким мы хотим видеть новый шаблонизатор.
В этом посте изложены советы, как не написать код, производительность которого окажется гораздо ниже ожидаемой. Особенно это касается ситуаций, когда движок V8 (используемый в Node.js, Opera, Chromium и т. д.) отказывается оптимизировать какие-то функции.
Известный специалист по серверной и клиентской оптимизации, соавтор WebRTC, автор книги "High Perfomance Browser Networking" Илья Григорик из Google опубликовал презентацию “HTTP/2 all the things!”, в которой объясняет, как следует настраивать серверную часть под HTTP 2.0, чтобы повысить скорость загрузки страниц и уменьшить latency, по сравнению с HTTP 1.1.
Режим Connection View в браузере показывает загрузку элементов заглавной страницы Yahoo.com в HTTP 1.1
Илья начинает с того, что для современных сайтов бóльшая часть задержек приходится на ожидание загрузки ресурсов, при этом полоса пропускания не является ограничивающим фактором (синим цветом на диаграмме Connection View). По статистике, для загрузки средней веб-страницы браузер делает 78 запросов к 12 различным хостам (общий размер загружаемых файлов 1232 КБ).
Данная статья является лиш исследованием на тему и не должна использоваться как инструкция к действию.
Блокировки продолжаются а я всё также не приветствую отдачу не шифрованного HTTP трафика в заморские прокси, Tor, анонимайзеры и включение экономии трафика в браузере. Пока есть возможность я буду пытаться ходить на сайты прямо. Заодно скорость связи с сайтом не будет зависеть от загруженности стороннего сервиса.
Я поставил на Firefox плагин RequestPolicy и обнаружил в HTTP хедерах на сайте.
X-Squid-Error:"403 Access Denied"
Это значит что соединение к сайту проходит через прозрачный прокси.
В этой статье я попробую пройти при помощи локального прокси написанного на Lua (Вики)
Скачав LuaSocket 2.0.2 я написал небольшой скрипт локального прокси.
Данная статья является лиш исследованием на тему и не должна использоваться как инструкция к действию.
В связи с разгулом банхамера по интернет просторам участились советы по использованию различных прокси, vpn, tor и анонимайзеров. Эти все способы отправляют трафик третей стороне которая его может перехватывать и модифицировать. Это не наш метод. Мы сейчас просто и легко научим браузер дурить DPI.
Я вдохновился этой статьёй и сообразил относительно лёгкий способ ходить на сайты прямо не используя чужие прокси, дополнения и программы.
я осуществил необратимые манипуляции с доменным именем таким образом, чтобы не существовало ни одного достоверного и однозначного алгоритма обращения получившейся хеш-функции.
Сегодня на специальной пресс-коференции ученые международной коллаборации LVC (LIGO) объявили о первом прямом детектировании гравитационных волн от слияния двух черных дыр с достоверностью 5.1σ.
UPDЗапись пресс-конференции — историческое видео теперь. Кстати, отлично объясняю, что к чему. Еще добавил в конец статьи больше ссылок на материалы.
14 сентября 2015 год в 09:50:45 UTC два детектора LIGO (расположенные в США) одновременно наблюдали гравитационно-волновой сигнал GW150914. Сигнал с возрастающей частотой от 35 Гц до 250 Гц и амплитудой деформации метрики в 1x10-21. Сигнал соответствует предсказаниям Общей Теории Относительности (ОТО) для слияния двух черных дыр массами 36 и 29 солнечной.
Что еще интереснее, это открытие впервые позволяет с уверенностью сказать о существовании систем черных дыр, и характеризовать динамику системы черных дыр с позиций ОТО.
Скорость сайта состоит из 2 частей: как быстро загружается страница и как быстро работает код в ней. Многие сервисы, такие как минификаторы или CDN, помогают ускорить загрузку, но скорость работы кода зависит только от вас.
Небольшие изменения в коде могут давать огромные изменения в производительности. Всего несколько строк могут означать разницу между быстрым сайтом и диалогом “Unresponsive Script”.
Чтобы создать эффект движения нужно повторить слегка измененную картинку с достаточно высокой скоростью. Например в кино эта скорость составляет 24 кадра в секунду. Чем она выше, тем движение выглядит плавнее.
Люди встречаются, люди ссорятся, добавляются и удаляют друзей в социальных сетях. Этот пост о математике и алгоритмах, красивой теории, любви и ненависти в этом непостоянном мире. Этот пост о поиске компонент связности в динамических графах.
Большой мир генерирует большие данные. Вот и на нашу голову свалился большой граф. Настолько большой, что мы можем удержать в памяти его вершины, но не ребра. Кроме того, относительно графа приходят обновления – какое ребро добавить, какое удалить. Можно сказать, что каждое такое обновление мы видим в первый и последний раз. В таких условиях необходимо найти компоненты связности.
Поиск в глубину/ширину здесь не пройдут просто потому, что весь граф в памяти не удержать. Система непересекающихся множеств могла бы сильно помочь, если бы ребра в графе только добавлялись. Что же делать в общем случае?
VS Code (Visual Studio Code) — относительно новый текстовый редактор, выпущенный Microsoft. Он, также как и Atom, основывается на облочке Electron (написанной командой Atom), кардинально отличаясь реализацией самого редактора.
VS Code обладает своими уникальными фичами, такими, как, например, IntelliSense "из-коробки".
В этой статье я бы хотел поделиться тем, что нашел для себя полезным в VS Code для веб-разработки.
В знак протеста против устарелой традиции цензуры кинофильмов британский режиссёр Чарли Лайн (Charlie Lyne) снял фильм… как сохнет краска. Прикол в том, что это многочасовой фильм. По закону цензоры обязаны просмотреть каждую минуту.
Seam carving это алгоритм для изменения размера картинки, сохраняющий важный контент и удаляющий менее значимый. Он был описан в статье S. Avidan & A. Shamir. Он дает лучший результат, чем обычное растягивание изображения ввиду того, что не меняет пропорций значимых элементов изображения. Две фотографии ниже демонстрируют работу алгоритма – исходное изображение имеет размер 332x480, в то время как модифицированное seam carving'ом 272x400. В данной статье я опишу работу алгоритма используя псевдокод и код Matlab. Оригинал статьи, написанный мной на английском доступен тут, исходный код на гитхабе.
Наука всегда привлекала к себе мошенников и аферистов. В прошлые века в патентные ведомства поступали сотни заявок на патенты с вечными двигателями, пока такое «изобретение» не запретили в принципе. Теперь распространяются псевдонаучные журналы, которые принимают к публикации что угодно, любые статьи, даже от генератора текстов. Качество генераторов текстов так высоко, что такие статьи принимают даже серьёзные научные издательства — таким образом их троллят математики и программисты.
Кроме псевдонаучных журналов, действуют и псевдонаучные организации вроде РАЕН (Российская академия естественных наук), очень похожие на нормальные научные учреждения.
Поводом к переводу статьи стало то, что я искал книгу автора «The Outer Limits of Reason». Спиратить книгу я так и не смог, зато наткнулся на статью, которая в довольно сжатом виде показывает взгляд автора на проблему.
Вступление
Одна из самых интересных проблем философии науки — это связь математики и физической реальности. Почему математика так хорошо описывает происходящее во вселенной? Ведь многие области математики были сформированы без какого-либо участия физики, однако, как в итоге оказалось, они стали основой в описании некоторых физических законов. Как это можно объяснить?
Итак, кто не против, чтобы одежду ему подбирала программа, машина, нейросеть?
Любой набор изображений возможно проанализировать с помощью метода главных компонент. Этот метод уже довольно успешно применяется при распознавании лиц. Мы же попробуем использовать его на примере женских платьев.
Как мы все видим, ситуация со свободой интернета в России ухудшается, что было невообразимо вчера, уже вызывает смех сегодня. Палка уже на полметра вошла в маршрутизатор, создав ограничение, но есть еще такие же пол метра, до кнопки выключения.
В данном посте я постараюсь объективно описать с технической точки зрения разные сценарии и последствия после введения Великикого Российского Фаервола.
Недавно мы в Alconost сделали несколько видеороликов для игр и во время работы над ними столкнулись с повторяющимися вопросами клиентов: что показывать в ролике, делать ли ролик с голосом диктора или без, как недорого перевести ролик на несколько языков, какие исходные материалы нужны, как сделать видеозахват экрана мобильного девайса… Чтобы ответить на эти животрепещущие вопросы раз и навсегда, мы хотим рассказать и на конкретных примерах показать, как мы делаем видеоролики для игр.
Наш опыт будет полезен как тем, кто пробует делать видео самостоятельно, так и тем, кто собирается аутсорсить создание видеоролика для своей игры.
Итак, чтобы сделать видео для игры, надо пройти следующий путь:
Выбор типа ролика
Первое, о чем мы спрашиваем клиента — “зачем вам видеоролик?” В зависимости от ответа предлагаем один из типов видео:
- Ролик-тизер. Не показывает геймплей, не говорит ничего конкретного про игру, но создает интерес к игре, дразнит зрителя.
О локализации без боли мечтает каждый, кто знает, что такое локализация. Особенно мечтает тот, кому нужно перевести свой продукт сразу на десяток языков. И тот, у кого в текстах сплошные термины. И еще сильнее тот, у кого постоянно выпускаются обновления с новыми строками, которые с тем же постоянством надо переводить, переводить, переводить…
Кадр из фильма Леонида Гайдая «Кавказская пленница, или Новые приключения Шурика»
С этими и другими сложностями мы в Alconost справляемся благодаря одному-единственному инструменту, который решает сразу десяток проблем. Медики назвали бы такую штуку панацеей. А мы, локализаторы, зовем ее облачной платформой Crowdin. Именно Crowdin позволил нам делать локализации приложений, сайтов и игр на 40 с лишним языков для десятков разных клиентов одновременно.
Итак, мы выделили шесть основных сложностей локализации, от которых избавляет Crowdin:
Вам знакома такая архитектура? Хоровод демонов, пляшущих между web-server, cache и storage.
Какие минусы такой архитектуры можно отметить? Решая задачи в рамках такой архитектуры, мы сталкиваемся с кучей вопросов: какой язык(и?) взять, какой I/O framework выбрать, как синхронизировать cache и storage? Куча инфраструктурных вопросов. А зачем решать инфраструктурные вопросы, когда надо решить задачу? Безусловно, можно сказать, что нам нравятся некие технологии X и Y, и перевести эти минусы в рамки идеологических. Но нельзя отрицать тот факт, что данные располагаются на неком расстоянии от кода (картинка выше), что добавляет latency, что может уменьшить RPS.
Цель данной статьи — рассказать об альтернативе, которая построена на базе Nginx как web-server, bаlancer и Tarantool как App Server, Cache, Storage.
Эта статья является логическим продолжением моей предыдущей статьи, посвященной основам CSS3 transitions и, если в ней я показывала принципы работы этих основ на простых примерах, сейчас я хотела бы перейти к более сложным, красивым и интересным эффектам.
Демо материалы лежат здесь. Все префиксы проставлены в демо, здесь же я не буду на них акцентировать.
Предупреждение: эффекты работают только в современных браузерах, поддерживающих возможности CSS3.
Подготовка к работе.
Для создания эффектов понадобится такая дефолтная html-структура. Вместо .eff в коде каждого конкретного эффекта будет использоваться класс .eff-n, где n — номер эффекта:
<div class="eff">
<img src="img/ef1.jpg" alt="Effect #1" />
<div class="caption">
<h4>Title is Here</h4>
<p>
Lorem ipsum dolor sit amet, consetetur sadipscing elitr, sed diam nonumy eirmod tempor invidunt ut.
</p>
<a class="btn" href="#" title="View More">View More</a>
</div>
</div>
To follow the path: look to the master, follow the master, walk with the master, see through the master, become the master.
«Лучший способ писать — это переписывать» Пол Грэм, «The Age of the Essay»
Преред курсом Сергея Абдульманова ( milfgard) я взял для себя квест — структурировать все статьи Грэма. Пол не только крутой программист и инвестор — он мастер лаконичного письма. Если milfgard назвал свой курс для контент-менеджеров "Буквы, которые стреляют в голову", то Пол Грэм стреляет из «по глазам» (кто играл в Fallout 2 тот поймет).
А еще мне захотелось освоить Lisp. Чисто так, чтобы мозг поразвивать, потому что крутые люди — Грэм, Кей и Рэймонд, Моррис — говорят хором: «Учите Lisp».
На данный момент Пол Грэм написал (по крайней мере, я нашел) 167 эссе. Из них на русский переведены 69.74(+10). Если читать по 1 статье в день (что очень хороший результат, потому что я после одной статьи хожу задумчивый неделю — голова кипит как после отличного мастер-класса, а иногда и как после двухдневного интенсива), то процесс займет полгода.
Под катом — список всех статей со ссылками на оригинал и с переводом (если он есть). Подборка живая (так что, как обычно, добавляйте в избранное, потом прочитаете) и будет дополняться по мере обнаружения свежака. Еще вы найдете переведенную на 8/15 книгу «Хакеры и художники» и 4/25 перевода книги «On Lisp». Так же я приведу свою подборку топ-5 статей Пола Грэма, с которых я бы рекомендовал начать знакомство с этим автором.
«Дух сопротивления правительству так ценен в определенных случаях, что мне бы хотелось, чтобы ему никогда не давали погаснуть». Томас Джефферсон, отец-основатель.
(На картинке изображены Стив Джобс и Стив Возняк с их проектом «blue box». Фото сделано Маргрет Возняк. Предоставлено с разрешения Стива Возняка.)
В СМИ слово «хакер» используют для описания того, кто взламывает компьютеры. В среде разработчиков программного обеспечения это слово означает искусного программиста. Но между этими двумя понятиями существует связь. Для программистов «хакер» ассоциируется с мастерством в самом буквальном смысле слова: некто, кто может заставить компьютер делать то, что ему заблагорассудится, хочет того сам компьютер или нет.
В дополнение к этой путанице укажем, что существительное «hack» (англ.) также имеет два значения. Это слово может быть как комплиментом, так и оскорблением. Слово «hack» используется для описания ужасного результата вашей деятельности. Но когда вы совершаете что-то так талантливо, что каким-то образом побеждаете систему, то это также называют «hack». Данное слово употребляется чаще всего в первом значении, а не во втором, вероятно, потому, что плохие решения преобладают над блестящими.
Хотите — верьте, хотите — нет, но эти два значения слова «hack» также связаны. У плохих и оригинальных решений есть нечто общее: они оба идут вразрез с правилами. И существует постепенный переход от нарушения правил, граничащего с безобразностью (использование клейкой ленты для присоединения чего-либо к вашему велосипеду), к такому нарушению правил, что сродни блестяще оригинальному (отказ от Евклидового пространства).
Находясь под приятным впечатлением от кратенькой, но весьма остроумной и, не побоюсь этого слова, «культовой» программы, задался вопросом: «А можно ли сгенерировать подобную структуру в фоновом изображении сайта?». Захотелось создать бесконечный лабиринт, не повторяющийся в любом направлении. Вспомнил, где-то уже встречал метод, который и поможет мне любому стать Дедалом веб-дизайна.
Принцип цикады позволяет строить очень длинные неповторяющиеся фоны веб-страниц из нескольких простых изображений. Он был впервые описан Алексом Уокером в апреле 2011 года и быстро завоевал популярность. На сайте designfestival.com появилась целая галерея фонов, сделанных по этому принципу.
Во многих случаях можно сэкономить ещё больше, используя градиенты. Даже с учётом того, что пока практически все браузеры поддерживают свойство linear-gradient только с префиксами, суммарный объем кода CSS, необходимый для создания фона, в несколько раз меньше размера нескольких PNG с фрагментами, и, что ещё важнее — вообще не требует лишних запросов к серверу. Так, Эрик Мейер недавно привёл пример реализации первых двух фонов из оригинальной статьи Уокера на чистом CSS. Для простых цветных полосок (вверху) понадобилось 2.66 Кб кода CSS (с префиксами, без минификации и компрессии). В будущем, когда все популярные браузеры избавятся от префиксов, будет достаточно 0.59 Кб кода. В оригинальном примере изображения весили около 6 Кб + 3 запроса к серверу. Второй пример с занавесом (внизу) впечатляет ещё больше. Даже с префиксами получается примерно десятикратный выигрыш.
Соображения на тему использования режимов и состояний компонентов пользовательского интерфейса. Рассмотрим применение подхода при работе с препроцессорами стилей. Осторожно, в статье слишком много примеров кода.
Американские учёные из Университета Северной Каролины, находясь в поиске недорогой технологии производства искусственных алмазов, наткнулись в начале декабря на новую, неизвестную ранее форму углерода. Кристаллический углерод, названный учёными кью-углеродом [Q-carbon], плотнее и твёрже обычных алмазов, является ферромагнетиком и светится в темноте.
Считается, что в природе алмазы формируются на больших глубинах при сверхвысоких давлениях (как правило, 50000 атмосфер) и температурах (порядка 1200 ºC). Для создания синтетических алмазов, которые в основном и используются в промышленности, в лабораториях создаются похожие условия. Но такая технология требует огромных энергозатрат, что сказывается на конечной стоимости продукта.
Таких необычных для углеродных соединений свойств, какие обнаружились у кью-углерода, учёным удалось добиться благодаря новой технологии. При обычном атмосферном давлении некристаллический углерод разогревается сверхвысокочастотным лазером. После того, как углерод расплавится и достигнет температуры порядка 3700 ºC, лужицу очень быстро охлаждают.
Мы уже ранее затрагивали возможности модуля CSS3 Backgrounds and Borders, рассматривая работу с тенями (box-shadow). Сегодня мы немного поговорим о еще одной интересной возможности — использовании нескольких изображений в фоне.
Композиция фонов
Существует множество причин, по которым, вам вообще может потребоваться композиция нескольких изображений в фоне, среди них наиболее важные — это:
экономия трафика на размере изображений, если отдельные изображения в сумме весят меньше, чем изображение со сведенными слоями, и
необходимость независимого поведения отдельных слоев, например, при реализации эффектов паралакса.
В целом, системы управления реляционными базами данных были задуманы как «один-размер-подходит-всем решение для хранения и получения данных» на протяжении десятилетий. Но растущая необходимость в масштабируемости и новые требования приложений создали новые проблемы для традиционных систем управления РСУБД, включая некоторую неудовлетворенность подходом «один-размер-подходит-всем» в ряде масштабируемых приложений.
Ответом на это было новое поколение легковесных, высокопроизводительных баз данных, созданных для того, чтобы бросить вызов господству реляционных баз данных.
Мы обратили внимание на то, что едва ли не самой популярной публикацией в нашем блоге стал материал, посвященный патентным войнам (4800 просмотров), а вот подробный рассказ о том, как писать плагины для Fuel, к нашему удивлению, вызвал существенно меньший интерес (1000 просмотров первая часть и чуть больше 2000 — вторая).
В далеком 2011 году мир увидел такую игру как Minecraft — воксельную песочницу, где каждый творит все, что душе угодно. Спустя некоторое время народные умельцы стали писать различные модификации для нее, делающие геймплей более разнообразным. Не так давно появился мод под названием «OpenComputers», добавляющий полноценные компьютеры, программируемые на скриптовом языке Lua. И в этой статье я хочу поделиться с вами небольшим опытом, приобретенным при изучении этого крайне интересного мода.
Данная публикация является продолжением материала«Как происходит рендеринг кадра в GTA V». Теперь автор рассматривает вопросы детализации, освещения и пост-обработки кадра. Приятного чтения.
Уровень детализации
Если мы говорим об абсолютных преимуществах Rockstar над конкурентами, то показатели уровня детализации продуктов компании, определенно, выше всяких похвал. Лос-Сантос – это целая плеяда всевозможных сцен разной степени детализации/полигональности, причем все данные транслируются в режиме реального времени и это ни на минуту не блокирует экран загрузки. Просто дух захватывает!
Огни ночного города
Все огоньки, которые видны вдалеке, реальны. Вы можете подъехать ближе и увидите фонари, которые излучали свет на расстоянии.
Именно с таким заявлением Аарон Гарбут, один из основателей и арт-директоров Rockstar North, выступил незадолго до релиза игры на PS3.
Так ли это? Давайте рассмотрим вот такую ночную сцену:
Хотелось рассказать о том, как многими любимый Sublime Text можно использовать как неплохое средство для разработки на PL/SQL.
Хотелось бы начать с того, для чего нужен был этот велосипед, ведь есть вроде бы много других IDE для работы с SQL и в частности Oracle PL/SQL, такие как Toad for Oracle, SQL Navigator, PL/SQL Developer и даже бесплатный Oracle SQL Developer, однако у большинства из них есть несколько недостатков по сравнению с текстовыми редакторами типа Emacs, SciTe, Vim, Notepad++, Sublime Text и т.д.
Перечислю некоторые из них, данный список сугубо субъективный:
“Тяжеловесность” каждой IDE, это выражается не только в размере дистрибутива, но и общими ощущениями, наличием множества не нужных функций, кнопок, отзывчивостью и т.д.
Большинство приемлемых IDE являются платными, или условно бесплатными с ограниченным функционалом.
Хотелось бы кроссплатформенность, под это требование из приведенных IDE попадает только Oracle SQL Developer.
Функционал редактирования текста. В большинстве из них есть только базовые методы по работе с текстом: это набор текста, copy-paste, подсветка синтаксиса. Ни о каких “CTRL+D” как Sublime Text речи и не идет.
Простота расширения, практически все IDE закрыты, никакой поддержки самописных пагинов и т.д.
Есть еще один пункт, но он больше относится к организации проектов и задач на рабочем месте. Хотелось бы немного затронуть эту тему, так как организация на проектах наложила свой отпечаток на настройку Sublime Text.
На первый взгляд это обычные одноцветные иконки, но если призумить — их качество не ухудшится. Очевидный профит таких иконок: с ними можно свободно экспериментировать и не переживать за высоту и ширину, компактный вид, а не куча файлов в папке icons, ну и наверное маленький размер, хотя с этим поспорить можно. Есть некоторые ограничители в цвете, возможен один цвет либо градиент (но думаю с конвертером нарисованного вектора в js код, возможно и больше цветов)
Если вы хотите использовать эти иконки или создавать свои на подобной основе, кликайте по иконке — внизу появится код выбранной иконки, он вставляется в:
Серия игр Grand Theft Auto прошла долгий путь с момента своего первого релиза в 1997 году. Примерно 2 года назад Rockstar выпустила GTA V. Просто невероятный успех: за 24 часа игру купило 11 миллионов пользователей, побито 7 мировых рекордов подряд. Опробовав новинку на PS3, я был весьма впечатлен как общей картинкой, так и, собственно, техническими характеристиками игры.
Ничто так не портит впечатление от процесса, как экран загрузки, но в GTA V вы можете играть часами, преодолевая бескрайние сотни километров без перебоев. Учитывая передачу солидного потока информации и свойства PS3 (256 Mb оперативной памяти и видеокарта на 256 Mb), я и вовсе удивился, как меня не выбросило из игры на 20-ой минуте. Вот где чудеса техники.
В этой статье я расскажу о проведенном анализе кадра в версии для ПК в среде DirectX 11, которая съедает пару гигов как оперативки, так и графического процессора. Несмотря на то, что мой обзор идет со ссылкой на ПК, я уверен, что большинство пунктов применимо к PS4 и в определенной степени к PS3.
Анализ кадра
Итак, рассмотрим следующий кадр: Майкл на фоне любимого Rapid GT, на заднем плане прекрасный Лос-Сантос.
Начну издалека. С браузеров. Новинками браузеростроения интересуюсь не так уж и часто, но вот однажды, со скуки, решил посмотреть, что javascript грядущий нам готовит и что с этого нам могут предложить современные браузеры. Речь идет, само собой, не о ECMAScript 5, а уже о ECMAScript 6ECMAScript Harmony. Через пару минут серфинга я наткнулся на такую вот сводную табличку. Не самая актуальная — Chrome, например, довольно давно поддерживает Proxy. Само собой, разброд оказался еще тот. В браузере это использовать пока не реально. В браузере. А на сервере? На сервере нет необходимости поддерживать зоопарк различных браузеров. Node.js использует V8 — тот же javascript движок, что и Chrome, соответственно, он должен поддерживать те же новые возможности языка.
Обычный программист знает о Perl только то, что язык мертв,
а код на нем нечитаем. Но программист на Perl часто не знает даже этого.
В каждой начинающей рок-группе должен быть Perl-программист,
который бы демонстрацией своего кривого нечитаемого кода со сцены взывал
к низменным инстинктам толпы, разогревая ее.
Дань стереотипам.
Вопреки стереотипам Perl все еще существует. Он живет где-то на периферии сознания тех, кто не пишет на нем. Он вызывает у них сильное непонимание, когда они встречают тех, кто на нем пишет. Культура Perl настолько размазана по времени, настолько проникнута стабильностью языка, что человеку постороннему достаточно тяжело понять, что из себя представляет Perl сегодня. И как с ним нужно бороться.
Несметное множество статей на просторах интернета описывают Perl тех времен, когда небо было зеленым, трава голубой, а Ельцин в пьяном угаре радовал страну зажигательными танцами перед телекамерами, задавая ритм рейверам, что танцевали на той голубой траве и под тем зеленым небом. И код из тех статей все еще компилируется. В результате у большинства программистов представление об этом языке представлено информацией 10-15… и даже 20 летней давности. Не следуют упускать из виду инерционность мышления тех, кто писал те статьи.
Поэтому сегодня я попытаюсь пролить свет на то, что же происходит с языком на его начинающемся 28 году жизни. Ведь сегодня у Perl день рождения — ему 27 лет. 20 лет из которых существует его пятая версия. Заходите, будет весело.
Около шестнадцати лет назад вышла первая версия Hotspot – реализация JVM, впоследствии ставшая стандартной виртуальной машиной, поставляемой в комплекте JRE от Sun.
Основным отличием этой реализации стал JIT-компилятор, благодаря которому заявления про медленную Джаву во-многих случаях стали совсем несостоятельными. Сейчас почти все интерпретируемые платформы, такие как CLR, Python, Ruby, Perl, и даже замечательный язык программирования R, обзавелись своими реализациями JIT-трансляторов.
В рамках этой статьи я не планирую проливать свет на малоизвестные детали реализации промышленных JIT-компиляторов, скорее это будет совсем поверхностное ознакомление с азами и рассказ про учебный проект по соответствующей тематике.
Таким образом вам может быть интересно под катом, если:
Вы принципиально не понимаете, что такое JIT-компилятор, или у вас есть легкое непонимание, чем такой подход существенно лучше интерпретации.
Вы хотели бы написать простой JIT для своего интерпретируемого языка.
Вы преподаете курс «Языки программирования и компиляторы», и не против сделать практическое задание для студентов еще интересней.
Для Visual Studio 2010 создано уже около 900 дополнений. Многие из них позволяют облегчить решение рутинных задач, добавить удобства. Ниже представлено двадцать популярных дополнений, которые вы возможно найдете полезными для вашей работы.
Angular — зрелый и мощный JavaScript-фреймворк. Он довольно большой и основан на множестве новых концепций, которые необходимо освоить, чтобы работать с ним эффективно. Большинство разработчиков, знакомясь с Angular, сталкиваются с одними и теми же трудностями. Что конкретно делает функция digest? Какие существуют способы создания директив? Чем отличается сервис от провайдера?
Несмотря на то, что у Angular довольно хорошая документация, и существует куча сторонних ресурсов, нет лучшего способа изучить технологию, чем разобрать ее по кусочкам и вскрыть ее магию.
В этой серии статей я собираюсь воссоздать AngularJS с нуля. Мы сделаем это вместе шаг за шагом, в процессе чего, вы намного глубже поймете внутреннее устройство Angular.
Легендарный изобретатель шифровальных машин — Борис Цезарь Вильгельм Хагелин (1892 -1983).
Не существует приложений связи, где бы не были применены решения, разработанные фирмой Crypto AG, которую более чем 60 лет назад основал талантливый криптограф Борис Хагелин.
Номенклатура аппаратуры и программного обеспечения Crypto AG исключительно широка. Известна компания не только шифртехникой для правительственной и военной связи. В офисах большая часть ежедневного обмена сообщениями и данными всё ещё идёт по классическим каналам – PSTN/ISDN, аналоговой или цифровой телефонии и факсу. Конфиденциальность переговоров, факсов и информации в ноутбуках обеспечивается рядом аппаратных решений Crypto AG: PSTN Encryption HC-2203, Secure GSM HC-2423, Fax Ecryption HC-4221, Crypto PC Security HC-6360, Crypto Laptop HC-6835 и другими. Для военных и гражданских применений разработаны
Недавно я снова начал играть в Minecraft. Ванильный Minecraft несколько скучен, как по мне, и я всегда ищу модпаки (пакеты дополнений). В поисках новых модпаков я наткнулся на FTB Horizons: Daybreaker. Из списка содержащихся в нем модов мое внимание привлек мод OpenComputers.
Как можно предположить из названия, модуль OpenComputers добавляет в Minecraft компьютеры. Настоящие компьютеры! При этом они тоже модульные. Вы можете добавлять периферию: от мониторов до клавиатур и карт расширения, которые добавляют возможности такие как графика и сеть. И эти компьютеры могут быть запрограммированы на языке Lua, прямо в игре. И существует такой вид карт, как Интернет-карта, которая можете себе представить, может подключаться к Интернету реального мира. Неплохо.
Итак, что мы можем сделать примерно в один час свободного времени?
С появлением HTML5 у нас появляется много новых и интересных возможностей. Позволяющих создавать еще более качественные приложения.
Например, File API. Доступ к файлам клиента довольно удобная штука. Мы можем к примеру заполнить форму используя информацию из выбранного пользователем файла:
Книга «Refabricating Architecture», написанная Стефеном Кираном и Джеймсом Тимберлейком, в значительной степени повлияла на мое понимание дизайна. Авторы этой книги сравнивают архитектуру с автомобильной, аэрокосмической и кораблестроительной индустрией, обсуждая практически полную неизменность строительных процессов (с фундаментальной точки зрения) в рамках последних 80-ти лет на контрасте со стремительными переменами в других отраслях производства и дизайна.
В интернете можно найти много разной информации о создании чертежей в формате SVG. Чаще предлагается какой-то редактор и экспорт из формата DXF в SVG. Просматривая код SVG сразу видно что там много лишнего. Созданный в одном редакторе файл SVG не всегда может корректно открыться в другом. Одно радует, что браузеры начали поддерживать SVG формат. Всюду пишут про недостатки использования SVG. А может надо придерживаться единых правил структуры файла для отображения чертежей?
Эта история началась, когда мой друг и соратник, Яп Чэ-шень, сказал мне следующее:
— Я больше не хочу никогда в своей жизни писать на Дельфи! Я поклялся: больше ни единой строчки! С сегодняшнего дня все свои проекты и библиотеки перевожу на JavaScript!
Яп — китаец, с классическим менталитетом, свойственным его народу. Я многие годы работаю с ним над гуманитарными проектами в области оцифровки древней литературы, в первую очередь, «Буддийской библии» — Типитаки. Познания Япа, как в области самых древних текстов, так и самого современного программирования, не перестают удивлять меня уже более десяти лет — с тех пор, как мы начали сотрудничать и общаться на самые разные темы. Для себя я давно понял, что, если Яп что-то говорит, а я не согласен или не понимаю, то это лишь значит, что надо продолжать обсуждение, и вся громада причин и следствий в размышлениях моего друга выйдет на поверхность, и как всегда окажется, что Яп прав. Кажущаяся эмоциональность китайцев, на самом деле, необычайно рациональна.
Недавно мы в «Я люблю ИП» закончили курсы по дизайну от trydesignlab.com. И это одна из самых важных статей, которую нам посоветовал ментор в процессе обучения. Сегодня мы публикуем вторую часть перевода. Посмотреть все наши работы с курсов можно в ВКонтакте по тэгу #design101@iloveip.
Мы говорили о правилах создания чистых и красивых интерфейсов.
Примечание переводчика: Буквально вчера прочитал этот пост на TechCrunch. Я счел необходимым его перевести в первую очередь потому, что он применим не только к Штатам и не только к NSA, это пост скорее о сложных и запутанных отношениях между частной жизнью отдельного лица и тем, где государства видят границу этой частной жизни и национальной безопасности. P.S. Это мой первый перевод и первый пост. Я надеюсь, что им я сумею что-то привнести в сообщество, или хотя бы породить конструктивное обсуждение. Если в переводе найдутся ошибки, которые я не отловил — милости прошу в ЛС, постараюсь вносить исправления максимально оперативно.
Поддержка альтернативных потоков данных (AltDS) была добавлена в NTFS для совместимости с файловой системой HFS от Macintosh, которая использовала поток ресурсов для хранения иконок и другой информации о файле. Использование AltDS скрыто от пользователя и не доступно обычными средствами. Проводник и другие приложения работают со стандартным потоком и не могут читать данные из альтернативных. С помощью AltDS можно легко скрывать данные, которые не могут быть обнаружены стандартными проверками системы. Эта статья даст основную информацию о работе и определении AltDS.
Звук, как и цвет, люди воспринимают по-разному. Например, то, что кажется слишком громким или некачественным одним, может быть нормальным для других.
Для работы над Яндекс.Музыкой нам всегда важно помнить о разных тонкостях, которые таит в себе звук. Что такое громкость, как она меняется и от чего зависит? Как работают звуковые фильтры? Какие бывают шумы? Как меняется звук? Как люди его воспринимают.
Мы довольно много узнали обо всём этом, работая над нашим проектом, и сегодня я попробую описать на пальцах некоторые основные понятия, которые требуется знать, если вы имеете дело с цифровой обработкой звука. В этой статье нет серьёзной математики вроде быстрых преобразований Фурье и прочего — эти формулы несложно найти в сети. Я опишу суть и смысл вещей, с которыми придётся столкнуться.
Поводом для этого поста можете считать то, что мы добавили в приложения Яндекс.Музыки возможность слушать треки в высоком качестве (320kbps). А можете не считать. Итак.
После моего недавнего выступления на MoscowJS #17 с одноимённым докладом у многих возник интерес к этому инструменту. В рамках 11-го выпуска RadioJS, Миша Башкиров bashmish рассказал, что решился попробовать его в своём новом проекте, об успешном опыте и множестве положительных эмоций. Но были озвучены вопросы и возникла дискуссия, в результате которой я решил написать эту статью, чтобы раскрыть основные тезисы с доклада и рассказать о том, что тогда не успел. Статья ориентирована, как на профессионалов, так и на тех, кто с похожими технологиями ещё не сталкивался. Итак, начнём.
Данная статья зародилась в моей голове, после того, как нам выдали курсач по мультимедийным технологиям в универе. «Универ… пф-ф-ф...» — так подумает мой читатель. Да только иногда здесь бывают дельные вещи. Вот, почему.
В курсаче предполагается создание виртуального ландшафта в старенькой программе VistaPro. В силу того, что раньше я ни с чем подобным не работал, я не могу сказать, насколько она функциональная. Но её большой плюс заключается в том, что она крайне проста в использовании (а другие террагены подчас довольно нетривиальны, что может вызвать некоторые трудности. Час же работы может не гарантировать успеха, в отличие от моего антиквариата), а освоить её от и до: разобрать весь функционал можно меньше чем за день не зная до этого ровным счётом ничего о ней. Небольшим, но всё-таки плюсом является совсем малый вес (~3 МБ). Разумеется, сейчас есть много подобных террагенов, которые обгоняют по функциональности VistaPro.
На сегодняшний момент существует масса JavaScript-библиотек для создания rich-client приложений. Кроме всем известных Knockout, Angular.JS и Ember есть великое множество других фреймворков, и каждый имеет свою особенность — кто-то пропагандирует минимализм, а кто-то — идеологическую чистоту и соответствие философии MVC. При всём этом многообразии, регулярно появляются всё новые и новые библиотеки. Из последнего, что упоминалось на хабре — Warp9 и Matreshka.js. В связи с этим хочется рассказать о собственной поделке, встречайте, JohnSmith — простой и легковесный JavaScript фреймворк для построения UI.
Как-то мне надо было добавить в админку просмотр списка паролей. База хранилась на сервере в формате KeePass (kdbx v2), сервер был на ноде — недолго думая, я взял первый попавшийся пакет и сделал. А потом понадобилось то же самое, но прямо у пользователя в браузере, без сервера. Ничего не нашлось. Первым желанием было форкнуть либу и заменить использование node api, но от первого просмотра кода желание пропало, решил сделать сам.
Под катом расскажу о проблемах, с которыми я столкнулся, и способах их решения
В данной статье я хочу рассмотреть FileSystem API и File API, разобраться с его методами и показать пару полезных штук. Эта статья является компиляцией материалов с html5rocks (1, 2, 3). Все представленные ниже демки можно посмотреть по первым двум ссылкам. Третья ссылка так же предлагает ряд интересных демо. Ну а теперь займемся изучением материала.
Дизайн, как и мода, подвержен регулярным переменам. Но всё же есть направления, которые никогда не теряют свою популярность. Одним из них является минимализм. В последние годы бурно развивались HTML 5, CSS 3 и ряд других технологий, позволяющие сегодня создавать очень сложные веб-страницы. Тем не менее, минимализм в дизайне всё ещё очень востребован.
Начнём с пианино. Очень упрощёно этот музыкальный инструмент представляет собой набор белых и чёрных клавиш, при нажатии на каждую из которых извлекается определённый звук заранее заданной частоты от низкого до высокого. Конечно, каждый клавишный инструмент имеет свою уникальную тембральную окраску звучания, благодаря которой мы можем отличить, например, аккордеон от фортепиано, но если грубо обобщить, то каждая клавиша представляет собой просто генератор синусоидальных акустических волн определённой частоты.
Когда музыкант играет композицию, то он поочерёдно или одновременно зажимает и отпускает клавиши, в результате чего несколько синусоидальных сигналов накладываются друг на друга образуя рисунок. Именно этот рисунок воспринимается нами как мелодия, благодаря чему мы без труда узнаём одно произведение, исполняемое на различных инструментах в разных жанрах или даже непрофессионально напеваемое человеком.
Проблема размещения непрерывного контента произвольного объёма в экран, или окно, фиксированных размеров, существует несколько десятков лет. Примерно столько же существует и лучшее решение этой проблемы: элемент графического интерфейса — скроллбар.
Под катом можно узнать, как в ближайшее время будет работать скролл в 2ГИС Онлайн.
Добрый день, %username%. Сегодня я хотел бы поделится своим опытом разработки прототипа онлайн lossless аудио плеера.
На сегодняшний день, вряд ли можно кого-то удивить аудио или видео плеером, встроенного непосредственно в веб-страницу. Существующие технологии, библиотеки и API позволяют легко наполнить сайт любым медиа-контентом. Но есть такие люди, которым этого недостаточно (в том числе я). Именно поэтому, как истинному любителю музыки в lossless, мне потребовалось сделать браузерный плеер поддерживающий такой формат аудио, как flac.
Поддержка использования показателей акселерометра и гироскопа при помощи javascript – это технология, опередившая время. Тогда, в далеком 2010г., мобильный веб не был так развит. Адаптивность верстки не была обязательным пунктом (особенно в рунете), да и вообще сайты были предназначены в основном для просмотра на обычных мониторах. Сейчас же все по-другому, и доля мобильного трафика составляет чуть ли не 50%, но почему-то про эту крайне интересную и эффектную технологию до сих пор мало кто вспоминает. Попробуем исправить ситуацию.
Не так давно у меня появилась необходимость загружать конфигурацию приложения при очень ограниченных ресурсах. Не было доступа, практически, ни к каким стандартным функциям C. Очень повезло, что были стандартные функции по работе с памятью malloc()/free().
Сложилась следующая ситуация: конфигурация считывается из файла при загрузке приложения на системе с ограниченными ресурсами. Сама же конфигурация должна легко редактироваться на обычном компьютере вплоть до того, что необходимо будет поправить быстро несколько значения прямо на объекте при демонстрации заказчику.
Маленький рассказ о том, как наша команда решила организовать иконки в грядущем проекте. Чуть-чуть исторического экскурса, взгляды по сторонам (на PNG и векторные шрифты) и рассказ о том, как мы всё-таки обустроились в итоге.
Иконки у нас используются, и активно – хорошо подобранная иконка заменяет слова и предложения (а фигово подобранной иконке можно сделать всплывающую подсказку, но не будем о грустном)
В общем, есть (и продолжают создаваться) иконки. Надо их положить на веб-страницу. Надо сделать это так, чтобы потом голова не болела про них весь остаток проекта и ещё пару лет в поддержке. Ну и есть дополнительные хотелки:
хочется вектора. Ну, ладно, вектор – это средство, а не цель. Цель – не беспокоиться ВООБЩЕ об изменении размеров, ретина дисплеях, сохранении изображения в разных форматах для разных целей.
хочется стилизации иконок. Потому что у нас из коробки как минимум два набора тем (светлая и тёмная), а то и контрастная, для людей с нестандартным зрением, а то и оранжевенькая какая-нибудь появится ближе к Новому году… В общем – одна и та же по сути иконка должна выглядеть слегка иначе в зависимости от выбранной на странице темы.
хочется динамической стилизации иконок. Статики – нам мало. Этого хватает для скриншотиков и рекламных буклетиков, но не для живых пользователей. А мы хотели жизни! Мы хотели ховера! Мы хотели селекшена!!! И дизаблить, дизаблить их всех!.. Извините.
НЕ хочется, чтобы в этом участвовал JavaScript в любой его форме и проявлении. Иконки – это внешний вид, а за него ответственный HTML + CSS. Ну, ладно, класс selected я готов навесить на элементы, но это последняя граница…
Есть и факторы, облегчающие задачу. Иконки сейчас (2015, осень, начинает снежить) в моде плоские, строгие. Если лет пять назад иконки пестрели, то сейчас это ушло под влиянием МС, Эппла, Материал Дизайна…
tl;dr Внимание. Следующие несколько разделов – это расплывание мыcлею по древу, причём вширь, обзор решений (в том числе – неудачных) и котик в разных ракурсах. Кому хочется технических подробностей того, что же вышло в итоге – пожалуйте сюда.
Здравствуй, Хабрахабр. Сегодня я хочу рассказать о такой замечательной структуре данных как словарь на нагруженном дереве, известной также как префиксное дерево, или trie.
Что это ?
Нагруженное дерево — структура данных реализующая интерфейс ассоциативного массива, то есть позволяющая хранить пары «ключ-значение». Сразу следует оговорится, что в большинстве случаев ключами выступают строки, однако в качестве ключей можно использовать любые типы данных, представимые как последовательность байт (то есть вообще любые).
Hash array mapped trie — это ассоциативный контейнер, который обладает свойствами хэш таблиц и trie. Операции вставки пары ключ-значение и поиск по ключу — О(1) операции. Про trie на хабре уже писали.
Такой разум возьмет инициативу на себя и станет сам себя совершенствовать со все возрастающей скоростью. Возможности людей ограничены слишком медленной эволюцией, мы не сможем тягаться со скоростью машин и проиграем.
Линус Торвальдс:
Это из раздела научной фантастики. И, стоит признать, фантастики не лучшего качества. На каких препаратах сидят эти люди? Программист не считает возможным развитие искусственного интеллекта, который действительно мог бы поработить человечество. Вместо размышлений на эту тему Торвальдс предложил обратить внимание на любой из существующих искусственных интеллектов и оценить его действия. Как правило, это очень ограниченные и не способные к саморазвитию программные продукты, помогающие переводить речь с одного языка на другой или планировать расписание на неделю.
По мнению Торвальдса, максимум, на что способны подобные системы, уже доступно в Google Now и Siri — распознавание голоса, текстовых обращений и картинок, обработка полученных данных для выполнения простых указаний человека. И он не видит ситуации, в которой посудомоечная машина заставила бы своего владельца обсуждать с ней труды Сартра.
Возьмусь утверждать, что несмотря на все заслуги, как Стивен Хокинг, так и Линус Торвальдс демонстрируют наивность. Хокинг переоценивает возможности интеллекта, а Торвальдс недооценивает.
Кто в наши дни не знает о прокрастинации? Абсолютно каждому из нас присуще тянуть резину (конечно же, в разных масштабах, некоторые достигают совершенства в этом мастерстве). К вам это не относится? Тогда вы супермен, и эта статья не для вас (но я обещаю рассказать о любопытных вещах).
Практически каждый борется с этим явлением, появилось множество разрекламированных методик, которые призваны помочь нам в этом нелегком задании, но в основном все они похожи на большинство современных лекарств: лечат симптомы, а не саму причину недуга. Для того, чтобы снизить уровень прокрастинации нужно разобраться в том, какими процессами в нашем сознании она вызвана. Мы уже рассказывали о том, как наш мозг реагирует на многозадачность. Теперь давайте разберемся с тем, какую роль играют посылаемые им импульсы в нашей прокрастинации.
Продолжаем рубрику "Прикладное терраформирование". В предыдущем выпуске мы оценили марсианские запасы углекислотного льда, и человеческие возможности по его преобразованию в атмосферу. Сегодня поговорим о том есть ли какой-либо смысл наполнять атмосферу Марса в условиях отсутствия магнитного поля.
Было время, когда я за один присест выливал на голову стакан жидкости для линз, чтобы поэкспериментировать с Emotiv`ом. Затем был тюбик геля из шприца в лаборатории МГУ. Сейчас я обладатель «сухого» одноэлектродного нейроинтерфейса NeuroSky MindWave. (Кстати, это отличная игрушка для летнего лагеря, я сделал на инженерной олимпиаде задание по поиску мозговых слизней имплантов, для этого надо было поставить рекорд по «удержанию шарика в воздухе мыслью» — базовая бесплатная игруха к NeuroSky)
По моему пришло время написать какие были и какие будут в ближайшее время потребительские нейроинтерфейсы. А так же коротко о том, как можно собрать свой девайс самому. (И быстренько натренироваться управлять мозгом, чтобы побеждать во всяких конкурсах или пивка налить.)
Под катом обзор устройств, которые были доступны в потребительском сегменте и open-source проекты для самостоятельного изготовления и создания софта.
NASA объединилось с производителем электроники для военной промышленности Osterhout Design Group, чтобы с помощью дополненной реальности сделать работу астронавтов удобнее и эффективнее. Очки от ODG построены на базе Qualcomm Snapdragon 805, оснащены камерой, модулями Wi-Fi, Bluetooth, гироскопами, и работают под управлением специальной версии Android. По словам разработчика, они позволяют делать почти все, на что способен обычный планшет.
От переводчика: Многие знают, что ffmpeg — это сила, но не все знают, какая именно. Он многогранен и безграничен, а его man объёмен и местами малопонятен, лишь немногие постигли дао профессиональной работы с ним. И тем не менее, этот инструмент может быть полезен почти всем, кто хоть иногда работает с видео и звуком, даже на бытовом уровне. О некоторых полезных консольных командах ffmpeg и пойдёт речь в статье. В некоторых местах я взял на себя смелость вставить ссылки на поясняющие статьи.
ffmpeg — это кроссплатформенная open-source библиотека для обработки видео- и аудиофайлов. Я собрал 19 полезных и удивительных команд, покрывающих почти все нужды: конвертация видео, извлечение звуковой дорожки, конвертирование для iPod или PSP, и многое другое.
1. Получение информации о видеофайле
ffmpeg -i video.avi
2. Превратить набор картинок в видео
ffmpeg -f image2 -i image%d.jpg video.mpg
Эта команда преобразует все картинки из текущей директории (названные image1.jpg, image2.jpg и т.д.) в видеофайл video.mpg
(примечание переводчика: мне больше нравится такой формат:
ffmpeg -r 12 -y -i "image_%010d.png" output.mpg
здесь задаётся frame rate (12) для видео, формат «image_%010d.png» означает, что картинки будут искаться в виде image_0000000001.png, image_0000000002.png и тд, то есть, в формате printf)
Авторы позиционируют HyperDex как распределённое, отказоустойчивое, легко-маштабируемое, заточенное на очень быстрый поиск NoSQL key-value хранилище.
Главная фича — новый принцип хранения объектов в многомерном эвклидовом пространстве (рис. слева), используя гиперпространственное хэширование (hyperspace hashing) (на который, кстати, авторы сейчас получают патент), которое позволяет выполнять большинство типичных задач от 2 до 13 раз быстрее, чем в MongoDB, Redis, Cassandra.
За свою долгую историю существования Microsoft выпустил немало инструментов разработки. Но так уж сложилось что на слуху у всех только лишь Visual Studio – большая и мощная IDE «комбайн» предназначенная для всего и вся. Развивается этот продукт уже более двух десятков лет и вобрал в себя самые разные функции. Многим этот инструментарий нравится и иногда даже задавали вопрос – будет ли перенесен Visual Studio на другие платформы. На что чаще всего получали ответ нет. Наверное, понятно почему, в целом такое портирование будет дорогим и неоправданно сложным, уж очень много всего в этой IDE завязано на Windows.
И вот, этой весной для многих неожиданностью было то что Microsoft представил новый продукт под названием Visual Studio Code, да еще и работающий сразу на трех платформах, Linux, OS X и Windows. Не замахиваясь на все функции полноценной IDE, внутри Microsoft решили переосмыслить подход, по которому строится основной инструментарий программиста и начали с самого главного – редактора кода. Visual Studio Code это именно редактор, но при этом обладающий функциями IDE, полагающийся на расширения.
Уже сейчас вы можете использовать Visual Studio Code для создания веб-проектов ASP.NET 5 или Node.js (в чем-то даже удобнее чем в «взрослой» Visual Studio), использовать различные языки, такие как JavaScript, TypeScript, C#, работать с пакетными менеджерами npm, скаффолдингом yeoman и даже осуществлять отладку. Плюсом ко всему будет отличный «интеллисенс», поддержка сниппетов кода, рефакторинг, навигация, многооконность, поддержка git и многое другое.
OnlyOffice – больше чем просто офисный пакет в браузере. Это многофункциональный портал совместной работы, включающий в себя управление документами и проектами. Он позволяет Вам планировать рабочие задачи и вехи, хранить корпоративные или персональные документы и совместно работать над ними, использовать инструменты социальной сети, такие как блоги и форумы, а также общаться с членами коллектива через корпоративную программу обмена мгновенными сообщениями.
RocksDB – постоянное хранилище «ключ-значение» для быстрых накопителей. Основное ее предназначение — хранение данных на flash дисках.
Узким местом в производительности часто является обращение к БД. Эта проблема может решаться по разному. Использование кэша решает проблему производительности, но существенно усложняет архитектуру программы. Графовые базы данных выходят из ситуации за счет оптимальных для данной задачи алгоритмов. Другим типом решений являются хранилища, достигающие высокой производительности за счет использования быстрого носителя. В последнее время появилось много NoSQL хранилищ полностью хранящих данные в памяти. Но память все еще стоит дорого и ее объем ограничен. Увеличение памяти за счет шардинга опять таки упирается в стоимость. Логичным выходом из ситуации было бы использование SSD дисков. Они имеют относительно невысокую стоимость и при этом вполне небольшое время отклика.
Позаимствовал список с сайта db-engines.com (кстати, очень любопытный сайт, рекомендую), включил все базы с ненулевой «популярностью» оттуда. Не отмечайте базы которые просто пробовали/интересно, а только те, что крутятся и приносят деньги вашей компании прямо сейчас.
Обратите внимание: MongoDB это НЕ key-value хранилище, однако за нее можно проголосовать, см. пункт «Хранилище документов в качестве key-value».
Пишите, если забыл какую-то популярную базу (т. е. забыли авторы сайта db-engines.com), добавлю в опрос.
Столкнулся с ситуацией, когда мои коллеги для организации локального персистентного key-value хранилища используют SQLite, MemcacheDB, Redis игнорируя встраиваемые хранилища такие как LevelDB, Sophia, HamsterDB и т.д.
Рассмотрим простую задачу: есть некоторый достаточно большой неизменный набор чисел, к нему осуществляется множество запросов на наличие некоторого числа в этом наборе, необходимо максимально быстро эти запросы обрабатывать. Одно из классических решений заключается в формировании отсортированного массива и обработке запросов через бинарный поиск. Но можно ли добиться более высокой производительности, чем в классической реализации? В этой статье мне хотелось бы рассказать про Cache-Conscious Binary Search. В данном алгоритме предлагается переупорядочить элементы массива таким образом, чтобы использование кэша процессора происходило максимально эффективно.
Небольшое замечание. Я знаком со всеми докладами по анализу протокола Skype. Знаю о skypeopensource, знаю о проекте француза FakeSkype и т.д.
Подходы мне не понравились.
Какие-то данные Какие-то результаты Где-то что-то Как-то отправить и что-то получить Это не мой путь
Для меня реверс инжиниринг — это однозначный ответ на вопрос, а не угадывание каких-то значений или изучение сетевых пакетов. Поэтому предлагаю другой взгляд и анализ. Расскажу, как я прошел его с самого начала. В статье не будет исходников и не будет полного описание протокола. Так же я не буду ни опровергать, ни подтверждать схожую информацию с других источников. Для себя я смог полностью разобрать транспортный сетевой уровень Skype и криптографию, но публиковать не буду по соответствующим соображениям.
Недавно мы в «Я люблю ИП» закончили курсы по дизайну от trydesignlab.com. И это одна из самых важных статей, которую нам посоветовал ментор в процессе обучения. Именно поэтому мы решили её перевести. Посмотреть все наши работы с курсов можно в ВКонтакте по тэгу #design101@iloveip.
Вступление
Сначала о главном. Это руководство не для всех. Это руководство прежде всего для:
разработчиков, которые хотят уметь делать хорошие интерфейсы для себя, если вдруг прижмёт;
UX-дизайнеров, которые знают, что хороший UX-дизайн продаётся лучше в красивой UI-упаковке.
Если вы ходили в художественную школу или считаете себя хорошим дизайнером интерфейсов, то скорее всего это руководство покажется вам а) скучным, б) неправильным или даже в) вызывающим раздражение. Это нормально. Просто закройте эту вкладку и двигайтесь дальше.
А пока давайте я расскажу, что вы найдёте в этой статье.
«Эксмо» подало в Мосгорсуд раздельные иски к сайтам Flibusta.net, Litmir.me и Rutracker.org. Все три сайта претендуют на пожизненную блокировку, сообщает РБК.
Не так давно, закончив работу над очередной статьёй для Хабра, я решил оптравить её на ревью своему знакомому. Сохранив HTML-страницу со всем окружением (картинки, стили etc), я запаковал её в ZIP-архив и отправил адресату. Уже через пять минут я получил фидбек, который, вопреки моим ожиданиям, был связан вовсе не с самой статьёй, а с тем, что архив был абсолютно пустой. Почесав голову и решив, что я затупил с архивированием, я повторил процедуру, убедившись, что выделил все необходимые для запаковывания файлы. Спустя несколько минут знакомый снова разразился удивлённым «Ты что, шутишь?», в то время как я совсем не шутил.
Я начал собирать воедино все элементы паззла. Во-первых, я выяснил, чем он пытается открыть архив. Вдруг, в качестве viewer'а он использует какую-нибудь третьесортную фигню не пойми от какого разработчика? Однако им оказался дефолтный explorer.exe. Я же пользовался Total Commander'ом как для запаковки, так и для просмотра получившегося архива, и в моём случае он вовсе не был пустым:
Что, неужели это сборочка xxxWindowsUltimateEditionxxx подкачала? Я попытался открыть тот же самый архив на моём компьютере при помощи explorer.exe и наконец поверил своему знакомому — архив действительно выглядел пустым:
Кто же виноват в таком поведении? Давайте разберёмся.
Как протекал процесс, и что из этого вышло, читайте под катом (осторожно, много скриншотов). Перед прочтением данной статьи также настоятельно рекомендую ознакомиться с предыдущими.
Высокоуровневые языки программирования содержат в себе много абстрактных программистских конструкций, таких как функции, условные операторы и циклы — они делают нас удивительно продуктивными. Однако одним из недостатков написания кода на высокоуровневом языке является потенциальное значительное снижение скорости работы программы. Поэтому компиляторы стараются автоматически оптимизировать код и увеличить скорость работы. В наши дни логика оптимизации стала очень сложной: компиляторы преобразуют циклы, условные выражения и рекурсивные функции; удаляют целые блоки кода. Они оптимизируют код под процессорную архитектуру, чтобы сделать его действительно быстрым и компактным. И это очень здорово, ведь лучше фокусироваться на написании читабельного кода, чем заниматься ручными оптимизациями, которые будет сложно понимать и поддерживать. Кроме того, ручные оптимизации могут помешать компилятору выполнить дополнительные и более эффективные автоматические оптимизации. Вместо того чтобы писать оптимизации руками, лучше бы сосредоточиться на дизайне архитектуры и на эффективных алгоритмах, включая параллелизм и использование особенностей библиотек.
Данная статья посвящена оптимизациям компилятора Visual C++. Я собираюсь обсудить наиболее важные техники оптимизаций и решения, которые приходится применить компилятору, чтобы правильно их применить. Моя цель не в том, чтобы рассказать вам как вручную оптимизировать код, а в том, чтобы показать, почему стоит доверять компилятору оптимизировать ваш код самостоятельно.
Большая часть времени исполнения программы приходится на циклы: это могут быть вычисления, прием и обработка информации и т.д. Правильное применение техник оптимизации циклов позволит увеличить скорость работы программы. Но прежде, чем приступать к оптимизациям необходимо выделить «узкие» места программы и попытаться найти причины падения быстродействия.
Поучительная история о техниках оптимизации наглядно.
Техзадание
Объявим в рамках топика небольшой конкурс по архитектурно-ориентированной оптимизации программного обеспечения. Вкратце, код состоит из пачки функций, производящих невнятные на первый взгляд манипуляции с исходными данными, и примочки-драйвера, который n раз запускает неоптимизированную версию, затем оптимизированную, сравнивает насчитанные циферки, и, в случае их совпадения, выдает отношение времени выполнения. Вот так:
Executing original code… done Executing optimized code… done Checking results… PASSED Number of runs: 3 Original code average time: 11.954537 sec. Optimized code average time: 1.052994 sec. Speedup: 11.35
Разрешено использовать любые техники оптимизации, компилятор GCC с любыми опциями, и, скажем, сервер с двумя четырехъядерными процессорами Intel Xeon E5420 2.5 GHz. Вот, кстати, код:
В наше время всё чаще сайты сталкиваются с необходимостью введения отзывчивого дизайна и отзывчивых картинок – а в связи с этим есть необходимость эффективного изменения размера всех картинок. Система должна работать так, чтобы каждому пользователю по запросу отправлялась картинка нужного размера – маленькие для пользователей с небольшими экранами, большие – для больших экранов.
Веб таким образом работает отлично, но для доставки картинок разных размеров разным пользователям необходимо все эти картинки сначала создать.
Множество инструментов занимается изменением размера, но слишком часто они выдают большие файлы, аннулирующие выигрыш в быстродействии, который должен приходить вместе с отзывчивыми картинками. Давайте рассмотрим, как при помощи ImageMagick, инструмента командной строки, быстренько изменять размеры картинок, сохраняя превосходное качество и получая файлы небольших объёмов.
Большие картинки == большие проблемы
Средняя веб-страница весит 2 Мб, из них 2/3 – картинки. Миллионы людей ходят в интернет через 3G, или ещё хуже. 2Мб-сайты в этих случаях работают ужасно. Даже на быстром соединении такие сайты могут израсходовать лимиты трафика. Работа веб-дизайнеров и разработчиков – упростить и улучшить жизнь пользователя.
Очень маленькие сайты могут просто сохранить несколько вариантов всех картинок. Но что, если у вас их дофига? Например, в магазине может быть сотня тысяч картинок – не делать же их варианты вручную.
ImageMagick
Утилита командной строки с 25-летним стажем в то же время является редактором картинок с полным набором функций. В ней огромная куча функций, и среди них – быстрое и автоматическое изменение размера картинок. Но с настройками по умолчанию файлы часто получаются излишне большими – иногда по объёму больше оригинала, хотя в них и меньше пикселей. Сейчас я объясню, в чём проблема, и покажу, какие настройки необходимы для её решения.
В прошлых двухстатьях я рассказал об особенностях форматов данных звуковой подсистемы современных игр. Чтобы не утомлять читателей, перейду к несколько другой теме. Какой бы движок не использовала игра, ей нужно где-то хранить ресурсы и извлекать их оттуда в нужный момент. Иногда ресурсы в архиве имеют как идентификатор, так и читабельное имя файла. Но существует довольно много движков, где имён у файлов нет, а есть только хеш. Как же в таком случае можно что-то разобрать в ресурсах?
Рассмотрим это на примере довольно редкого движка bitsquid. Он простой и компактный, но, тем не менее, имеет все необходимые для современных игр возможности. В прошлом году bitsquid вместе с его разработчиком был куплен компанией Autodesk, и теперь они собираются скрестить его с Maya и сделать свой собственный игровой движок, который, как они обещают, будет чем-то невероятным.
Во многих веб-приложениях существует необходимость автоматического кропа — будь то вырезание аватарки из загруженного фото, превью крупных изображений или создание миниатюр в больших галереях.
Но машины все еще не люди, и далеко не всегда будет вырезана нужная область. Старые способы типа вырезать миниатюру 100х100 из левого верхнего угла или из центра отходят на второй план, и на арену выходит смарт-кроп.
XSS неспроста стоит в верхней части списка опасностей OWASP TOP 10. Любой толковый программист о них знает. Но это не мешает статистике: восемь из десяти веб-приложений имеют XSS-уязвимости. А если вспомнить личный опыт пентестов банков, то более реальной представляется картина «десять из десяти». Кажется, тема изъезжена от и до, однако есть подвид XSS, который по разным причинам потерялся. Это — DOM Based XSS. И как раз о нем я сегодня пишу.
Практически невозможно представить себе информационную панель без диаграмм и графиков. Они быстро и эффективно отображают сложные статистические данные. Более того, хорошая диаграмма также улучшает общий дизайн вашего сайта.
В этой статье я покажу вам некоторые из лучших JavaScript библиотек для построения диаграмм/схем (и сводных таблиц). Эти библиотеки помогут вам в создании красивых и настраиваемых графиков для ваших будущих проектов.
Хотя большинство библиотек являются бесплатными и свободно распространяемыми, для некоторых из них есть платные версии с дополнительным функционалом.
Часто путают терминал и шелл. В тех же *nix есть шеллы (bash, csh, zsh, …) и терминалы (konsole/guake/yaquake/tilda и т.д. и т.п.) Для мира Windows общеизвестный терминал только один – стандартное консольное окошко, которое часто ошибочно называют «cmd.exe». И мало кто знает о существовании множества других эмуляторов терминала. Известных шеллов больше, их целых два: cmd.exe и powershell.exe. И хотя есть как минимум три порта bash (MinGW, CygWin, GIT) многие юниксоиды предпочитают ругать cmd.exe.
Меня не устраивал ни один из найденных альтернативных терминалов (как в 2009-м, когда я начал работу над ConEmu, так и сейчас). Казалось бы требований немного, вот основные:
Австралийский разработчик indie-игр Финн Морган (Finn Morgan) разработал очень интересную и полезную технологию для динамической подсветки 2D-спрайтов Sprite Lamp. Изюминкой этой программы является то, что для подсветки объекта с произвольной точки не требуется построение 3D-модели.
Скоро каждый сможет использовать Sprite Lamp в своих играх.
JavaScript – один из главных языков нашего стека в Хекслете. Мы используем ReactJS и NodeJS в интерактивных частях платформы, и сделали вводный курс (более продвинутые – на подходе). Любовь к JS помогла опубликовать этот перевод хорошего эссе «Prototypes are Objects (and why that matters)».
Этот пост рассчитан на тех, кто знаком с объектами в JavaScript и знает, как прототип определяет поведение объекта, что такое функция-конструктор и как свойство .property конструктора относится к объекту, который он конструирует. Общее понимание синтаксиса ECMAScript 2015 тоже не помешает.
Мы всегда могли создать класс в JavaScript таким образом:
Вчера вышла [весьма достойная статья про Web Components, и я понял, что не могу не поделиться тем опытом, что я накопил за последние восемь месяцев. Я не буду рассказывать о том, как работать с Веб Компонентами, я расскажу, почему. Поэтому тем, кто не знает об этом стеке технологий, стоит прочитать статью по ссылке выше. Дело в том, что в июне вышла первая стабильная версия моей библиотеки CornerJS. Начавшись как автономная реализация директив из AngularJS, она постепенно превратилась в более простой — как в использовании, так и в реализации — аналог (неточный, да, я знаю) Пользовательских Элементов из спецификации Веба Компонентов.
Я прошел через большое количество узких мест, а сейчас эта библиотека используется в нескольких больших и не очень проектах в реальных условиях.
Это замечательная, на мой взгляд, в реализации библиотека — я действительно считал ее основным инструментом в разработке, и в последнем проекте (видеопортале) она оказалась важнее jQuery: от него я мог бы отказаться, а от нее нет.
Но я, как человек, внедривший ее в нашу команду, и отказываюсь от нее — мы переходим на Mozilla X-tags для IE9+ сайтов и Polymer для IE10+ сайтов. К счастью, на моей памяти у нас был всего один или два проекта IE8+.
И в этом посте я расскажу, почему веб-компоненты — это не просто будущее веба. А единственное будущее веба.
NGINX вполне заслуженно является одним из лучших по производительности серверов, и всё это благодаря его внутреннему устройству. В то время, как многие веб-серверы и серверы приложений используют простую многопоточную модель, NGINX выделяется из общей массы своей нетривиальной событийной архитектурой, которая позволяет ему с легкостью масштабироваться до сотен тысяч параллельных соединений.
Инфографика Inside NGINX сверху вниз проведет вас по азам устройства процессов к иллюстрации того, как NGINX обрабатывает множество соединений в одном процессе. Данная статья рассмотрит всё это чуть более детально.
Ученик спросил: «Программисты встарь использовали только простые компьютеры и программировали без языков, но они делали прекрасные программы. Почему мы используем сложные компьютеры и языки программирования?». Фу-Тзу ответил: «Строители встарь использовали только палки и глину, но они делали прекрасные хижины».
Мастер Юан-Ма, «Книга программирования»
На текущий момент вы учили язык JavaScript и использовали его в единственном окружении: в браузере. В этой и следующей главе мы кратко представим вам Node.js, программу, которая позволяет применять навыки JavaScript вне браузера. С ней вы можете написать всё, от утилит командной строки до динамических HTTP серверов.
Эти главы посвящены обучению важным идеям, составляющим Node.js и предназначены для передачи вам достаточного количества информации, чтобы вы могли писать полезные программы в этой среде. Они не пытаются быть всеобъемлющими справочниками по Node.
Код из предыдущих глав вы могли писать и исполнять прямо в браузере, но код из этой главы написан для Node и в браузере работать не будет.
Если вы хотите сразу запускать код из этой главы, начните с установки Node с сайта nodejs.org для вашей операционки. Также на этом сайте вы найдёте документацию по Node и его встроенным модулям.
Здравствуйте, меня зовут Дмитрий Карловский и я… много думал. Думал я о том, что не так с XML и почему его в последнее время променяли, на бестолковый JSON. Результатом этих измышлений стал новый стандарт формат данных, который вобрал в себя гибкость XML, простоту JSON и наглядность YAML.
Tree — двумерный бинарно-безопасный формат представления структурированных данных. Легко читаемый как человеком так и компьютером. Простой, компактный, быстрый, выразительный и расширяемый. Сравнивая его с другими популярными форматами, можно составить следующую сравнительную таблицу:
Спустя какое время стало ясно, что основная идея Prototype вошла в противоречие с миром. Создатели браузеров ответили на возрождение Javascript добавлением новых API, многие из которых конфликтовали с реализацией Prototype.
Создатели браузеров поступают гармонично. Решение о новых API принимают с учётом текущих трендов в opensource сообществах. Так prototype.js способствовал появлению Array.prototype.forEach(), map() и т.д., jquery вдохновил разработчиков на HTMLElement.prototype.querySelector() и querySelectorAll().
Код на стороне клиента становится сложнее и объёмнее. Появляются многочисленные фреймворки, которые помогают держать этот хаос под контролем. Backbone, ember, angular и другие создали, чтобы помочь писать чистый, модульный код. Фреймворки уровня приложения — это тренд. Его дух присутствует в JS среде уже какое-то время. Не удивительно, что создатели браузеров решили обратить на него внимание.
Привет, Хабрахабр! В прошлом году мы впервые предоставили разработчикам тестовую версию Android L и получили множество полезных отзывов, которые касались Material Design, а также новых платформ Android Auto, TV и Wear. Вчера на конференции Google I/O мы объявили о повторении нашего удачного опыта: встречайте тестовую версию Android M.
Разработчики остались довольны ранним доступом к новой версии Android в прошлом году: он позволил обновить и оптимизировать приложения для новой версии операционной системы, в которой было введено много нового (в том числе и полностью переосмыслен дизайн и гайдлайны по проектированию интерфейса). Мы хотим и дальше предоставлять разработчикам возможность качественно подготовиться к релизу новой версии ОС: как вы и просили, мы обеспечим более четкий график обновлений SDK и тестовой версии Android M.
Если в Windows XP поиск файлов был хоть и медленным, но все-таки работоспособным, то в Windows 7 он превратился во что-то совсем непонятное. Многие успешно пользуются поиском в Far'е или Total Commander'е вместо стандартных средств Windows. Когда на дисках очень много файлов, такой поиск также выполняется медленно. Я бы вряд ли поверил, если бы не попробовал сам, что файлы можно находить мгновенно (!), прямо во время ввода имени файла в строку поиска. Заинтересовались?
Мощный инструмент для дебаггинга JavaScript, полноценный инспектор кода для Sublime. Фичи: установка брейкпоинтов прямо в редакторе, показ интерактивной консоли с кликабельными объектами, остановка с показом стек трейса и управление шагами дебаггера. Все это работает на ура! А еще есть Fireplay от Mozilla, который позволяет подключаться к Firefox Developer tools и максимально простой дебаггер JSHint.
Новая версия игрового движка Unreal Engine 4.8 содержит 189 новых функций и улучшений, которые разработаны сообществом из нескольких десятков разработчиков.
Самые значительные из нововведений перечислены ниже.
Рендеринг травы
Системы рендеринга травы значительно оптимизированы для открытых миров. Новый рендерер динамически генерирует траву, кусты и другие наземные объекты в случайном порядке вокруг игрока.
На момент написания этого текста текущей версией Android Studio была версия 1.0.1. Компилятор Intel C++ Compiler for Android, будучи частью Intel Integrated Native Developer Experience (Intel INDE), поддерживает Android Studio 1.0.1 в Intel INDE 2015 Update 1. Поскольку Android Studio 1.0.1 не поддерживает Android NDK, в этой статье описаны шаги для создания нативного Android-приложения с использованием Android NDK r10d и компилятора Intel C++ Compiler for Android. Поехали!
Android Studio в качестве системы сборки использует Gradle. На момент написания статьи Gradle в процессе сборки вызывала систему NDK. В Android NDK r10 и более поздней версии после инсталляции Intel INDE компилятор Intel C++ Compiler for Android (ICC) не является более используемым по умолчанию компилятором в системе сборки NDK.
В последние дни при веб-сёрфинге мне попадаются разнообразные полезные «костыли», и я тотчас же пишу о них на Хабрахабре. Вот ещё один.
Как известно, анимированные PNG в формате APNG не включены в стандарт PNG, из-за чего ряд браузеров (IE, Safari, Google Chrome) анимацию в этих изображениях не поддерживают (а вместо неё показывают статический кадр). Чтобы преодолеть эту проблему, предприимчивый Lord_D даже пробовал засовывать кадры по одному в сжатый SVG. Надеюсь, его смелость даёт полное представление о том, до каких крайностей способен в отчаянии дойти веборазработчик.
К счастью, можно обойтись и без крайностей. Евгений Степанищев упомянул о том, что Давид Мзареулян сочинил и выложил на Github библиотеку apng-canvas, обеспечивающую кроссбраузерное отображение APNG во всех тех браузерах (включая стандартный браузер Android), которые сами по себе APNG не понимают. Отображение достигается отрисовкою на холсте (<canvas>).
Решения, написанные на JavaScript становятся сложнее из года в год. Это, несомненно, обусловлено разрастанием такого прекрасного зверя, как веб. Многие из нас сейчас работают с JavaScript модулями — независимыми функциональными компонентами, которые собираются вместе и работают как единое целое. Так же такой подход позволяет нам реализовать взаимозаменяемость компонентов, не прикончив попутно код. Многие из нас использовали для этого паттерн AMD и его реализацию в RequireJS.
Нет предела совершенству, и Google PageSpeed тому доказательство. С его помощью меньше чем за минуту можно получить подробный отчет о производительности Web страницы. В подавляющем большинстве случаев PageSpeed подскажет, что нужно оптимизировать графику. Это наиболее частая проблема и наиболее весомая.
Например, даже на стартовой странице Google Developers графику можно сжать на 71%. Чем меньше весят фотки – тем быстрее грузится сайт. Меньше картинки — меньше трафика — все работает быстрее. Посетители тратят меньше времени – все довольны.
В этом материале подобраны основные инструменты для оптимизации графики.
В любом проекте человеческий фактор никто не отменял, и если пользователи самостоятельно грузят картинки на сайт – появления дубликатов не избежать. Когда доходит до тысяч файлов, глазами всего не пересмотреть, а повторяющиеся картинки мало того, что никому не нужны, так еще и занимают место, тратят ресурс и в конце концов тормозят работу.
Потому рано или поздно встает вопрос автоматизации процесса поиска повторов, и тут мы рассмотрим основные, а также попробуем в деле.
Вы когда-нибудь думали, как было бы здорово, если бы слитый в один файл и минифицированный яваскрипт код в production-окружении можено было удобно читать и даже отлаживать без ущерба производительности? Теперь это возможно, если использовать штуку под названием source maps.
Если коротко, то это способ связать минифицированный/объединённый файл с файлами, из которых он получился. Во время сборки для боевого окружения помимо минификации и объединения файлов также генерируется файл-маппер, который содержит информацию об исходных файлах. Когда производится обращение к конкретному месту в минифицированном файле, то производится поиск в маппере, по которому вычисляется строка и символ в исходном файле. Developer Tools (WebKit nightly builds или Google Chrome Canary) умеет парсить этот файл автоматически и прозрачно подменять файлы, как будто ведётся работа с исходными файлами. На момент написания (оригинальной статьи — прим. перев.) Firefox заблокировал развитие поддержки Source Map. Подробнее — на MozillaWiki Source Map.
Привет. Продолжая рассказывать про различные технологии из графического геймдева — хотел бы рассказать о том, как в DirectX 11 удобно работать с тенями. Расскажу о создании Point-источника света с полным использованием инструментов GAPI DirectX11, затрону такие понятия, как: Hardware Depth Bias, GS Cubemap Render, Native Shadow Map Depth, Hardware PCF. Исходя из легкого серфинга по интернету – я пришел к выводу, что большинство статей о тенях в DX11 неверны, реализованы не совсем красиво или с использованием устаревших подходов. В статье постараюсь сравнить реализацию теней в DirectX 9 и DirectX 11. Все ниже описанное так же справедливо и для OpenGL.
Node.js — вещь, вокруг которой сейчас много шума, восторженных отзывов и гневливых выкриков. При этом, по моим наблюдениям, в умах людей закрепилось следующее представление о том что же такое Node.js: «это штука, позволяющая писать на JavaScript на серверной стороне и использующая JavaScript-движок от Google Chrome». Поклонники языка восторженно вздохнули: «Ах! Сбылось!», противники же процедили сквозь зубы: «Ну вот только еще этой ерунды с прототипами и динамической типизацией нам на серверах не хватало!». И дружно побежали ломать копья в блоги и форумы.
При этом многие представители обоих лагерей придерживаются мнения, что Node.js — это эзотерическая игрушка, веселая задумка для переноса языка браузерных сценариев на «новые колеса». Дабы быть до конца честным, признаюсь, что я так же придерживался подобной точки зрения. В один прекрасный момент, я набрался духу и решил «копнуть поглубже». Выяснилось, что создатель Node.js Райан Дал далеко не фанатик, а человек, пытающийся решить реальную проблему. А его творение — не игрушка, а применимое на практике решение.
Предлагаю вам небольшой урок на тему анимации спрайтов с альфаканалом на канве HTML5.
Преамбула.
Для начала нарисуем нечто
Почему круглое и желтое? Потому что у Дугласа Адамса в «Автостопом по галактике» есть такой Слартибартфаст — очень трогательный дядя, имеет приз за береговые линии при строительстве Земли. Поэтому на всякий случай будем анимировать желтую звезду.
В этой статье рассматривается вариант установки Redmine с базой данных SQlite3 на Windows и запуск его как сервиса. Все необходимые компоненты для установки приведены в статье. Для тестирования была установлена виртуальная машина с «голым» Windows 7 без пакетов обновления, без дополнительного ПО и произведена пошаговая установка по инструкции в статье.
Ответ на вопрос: «Сколько требует ресурса так установленная Redmine?»
ОЗУ: Процесс Redmine использует 2 МБ оперативной памяти, а интерпретатор Ruby «ест» 170 МБ оперативной памяти. ЖД: Установленный «пустой» Redmine с остальным ПО занимает ~500 МБ жесткого диска.
Грядет революция. Появилось новое дополнение к JavaScript, которое изменит всё, что вы когда-либо знали о дата-байндинге. Помимо этого, изменится и подход ваших MVC библиотек к наблюдениям за редактированием и обновлением моделей. Вы готовы?
Хорошо, хорошо. Не будем тянуть. Я рад вам представить Object.observe(), который появился в бета версии Chrome 36. [ТОЛПА ЛИКУЕТ]
Object.observe() является частью следующего ECMAScript стандарта. Он позволяет асинхронно отслеживать изменения JavaScript объектов… без использования каких-либо сторонних библиотек, он позволяет наблюдателю отслеживать изменения состояния объекта во времени.
fetch() позволяет вам делать запросы, схожие с XMLHttpRequest (XHR). Основное отличие заключается в том, что Fetch API использует Promises (Обещания), которые позволяют использовать более простое и чистое API, избегать катастрофического количества callback'ов и необходимости помнить API для XMLHttpRequest.
Хех, мне всегда хотелось написать один из этих «Х считается вредным» постов.
Прежде чем я начну, позвольте сказать следующее: я считаю что jQuery оказал просто невероятное влияние на продвижение Web. Он дал возможность разработчикам делать такие вещи, которые ранее считались немыслимыми. Заставил производителей браузеров реализовать многие фичи нативно (без jQuery у нас наверное никогда бы не появился document.querySelectorAll). jQuery всё еще нужен тем, кто не может положиться на современные плюшки и вынужден поддерживать реликты вроде IE8 или хуже.
Из-за давления бизнеса, мы стремимся сделать всё быстрее. От этого страдает планирование и многие вещи не учитываются. Например, легко забыть о производительности и через какое-то время столкнуться с тем, что на более слабых машинах и планшетах обилие движущихся элементов страшно тормозит и дёргается в конвульсиях. Посмотрим, что можно сделать, если вы столкнулись с такой проблемой или хотели бы её избежать.
Недавно закончил серию девушек. Не слишком страшных решил сохранить, c одной опишу этапы. На мой взгляд, получился косплей на Pin Up. Для рендера бюста использовал KeyShot. Финал рендерил в Marmoset(программа для реал тайм ингейм привью). Все текстуры готовил под PBR шейдер.
По ссылке можно подробно почитать описание PBR-рендера и его тонкости.
Задача корректной симуляции погодных эффектов тянется практически с самого основания игровой индустрии. Погода – неотъемлемая часть нашей жизни, а значит, игры без погодных эффектов не совсем полноценны. Именно поэтому редкая игра обходится без хотя бы очень примитивной погодной симуляции. Поскольку задача весьма стара, то имеется множество устаревших решений, которые и сейчас продолжают использоваться, несмотря на очевидно низкую эффективность. И если с обычным туманом всё просто, то реализация осадков вызывает определенные трудности.
Итак, что же такое дождь или снег в реальном мире?
Не так давно, прочитав статью idoroshenko«Почему eval — это не всегда плохо», я задумался, можно ли использовать подход с генерацией тела функции для клонирования объектов. Даже написал небольшую библиотеку для этого. Бенчмарки давали невероятные результаты, но применимость этого подхода ограничивалась лишь множественным клонированием одинаковых объектов.
Поэтому и у меня возник вопрос: неужели в v8 нет другой возможности избежать расходов, связанных со множественным пересозданием скрытых классов? Ведь это составляет основные траты ресурсов, когда мы клонируем объекты. Как оказалось, такая возможность действительно есть: в самом v8 у объектов существует метод v8::Object::Clone. Этот метод клонирует объекты в широком смысле этого слова, то есть собственно объекты, а также массивы, даты, регулярные выражения, функции и т.д., при этом сохраняя все их свойства, в том числе нестандартные (например, именованные свойства массивов) и даже скрытые.
Была только одна маленькая проблема. Этот метод использовался только в недрах node.js, и не был открыт наружу, для javascript'а.
В наше время при помощи JavaScript и HTML можно сделать практически всё. А благодаря Node-WebKit (недавно переименован в NW.js) можно делать даже десктопные приложения, которые выглядят, как нативные и имеют доступ ко всем частям ОС. Сегодня мы покажем, как создать простое десктопное приложение при помощи Node-WebKit, используя jQuery и несколько модулей для Node.js.
Node-WebKit — комбинация Node.js и встроенного браузера WebKit. Код JavaScript выполняется в особом окружении, из которого есть доступ и к стандартному API браузеров, и к Node.js.
Я не люблю CSS. Он простой и понятный. Это движущая сила Интернета, но он слишком ограниченный и им трудно управлять. Пришло время привести этот язык в порядок и сделать его более полезным, используя динамический CSS при помощи LESS. Объясню свою позицию на примере. Почему бы вместо использования #FF9F94 для получения темно-персикового цвета просто не хранить значение этого цвета в переменной для её последующего использования? Что бы перекрасить сайт достаточно будет изменить значение переменной всего в одном месте и всё. Другими словами: это будет очень изящно, если мы будем использовать немного программирования и логики в CSS, что бы сделать его более мощным инструментом. Хорошо, что это всё возможно с использованием LESS.
Число JS-библиотек ни в коей мере не уменьшается; наоборот, оно растёт с каждым днём. Когда мы доходим до приложений JS, лучшим выбором оказываются шаблоны, чем полноценные библиотеки, потому что это приводит к более чистому базовому коду и лучшему процессу работы с ними.
Не так давно я писал, что вы могли бы попробовать написать свою библиотеку, когда придёт время. Шаблонизаторы же требуют несколько больших навыков и понимания языка, с которым вы работаете, поэтому лучше полагаться на любой шаблонизатор из имеющихся в списке ниже.
Некоторое время назад мы писали, что в Яндекс.Почте появился новый интерфейс, в котором используется шаблонизация данных в браузере. Немногие крупные сервисы отваживались на это, но мы и сейчас считаем такое решение наиболее удачным. Оно не только ускорило работу интерфейса, но и позволяет экономить трафик пользователя и эффективнее расходовать процессорное время серверов.
Тогда в качестве шаблонизатора мы использовали XSL, а данные передавали в формате XML. Переведя проект на новый интерфейс, мы начали искать другие способы ускорения работы интерфейса Яндекс.Почты.
Недавно мы перевели всю Почту на JS-шаблонизатор и JSON-данные.
Использование CSS-спрайтов на сайте позволяет повысить производительность и грамотно организовать элементы интерфейса.
Sprite Sheet — это одно большое изображение мелких графических элементов сайта, например иконок или кнопок. И благодаря CSS можно отображать каждый элемент отдельно.
Суффиксное дерево – мощная структура, позволяющая неожиданно эффективно решать мириады сложных поисковых задач на неструктурированных массивах данных. К сожалению, известные алгоритмы построения суффиксного дерева (главным образом алгоритм, предложенный Эско Укконеном (Esko Ukkonen)) достаточно сложны для понимания и трудоёмки в реализации. Лишь относительно недавно, в 2011 году, стараниями Дэни Бреслауэра (Dany Breslauer) и Джузеппе Италиано (Giuseppe Italiano) был придуман сравнительно несложный метод построения, который фактически является упрощённым вариантом алгоритма Питера Вейнера (Peter Weiner) – человека, придумавшего суффиксные деревья в 1973 году. Если вы не знаете, что такое суффиксное дерево или всегда его боялись, то это ваш шанс изучить его и заодно овладеть относительно простым способом построения.
Как и многие, я долго писал на Node.JS только высокопроизводительные сервисы, но когда в 0.11 сделали генераторы и несколько моих коллег подтвердили, что они работают на production, решил сделать на этой платформе новый учебник JavaScript.
Удобство генераторов для асинхронного JS-кода сложно переоценить. При желании он становится «плоским», меньше букв, чем чистые promise/async.
Хотелось сделать движок быстрым, простым в разработке и иметь возможность запускать некоторые модули и на сервере и на клиенте.
Получилось, если не напутал при подсчёте, около 24000 строк кода (без сторонних node_modules).
Как гласит определение, выпуклая оболочка некоторого множества — это наименьшее выпуклое множество , содержащее в себе множество . Выпуклой оболочкой конечного множества попарно различных точек является многогранник. Для реализации одномерного случая алгоритма Quickhull годится функция std::minmax_element. В сети можно найти множество реализаций алгоритма Quickhull для плоского случая. Однако, для случая произвольной размерности сходу находится лишь одна тяжёловесная реализация с сайта qhull.org.
Повальный переход на электрическую тягу пока не особенно затрагивает авиацию – электромоторы проигрывают по характеристикам давно проверенным моделям двигателей. Но и здесь прогресс не стоит на месте. Компания Siemens недавно представила новый авиационный электромотор с рекордными характеристиками.
Двигатель весом всего 50 кг развивает мощность в 260 КВт. Для сравнения – двигатель Tesla S весит 160 Кг и развивает мощность 310 КВт. То есть, удельная мощность двигателя от Siemens составляет около 5.2 против 1.9 у Tesla. Такие характеристики двигателя позволяют создавать воздушные суда со взлётной массой до двух тонн. При этом для работы воздушного винта не требуется трансмиссия, поскольку мотор выдаёт 2500 оборотов в минуту.
В современном мире многие сталкиваются с необходимостью изучить иностранный язык. Чаще всего этим языком является английский. Методов изучения иностранного языка, и английского в том числе, существует много: заучивание слов по карточкам; расклеивание стикеров с названиями предметов по всему дому; метод 25-го кадра (хотя лично я в него не верю); штудирование грамматики,– как с репетитором/в школе/в университете/на курсах, так и самостоятельно; метод погружения, наконец. В общем, есть из чего выбрать. Благо, на просторах Интернета материалов можно найти великое множество.
Выбор конкретного метода, а может быть, и нескольких, зависит от мотивации. Прежде чем остановиться на каком-то из них, задайте себе вопрос: «Для чего я учу язык?». Кому-то будет вполне достаточно базовых знаний грамматики и словаря, — просто потому, что язык нужен только для чтения статей, например. А кому-то этого будет мало. Да, грамматика и лексика – это, конечно, хорошо. Они – основа языка, его фундамент и стены. Но как быть с живой речью? Ведь понимание иностранной речи, а потом и возможность говорить на иностранном языке – немаловажная составляющая.
К сожалению, нигде нет более менее полной публикации на тему проектирования архитектуры в играх. Есть отдельные статьи на конкретные темы, но нигде все это вместе не собрано. Каждому разработчику приходится самостоятельно по крупицам собирать подобную информацию, набивать шишки. Поэтому решил попробовать собрать часть из этого воедино в данной статье.
Для примеров будет использоваться популярный движок Unity3D. Рассматриваются подходы, применимые в больших играх. Написано из моего личного опыта и из того, как я это понимаю. Конечно, где-то я могу быть не прав, где-то можно лучше сделать. Я тоже все еще в процессе набирания опыта и набивания новых шишек.
В публикации рассматриваются следующие темы:
Наследование VS компоненты
Сложные иерархии классов юнитов, предметов и прочего
Машины состояний, деревья поведений
Абстракции игровых объектов
Упрощение доступа к другим компонентам в объекте, сцене
Эта статья содержит необходимый минимум тех вещей, которые просто необходимо знать о типизации, чтобы не называть динамическую типизацию злом, Lisp — бестиповым языком, а C — языком со строгой типизацией.
В полной версии находится подробное описание всех видов типизации, приправленное примерами кода, ссылками на популярные языки программирования и показательными картинками.
Deus Ex Human Revolution — это компьютерная игра 2011 года, которая является более успешным продолжением оригинальной Deus Ex, чем Invisible War. Но этот пост не о качестве игры, а о демонстрации её технических принципов. Адриан Курреж провёл несколько часов за реверс-инжинирингом, пытаясь понять с помощью инструмента Renderdoc, как происходит обработка каждого из кадров Human Revolution. Затем Адриан изложил результаты в своём блоге.
Кэш приложений, также известный как AppCache, на сегодняшний день является одной из самых острых тем для веб-разработчиков. AppCache позволяет дать возможность посетителям вашего сайта загружать сайт, когда они офлайн. Вы даже можете сохранять части вашего сайта, такие как изображения, таблицы стилей или веб-шрифты в кэше на компьютере пользователя. Это может помочь быстрее загружать ваш сайт, тем самым снижая нагрузку на ваш сервер.
Чтобы использовать AppCache, создается файл описания с расширением «appcache», например, manifest.appcache. В этом файле можно перечислить все файлы, которые должны кэшироваться. Чтобы включить эту функцию на вашем сайте, необходимо включить ссылку на этот файл описания на вашей веб-странице в html-элемент следующим образом:
Серьезно нашумевший в 2013 году проект «The Last of Us» по праву считается одной из жемчужин среди игр для PlayStation 3, а после и PlayStation 4. Студия-разработчик Naughty Dog, известная среди игроков благодаря таким франшизам как Crash Bandicoot и Uncharted, всегда очень внимательно подходит к работе, в особенности учитывая то, что уже много лет их главный хлеб — это эксклюзивы для японских консолей. Можно долго спорить о предпочтениях, но большинство геймеров сходятся в одном: The Last of Us получила более сотни призов в номинации «Игра Года» по версиям различных издательств по всему миру не просто так. Одной из самых сильных сторон проекта называлась история, что неудивительно, ведь награду гильдии сценаристов США кому попало не дают. А сцена встречи с жирафами в постапокалиптическом мире, как это не дико звучит, сыграла в описании этой истории и придании ей эмоционального окраса не последнюю роль. Предлагаю Вам познакомиться с воспоминаниями Джона Суини, одного из художников студии Naughty Dog.
Публикация содержит сюжетные спойлеры. Если вы: 1. Геймер, ценящий сюжет. 2. Все еще не играли в The Last of Us. 3. Не смотрели прохождение или трехчасовой игрофильм на YouTube, то вам стоит воздержаться от прочтения и познакомиться с историей главных героев самостоятельно.
Это вторая статья из серии «Почему от 3D болит голова». В первой части речь шла в основном про проблемы кинооборудования. Во второй части речь пойдет про общие проблемы контента. Что такое «вырви глаз»-сцены? Какими они бывают? Почему они попадают даже в блокбастеры? Также очень важный аспект субъективное восприятие. В набравшем наибольшее количество плюсов комментарии к первой статье серии, автор пишет: «Фильм «в триде» чаще всего имеет 2-3 сцены, где это самое «триде» заметно, обычно именно для этого и снятые, а в остальном отличается только мутной темной картинкой через заляпанные очки...» Почему картинка мутная и темная, и когда могут закончиться «темные времена 3D» было подробно рассказано в первой части, а вот почему про одни и те же фильмы одни говорят, что там «слишком трехмерные сцены, аж глаза ломит», а другие «3D эффекта в фильме совершенно не видно» будет рассказано ниже.
Агенство DARPA разместило внутренний заказ на разработку дронов по новой программе Fast Lightweight Autonomy (FLA), согласно которой беспилотники этого класса должны будут обладать маневренностью, сравнимой с маневренностью птиц или насекомых при их быстром полёте, и при этом обходиться без ручного управления оператором.
Могут ли компьютеры научиться рисовать, как Ван Гог? Определенно да, до некоторой степени! Для этого, подобно художникам-копиистам, алгоритму сначало потребуется взять некоторое оригинальное произведение, а затем он сможет на их основе создать что-то сам. Насколько хорошо он сможет с этим справиться? Пожалуйста, судите сами.
CMake — кроcсплатформенная утилита для автоматической сборки программы из исходного кода. При этом сама CMake непосредственно сборкой не занимается, а представляет из себя front-end. В качестве back-end`a могут выступать различные версии make и Ninja. Так же CMake позволяет создавать проекты для CodeBlocks, Eclipse, KDevelop3, MS VC++ и Xcode. Стоит отметить, что большинство проектов создаются не нативных, а всё с теми же back-end`ами.
Привет, %habrauser%! Уверен, ты уже видел CSS анимацию, часы, блоки с уголком и прочее-прочее-прочее. Однако, видел ли ты когда-нибудь шрифт, который написан только на CSS?
p.s в конце этого руководства есть видео обзор в котором на примерах идет сравнение двух реализованных методов управления автомобилем.
Итак, приступим к изучению нашего руководства.
Часть 3: Под капотом
Мы уже видели, как собрать рабочую машину из 3D-модели, скриптов и встроенных компонентов. Мы также познакомились с публичными переменными и как они могут быть использованы для тонкой настройки автомобиля.
Если вы изучили 1ую часть этого руководства и собрали автомобиль, вы уже на этапе где автомобиль является довольно-таки работоспособным. Но, если вы тестировали немного автомобиль, вы вероятно заметили, что есть все-таки возможность для улучшения управления автомобилем.
Именно здесь тонкая настройка выходит на сцену. В разработке игры тонкая настройка является важной частью, что бы сделать свою игру интересной, сложной и удивительной. Идея заключается в том, что бы когда в вашей игре будет несколько автомобилей, вы наверно захотите что бы у них была разная скорость, сопротивление или вы может хотите изменить свет на сцене и т.д
Главная сила Unity3d является его возможность тонкой настройки (tweakability) — как вы видели, все публичные переменные в скриптах показаны в инспекторе, так что вы можете изменить значения, не изменяя его в коде. И даже более мощные настройки: как только вы сделали изменения, вы можете сразу же увидеть результат изменений. Вам никогда не придется перекомпилировать игру, что бы увидеть результат изменений.
P.S Оригинал руководства, находится в самом проекте ввиде 3ех PDF файлов, в папке Assets.
Данный архив был заменен на UnityPacked. В этом проекте уже залит архив со скриптами переписанными на C# находящийся в папке Assets\Scripts\CSharpScripts. Порядок установки:
1) Запускаем Unity3d и создает пустой проект. 2) Импортируем наш проект > (Assets/Import Package/Custom Package). 3) Дожидаемся импорта всех ресурсов и вуаля наш проект импортирован. 4) ВНИМАНИЕ!!! если хотите использовать все C# скрипты, надо удалить предварительно JS скрипты из проекта и из
Prefabs, а затем распаковать архив C# скриптов и использовать эти скрипты.
Отдельное спасибо команде Zionn Game Room за перевод официальных и не официальных видеоуроков по Unity3d на русский язык. И так, приступим к изучению нашего руководства.
В официальном руководстве говорилось о физике автомобиля, которая имеет упрощенную модель и имеет много недостатков, которые можно прочитать в самом конце Часть 3 руководства. Или посмотреть это видео:
P.S Для тех у кого модели экспортированы, можем сразу же перейти к настройке автомобиля Переход, а так же могут просмотреть видео по настройки автомобиля (дополнение к статье) :
Со времён систематизации методов объекта console прошло достаточно много времени, некоторые браузеры получили поддержку недостающих ранее методов. Таблица вызывает естественный интерес у разработчиков, поэтому — почему бы её не обновить, дополнив в одной статье описаниями? Github.
Увидел я как-то IPv6 Teredo пиров в µTorrent под Windows, которые качали куски с довольно приличной скоростью, и тут меня осенило…
Что такое Teredo?
Teredo — технология туннелирования IPv6 через IPv4 UDP-пакеты. Она задумывалась как переходная технология, которая работает за NAT, и, в общем, более-менее выполняет возложенные на нее обязанности. Teredo позволяет получить доступ в IPv6-интернет через публичные Teredo-серверы. Интересно то, что в Windows 7, 8 и 8.1 Teredo настроен и включен по умолчанию, прямо из коробки, и использует сервер Teredo от Microsoft (teredo.ipv6.microsoft.com).
Зачем это нам?
Веб-сайты, определенные ссылки которых по тем или иным причинам оказались в реестре запрещенных сайтов, могут организовать доступ с использованием Teredo, что позволит вернуть доступ к сайту примерно 80-85% пользователям современных версий Windows без дополнительных настроек и ПО! Доступ через Teredo позволяет обойти все протестированные DPI-решения, применяемые провайдерами. Роскомнадзор не только не может внести такие страницы в реестр, но и не может получить к ним доступ (вероятно, Teredo у них не работает):
Скрытый текст
Здравствуйте Благодарим Вас за активную гражданскую позицию, однако сообщаем, что Ваша заявка была отклонена по следующим возможным причинам: — на момент проведения проверки экспертами, указанный в Вашем обращении адрес http://[2001:0:9d38:6ab8:30c4:d940:9469:f43e]/ был не доступен; — указанный в Вашем обращение адрес http://[2001:0:9d38:6ab8:30c4:d940:9469:f43e]/ указан неверно, либо идет перенаправление на другой адрес; — указанный в Вашем обращение адрес http://[2001:0:9d38:6ab8:30c4:d940:9469:f43e]/ требует обязательной регистрации/авторизации. С уважением, ФЕДЕРАЛЬНАЯ СЛУЖБА ПО НАДЗОРУ В СФЕРЕ СВЯЗИ, ИНФОРМАЦИОННЫХ ТЕХНОЛОГИЙ И МАССОВЫХ КОММУНИКАЦИЙ.
К тому же, у Роскомнадзора нет полномочий блокировать страницы, которые перенаправляют на другие страницы, и кнопка «Актуальный Навальный» тому подтверждение.
Особенности сервера Teredo от Microsoft
Для доступа в «обычный» IPv6, в Teredo используются Relay-серверы, которые имеют полный IPv6-доступ и работают как прокси-серверы. В свою очередь, relay-серверы Teredo от Microsoft не позволяют получить доступ в «обычный» IPv6 или к другим Teredo-серверам, разрешая только связность Teredo-клиентов, настроенных на сервер Microsoft, и образуя такую большую закрытую сеть из Windows-компьютеров.
Пару лет назад я прочитал интересные факты о жизненном цикле периодических цикад. Обычно мы не видим вокруг себя много этих насекомых, потому что бóльшую часть своей жизни они проводят под землёй и тихо сосут корни растений.
Однако, в зависимости от вида, каждые 7, 11, 13 или 17 лет периодические цикады одновременно массово вылезают на свет и превращаются в шумных летающих тварей, спариваются и вскоре умирают.
Хотя наши странные цикады весело уходят в иной мир, возникает очевидный вопрос: это просто случайность, или числа 7, 11, 13 и 17 какие-то особенные?
Доброго времени суток. Как со мной бывает, как только я разобрался в каком-то сложном для себя вопросе, я сразу хочу рассказать всем решение. Поэтому решил написать серию из двух статей по такой интересной теме, как процедурная генерация. А конкретнее, я буду рассказывать про генерацию текстур планет. В этот раз я подготовился основательнее и постараюсь сделать материал качественнее, чем в моем предыдущем посте «Простая система событий в Unity» (кстати, спасибо всем за ответные посты). Прежде чем продолжить, хочу обратить ваше внимание на несколько моментов:
1) Этот генератор не претендует на реалистичность, и писал я его для того, чтобы сгенерировать уникальные текстуры для сотни маленьких шариков, которые занимают 10% экрана и к тому же прикрыты облаками. 2) Но это не значит, что я не буду рад критике. Напротив, одна из причин написания этого поста — получить советы по улучшению алгоритма, я с радостью улучшу его. 3) Чисто технический момент: я пишу на C# под Unity3d, так что думать о том, как выводить в изображение с приемлимой скоростью вам придется самим, для каждого языка и платформы свои способы. Итак, план таков: в первой статье я рассказываю о процедурной генерации планет типа «терра», потом получаю шквал критики, ради которого все и делалось, улучшаю алгоритм, дорабатываю для других типов планет и пишу вторую часть.
В мае 2013 года я присутствовала на CSSConf и услышала, как Лиа Веру говорит об укрощении свойства border-radius. Это было поучительно и позволило мне понять о CSS то, чего я раньше не понимала. Это напомнило мне времена, когда я изучала изящные искусства, когда я постоянно стремилась повысить свой профессиональный уровень. Мой уровень владения CSS можно назвать средним, поэтому я бросила себе вызов, чтобы узнать все, что я смогу, исследуя и экспериментируя со свойствами
Но почему именно один DIV?
Когда я училась рисовать, мой класс делал упражнение, в ходе которого мы получали цвета смешением трех основных: красного, желтого и синего. Целью этого занятия были изучение поведения материалов и понимание силы комбинации. Конечно, вы можете купить зеленую краску, но также можете получить ее, смешав синий и желтые цвета. Большее количество доступных вариантов решения проблемы заставляет нас пересматривать наши привычные решения.
Я решила запустить проект a.singlediv.com, где намеревалась каждые несколько дней размещать нечто новенькое, созданное с помощью CSS. Я поставила перед собой ограничение использовать только один DIV.
А что если объединить профессионалов, работавших над крупными web проектами, чтобы создать исчерпывающее руководство по оптимизации front-end разработки? И получить в результате не скучную инструкцию, а что то поинтереснее? А если позвать Briza Bueno (Americanas.com), Davidson Fellipe (Globo.com), Giovanni Keppelen (ex-Peixe Urbano), Jaydson Gomes (Terra), Marcel Duran (Twitter), Mike Taylor (Opera), Renato Mangini (Google), и Sérgio Lopes (Caelum) чтобы собрать лучшие практики?
Именно это мы и сделали! Мы научим вас создавать быстрые сайты.
Я уже довольно долгое время хочу формализовать все свои мысли, опыт, ежедневно применяемый на практике, и многое другое в одном месте и предоставить их общественности. Уверен, многим этот материал будет полезен. Он посвящен различным моментам в конфигурации серверного ПО Linux и безопасным подходам к созданию сайтов/приложений на php (все же это до сих пор одна из самых популярных связок, хоть её успешно и подвигают другие технологии. Но советы так же легко применимы и к веб-ресурсам на других технологиях).
Т.е. речь идет о типичной ситуации. Проект (стартап), купили под него сервер и разворачиваем на нем сайт. Бизнесу не нужно тратить лишних денег на сервера (поэтому будут выбраны наиболее производительные связки ПО), а так же нужно, чтобы все было безопасно, при чем бесплатно :)
Думаю, многие знакомы с весьма необычной игрой Minecraft (справа — пример сгенерированной в ней карты), в которой игрок находится на (практически) бесконечной поверхности Земли и может исследовать окружающий мир с минимальными ограничениями.
Как же автору игры, Notch'у, удалось добиться подобного сходства его случайных «миров» с земными просторами? В этом топике я как раз и рассмотрю один из способов построить искусственный ландшафт такого рода (и вскользь упомяну пару других способов), а также расскажу о моем небольшом усовершенствовании этого алгоритма, позволяющем значительно увеличивать размеры ландшафта без заметных потерь в производительности.
Внутри вас ждет несколько схем и красивых картинок, довольно много букв и ссылка на пример реализации алгоритма.
Если ты всегда мечтал написать свой язык программирования — добро пожаловать. Здесь ты наверняка найдёшь для себя что-нибудь интересное.
GitHub-юзер yawnt собрал чудесную подборку ссылок для любителей драконов, языков и прочих вкусных внутренностей. А знающие камрады в комментариях наверняка поделятся с тобой и другими яствами.
Пишет yawnt следующее:
С каждым днём мне всё интереснее тема компиляторов, интерпретаторов и дизайна языков программирования в целом. И я решил поделиться с народом ссылками на собранные мной материалы (большую часть мне самому ещё предстоит прочитать :<). Надеюсь, кому-нибудь они окажутся полезными.
Я не включил (и не собираюсь) в список ссылки на официальную документацию, т. к. считаю очевидным, что первым делом следует смотреть именно туда ;P.
Как всем известно, 71% поверхности Земли занимает вода. К сожалению или к счастью, корректно изобразить океан умеют единицы. Иван Айвазовский вошел в учебники живописи благодаря одним только морским пейзажам. В компьютерных играх все еще сложнее. Когда-то море в них обозначали скоплением синих пикселей, раскрашенных белыми квадратами пены. Со временем виртуальные моря стали больше похожи на снимки из отпуска, научились качать волну и покрываться рябью, в которой иногда даже отражались очертания парусников. Но они оставались самостоятельной стихией: натолкнувшись на берег, волна превращалась в незамысловатые угловатые полигоны. Настоящий прибой логично взаимодействует с пляжем, увлажняет песок и с шуршанием откатывается назад. Такого правдоподобия удалось добиться только в современных играх. В том числе в нашем Skyforge. И хоть в основные события будут разворачиваться на суше, игроки попадут и на тропические острова, и в шумные порты. Вода будет постоянно рядом. Ее «правильный» облик будет играть большую роль. И воссоздание морской стихии – серьезная математическая задача. Расскажу об этапах ее реализации.
В данной статье я расскажу об алгоритме смешивания текстур, который позволяет привести внешний вид ландшафта ближе к естественному. Этот алгоритм легко может быть использован как в шейдерах 3D игр, так и в 2D играх.
Статья рассчитана на начинающих разработчиков игр.
Луа (Lua) — мощный, быстрый, лёгкий, расширяемый и встраиваемый скриптовый язык программирования. Луа удобно использовать для написания бизнес-логики приложений.
Отдельные части логики приложения часто бывает удобно описывать в декларативном стиле. Декларативный стиль программирования отличается от более привычного многим императивного тем, что описывается, в первую очередь, каково нечто а не как именно оно создаётся. Написание кода в декларативном стиле часто позволяет скрыть лишние детали реализации.
Луа — мультипарадигменный язык программирования. Одна из сильных сторон Луа — хорошая поддержка декларативного стиля. В этой статье я кратко опишу базовые декларативные средства, предоставлямые языком Луа.
С текстурами вечно какие-то проблемы! То оказывается, что нельзя взять любую фотку и налепить на модельку. То на стыке текстур появляются швы, которые замучаешься заглаживать. То вроде уже и загладил всё, но глаз, этакий проказник, всё равно замечает повторяющиеся узоры и рушит иллюзию.
Можно сделать текстуру побольше, чтобы повторяющиеся куски дальше отстояли друг от друга и были не так заметны. Можно даже сделать её совсем огромной, на пару сотен тысяч пикселей, чтобы она накрывала всю сцену целиком без швов и повторений. Подобную технику называют мегатекстурой. Но мегатекстуры и близкие к ним виртуальные текстуры усложняют работу с памятью, для работы с ними требуются особые инструменты, да и в целом это ещё молодая технология.
Как же быть? Есть один трюк — непериодические мозаики. Они лишены проблемы повторяемости и достаточно просты в реализации. Одну из таких мозаик придумал китайский математик Ван Хао в 1961 году. Элементы этой мозаики можно представить в виде прямоугольников с разноцветными гранями. Но чтобы понять принцип её работы, надо сначала разобраться в классическом методе заполнения площадей текстурами.
Как в сравнительно короткие сроки написать компилятор какого-либо языка программирования. Для этого следует воспользоваться средствами разработки, автоматизирующие процесс. Я хотел бы рассказать о том, как я писал компилятор языка программирования MiniJava под платформу .NET Framework.
Весь процесс написания компилятора в целом отображён на следующем изображении. На вход подаётся файл с исходным кодом на языке программирования MiniJava. Выходом является PE-файл для выполнения средой CLR.
Далее я хотел бы сконцентрироваться на практической части описания.
В данной статье описывается процесс создания персонажа для игрового движка. Статья в первую очередь адресована тем, кто интересуется процессом разработки next gen моделей, а также всем, кто хочет заглянуть за кулисы современного игродела. Персонажа я делал для портфолио, на персонажей переключился совсем недавно, можно сказать, что это первый доведенный до ума персонаж. Поскольку данная работа — мой личный проект, то я установил ограничение треугольников в 20 000, текстуры в 2048*2048, работа планировалась под PBR.
Ян Крисслер (Jan Krissler), тот же биометрический хакер, который красноречиво демонстрирует «уязвимость большого пальца» и который хакнул по фотографии министра обороны Германии, по блеску глаз может узнать ваш пароль/PIN.
Как показала практика, глаза это не только зеркало души, но и просто зеркало, а значит в него можно подсмотреть, что же творится у вас на экране.
О том, как распознают напечатанные символы по отражению от глаз и от солнцезащитных очков, читайте под катом
Тим Петерс разработал гибридный алгоритм сортировки Timsort в 2002 году. Алгоритм представляет собой искусную комбинацию идей сортировки слиянием и сортировки вставками и заточен на эффективную работу с реальными данными. Впервые Timsort был разработан для Python, но затем Джошуа Блох (создатель коллекций Java, именно он, кстати, отметил, что большинство алгоритмов двоичного поиска содержит ошибку) портировал его на Java (методы java.util.Collections.sort и java.util.Arrays.sort). Сегодня Timsort является стандартным алгоритмом сортировки в Android SDK, Oracle JDK и OpenJDK. Учитывая популярность этих платформ, можно сделать вывод, что счёт компьютеров, облачных сервисов и мобильных устройств, использующих Timsort для сортировки, идёт на миллиарды.
Но вернёмся в 2015-й год. После того как мы успешно верифицировали Java-реализации сортировки подсчётом и поразрядной сортировки (J. Autom. Reasoning 53(2), 129-139) нашим инструментом формальной верификации под названием KeY, мы искали новый объект для изучения. Timsort казался подходящей кандидатурой, потому что он довольно сложный и широко используется. К сожалению, мы не смогли доказать его корректность. Причина этого при детальном рассмотрении оказалась проста: в реализации Timsort есть баг. Наши теоретические исследования указали нам, где искать ошибку (любопытно, что ошибка была уже в питоновской реализации). В данной статье рассказывается, как мы этого добились.
Статья с более полным анализом, а также несколько тестовых программ доступны на нашем сайте.
В процессе перехода с SVN на Git мы столкнулись с необходимостью переписывания наших внутренних инструментов, связанных с развёртыванием кода, которые ориентировались на существование линейной истории правок (и разработку в trunk). На Хабре уже публиковались возможные решения этой проблемы через Git-SVN, но мы пошли другим путём. Нам нужна поддержка таких возможностей Git, как branching и merge, поэтому мы решили разобраться в основах, как же работает Git и каким способом должна осуществляться интеграция с ним.
Вот уже второй день множество людей на самых разных сайтах обсуждает очень простой вопрос. Какого цвета это платье?
Казалось бы, какие тут могут возникнуть сложности? Но единства в этом вопрос нет: три четверти опрошенных считают платье бело-золотым, а одна четверть — сине-черным. Согласитесь, это странно. В чем же дело?
Итак, Адблок… Но здесь я буду говорить не столько о блокировке рекламы, сколько об оптимизации и правильном использовании этого интересного своей универсальностью дополнения. Не отношусь к тем, кого раздражает сама реклама — меня раздражает способ ее доставки.
Мы смогли уменьшить объем шрифтов для Persona на 85%, с 300 до 45 килобайт, используя подмножества шрифтов. Эта статья рассказывает о том, как именно мы это сделали, и какие мы использовали инструменты.
Представляем connect-fonts
Connect-fonts — это middleware для Connect, которое улучшает производительность @font-face, раздавая клиентам подобранные специально для их языка подмножества шрифтов, уменьшая тем самым их размер. Connect-fonts также генерирует специфические для локали и браузера стили @font-face и CORS-заголовки для Firefox и IE9+. Для раздачи подмножеств шрифтов создаются так называемые font packs — поддиректории с подмножествами шрифтов плюс простой конфигурационный файл JSON. Некоторые наборы распространённых open source-шрифтов доступны в готовом виде в пакете npm, впрочем, создавать свои пакеты совсем нетрудно.
Если вы не слишком хорошо ориентируетесь в работе со шрифтами в интернете, мы собрали небольшую коллекцию ссылок по теме @font-face. [От переводчика: а на Хабре очень кстати статья, посвящённая производительности веб-шрифтов]
Одной из функций нашего сервиса является возможность скачать конвертированный шрифт. При этом мы хотим предлагать шрифты в оптимальном качестве. А для того, чтобы это стало возможным, мы провели тестирование самых популярных конвертеров шрифтов, доступных онлайн, без регистрации и бесплатно.
Хоть на самом деле конвертеров уже появилось великое множество, не все могут превращать otf\ttf в woff\eot\svg. Существуют специализированные сервисы, которые работают с другими форматами(.pfb, .dfont и др.).
Компания Google создала систему искусственного интеллекта, которая играет лучше человека во многие аркадные игры. Программа научилась играть, не зная правил и не имея доступа к коду, а просто наблюдая за картинкой на экране.
В Мексике бушует насилие из-за активной борьбы правительства с наркокартелями. Последние придумали весьма радикальное решение для получения преимущества в борьбе на улицах.
Чудо инженерной мысли и просмотр фильма «Безумный Макс» помогли картелям создать собственные, так называемые нарко-танки.
За последние два года я прочитал более сотни научно-фантастических книг, в среднем около одной в неделю. Полный список можно посмотреть здесь, я даже отметил свои любимые.
Я начал читать научную фантастику, просто чтобы скоротать время. У меня остались хорошие воспоминания о прочтении «Парк Юрского периода» в детстве. Я продолжил читать, потому что я заметил, что эта книга дала мне кое-что: сильное воображение, нелюбовь к обыденности.
Я поймал себя на том, что мои идеи отличаются от тех, которые множество черпают из тех же статей TechCrunch, Hacker News, Хабрахабра и других «ежедневных» сайтов жителей Силиконовой (Кремниевой) долины. Мой бизнес — это продажа идей, а эти книги одновременно настоящее сокровище и мой инструментарий.
Как говорит футуролог Джейсон Сильва:
«Воображение позволяет нам ощущать восхитительные будущие возможности, выбрать наиболее удивительную, и двигать настоящее вперед, чтобы в конце-концов встретить её.»
Я думаю, что чтение этих книг помогло мне и в создании идеи и в движении к ней.
Каждая хорошая научная фантастика, по сути, это мысленный эксперимент, и я хотел бы запустить свой собственный прямо сейчас:
Sublime Text на данный момент является одним из самых популярных текстовых редакторов, используемых для веб-разработки, поэтому надо знать его преимущества и недостатки. Вместо того, чтобы шаг за шагом описать все фичи Sublime Text, эта статья познакомит вас с самыми популярными приёмами и полезными плагинами, позволяющими ускорить разработку.
Предисловие от переводчика. В постскриптуме к моей вчерашней блогозаписи я указал, что AppJS — это не единственное такое средство, которое позволяет создавать приложения с GUI (графическим интерфейсом пользователя) при помощи вебоподобных методов разработки на языках HTML, CSS и JavaScript с использованием движка Node.js. Естественной иллюстрацией к этому постскриптуму является нижеследующий перевод гитхабовской страницы проекта node-webkit. И сразу скажу: я предвижу заранее, что непредвзятый взгляд ваш сочтёт node-webkit ещё более удобным и развитым средством, чем AppJS.
Введение
node-webkit — среда для запуска приложений, основанная на Chromium и Node.js. При помощи node-webkit можно создавать традиционные графические приложения посредством HTML и JavaScript. Также node-webkit позволяет вызывать модули Node.js прямо из DOM и тем обеспечивает новый способ создания таких приложений и употребления веботехнологий в них.
node-webkit создан и разрабатывается в Интеловском Центре технологий с открытым исходным кодом (Intel Open Source Technology Center).
Техника – это способ справиться с заданием, и у нас, разработчиков и дизайнеров фронтэнда, этих способов бывает достаточно много. При это, будучи погруженными в рутинную работу, мы порой не всегда замечаем как стремительно меняется окружающая нас сфера. В период с 2002 по 2010 годы сообщество фронтэнд-разработчиков буквально покрывалось язвами избыточного кода и ресурсов, от которых страдали и работа сайтов, и удобство их использования. Чтобы с этим справиться, мы придумали уйму хаков, трюков и уловок под кодовым названием «техника». Мы по-прежнему продолжаем выполнять поставленные перед нами задания, просто используем не самые эффективные способы.
Оборачиваясь назад, отметим, что в последние несколько лет установились новые, лучшие, стандарты и способы их применения, позволяя нам создавать более продвинутые «техники». Этот новый мир, открытый перед нами, называется «modern web». Web 2.0, которым восхищались в свое время, сегодня для нас стал запутанным и застойным. С одной стороны нет сомнений в том, что подобная судьба постигнет и то, что мы называем «modern web». С другой — пока что мы можем использовать этот термин и злоупотреблять им сколько угодно, пока понимаем, что он означает.
В 2010 появился стандарт HTML5, обеспечивающий совершенно новую, полустандартизованную веб-среду. Такие браузеры, как Opera, Firefox, Chrome и Safari приняли нововведения, и их разработчики вышли за пределы реализации стандартов и изучения интерфейса программирования приложений. Чтобы представить себе, насколько автономны эти браузеры, можно ознакомиться с отличной наглядной демонстрацией поддержки HTML5 на www.html5readiness.com.
В своей последней статье я рассматривал вопрос того, как нужно строить музыкальную теорию на основании эмпирического наблюдения за людьми – на базе их вкусов и музыкальных предпочтений. Также для построения музыкальной теории можно попытаться понять, что же происходит у нас в голове. Этот вопрос рассмотрел Дэниел Уилкерсон (Daniel Shawcross Wilkerson) в своей статье «Разъяснение гармонии: По пути прогресса к научной теории музыки». Это эссе имеет второе очаровательное старомодное название:
Мажорная гамма, стандартная терминология и различия в восприятии минорных и мажорных трезвучий, которые объясняются основными принципами физики и математики. Несостоятельность теории Гельмгольца, а также обоснование теории Терхардта и других.
Уилкерсон начинает с замечания о том, что книги по теории музыки читаются как медицинские тексты средних веков и «в них полно необоснованных суждений с забавными символами, приукрашенными фразами на латыни». Мы можем писать их понятнее.
Все больше игровых релизов, все меньше свободного времени. Начало декабря — самое время оторваться от прохождения очередного ААА-шедевра и почитать, что интересного произошло в игровой индустрии за ноябрь.
Сидел я как-то дома, читал статью про хрущёвки и восторгался гением архитектора. Потом меня отпустило, и я подумал, что унылость и однообразие хрущёвок очень легко можно описать математически. Прямые углы, равные интервалы, минимум украшений — что может быть проще?
На самом деле, у хрущёвок существует несколько десятков модификаций, но некая основа, сущность хрущёвки всё равно прослеживается.
В общем, недолго думая, я сел и написал генератор хрущёвок на C# под Unity3d. Под катом описание работы алгоритма и размышления на тему uv-карт, сабмешей и шейдеров.
Всем привет! Меня зовут Сергей Макеев, и я технический директор в проекте Skyforge в команде Allods Team, игровой студии Mail.Ru Group. Мне хотелось бы рассказать про технологии рендеринга, которые мы используем для создания графики в Skyforge. Расскажу немного о задачах, которые стояли перед нами при разработке Skyforge с точки зрения программиста. У нас свой собственный движок. Разрабатывать свою технологию дорого и сложно, но дело в том, что на момент запуска игры (три года назад) не было технологии, которая могла бы удовлетворить всем нашим запросам. И нам пришлось самим создать движок с нуля.
Продолжаем цикл статей, посвященных задаче изменения человеческого голоса, над решением которой мы работаем в компании i-Free. В предыдущей статье я попытался кратко рассказать о математическом аппарате, применяемом для описания сложных физических процессов, происходящих в речевом тракте человека при произнесении звуков. Были затронуты вопросы, связанные с моделированием акустики речевого тракта. Были описаны допустимые во многих случаях упрощения и аппроксимации. Итогом статьи было приведение физической модели распространения звука в речевом тракте к простому дискретному фильтру.
В данной статье хочется с одной стороны продолжить предыдущие начинания, а с другой — немного отойти от фундаментальной теории и поговорить о более практических (более «инженерных») вещах. Кратко будет рассмотрена одна из прикладных моделей, часто применяемая при работе с речевым сигналом. Математическая база этого подхода, как это часто бывает, изначально была заложена в рамках исследований совершенно другой направленности. Тем не менее физические особенности речевого сигнала позволили применить данные идеи именно для его эффективного анализа и модификации.
Предыдущая статья, в силу специфики рассматриваемого вопроса, была перенасыщена научными терминами и формулами. В данной — мы постараемся вместо детального описания математических построений сделать акцент на идеологическую концепцию и качественные характеристики описываемой модели.
Далее будет более подробно рассмотрена теория модели LPC (Linear Prediction Coding) – замечательный стройных подход к описанию речевого сигнала, в прошлом определивший направление развития речевых технологий на несколько десятилетий и до сих пор часто применяемый, как один из базовых инструментов при анализе и описании речевого сигнала.
Три части обзорной статьи можно считать вводными к двум другим: «Играем в кубики с Kinect» и «Программа, апорт!». Хотя хронологически они идут последними. Более того, за время их написания Microsoft успел выпустить новую версию SDK – 1.5. Какой удар со стороны корпорации!
Как вам должно быть известно, Kinect – это бесконтактный контроллер, т.е. скажем в играх, вместо того, чтобы яростно стучать по клавиатуре или терзать gamepad, вы размахиваете руками и ногами и время от времени голосом даете какие-то команды. Самое время спрятать дорогие китайские вазы X века подальше!
Решение, позволяющее распознавать лицо человека и отслеживать положение губ, бровей, глаз в режиме реального времени. Компания SeeingMachines предоставляет API для сторонних разработчиков. Компания Ray-Ban довольно давно разместила на сайте flash-приложение, позволяющее примерить очки в реальном времени.
В последнее время я стал замечать, что большая часть пользователей «семерки» используют стандартную тему оформления, которую разработчики ласково назвали Aero.
На мой взгляд, она излишне ориентирована на планшеты. Об этом нам говорят огромные кнопки управления окном и излишне широкие заголовки и рамки окон — все это придает интерфейсу некоторую громоздкость. Кроме того, разработчики перемудрили с разнообразием цветовой гаммы: все эти прозрачности, переливания, градиенты и прочие изыски создают своеобразный эффект грязи.
Возможно, кому-то так нравится, кому-то безразлично, кто-то привык, а кто-то попросту не знает, что все это можно изменить.
Всем известно, что 90% информации мы воспринимаем визуально, в краткосрочной памяти может одновременно храниться от 5 до 9 объектов, а эпоха Twitter установила для текстов болевой порог в 140 знаков. Удержание внимания игроков (как и самих игроков) актуально даже для китов игровой индустрии, что уж говорить про небольшие компании, в которых от решения этой проблемы зависит жизнеспособность их проекта.
Official translation (with a bit of polishing) is available here.
Построение перспективного искажения
Четвёртая статья будет разбита на две, первая часть говорит про построение перспективного искажения, вторая про то, как двигать камеру и что из этого следует. Задача на сегодня — научиться генерировать вот такие картинки:
Интернет — неотъемлемая часть нашей жизни, невероятно сложная сеть, строившаяся на протяжении многих лет, фактически — это сеть кабелей, опоясывающих всю Землю, в том числе проходящая через моря и океаны. Человечество прошло долгий путь с момента прокладки первого трансатлантического подводного телеграфного кабеля в 1858 году между Соединенными Штатами и Великобританией. В этой статье мы расскажем о том, как Интернет преодолел «водные барьеры», многокилометровые глубины и подводные катаклизмы, какие сложности были на пути и как невероятно сложно поддерживать эту систему в связанном состоянии в наше время, каких колоссальных затрат средств и энергии это требует.
Недавно мы публиковали авторскую подборку ссылок от Зелёного кота на твиттер-аккаунты космической тематики. На этот раз, чтобы вам не было скучно в новогодние праздники, мы хотим поделиться твиттерами от IlyaAbilov, основателя студии озвучивания научно-популярных материалов Vert Dider, посвящённой популяризации науки. Под катом его рассказ, там можно найти очень много интересного, если вы хотите расширить свои научные знания и кругозор.
В свете последних топиков, в том числе «Autodesk не будет продавать ПО попавшим под санкции компаниям», появляется ощущение, что маховик абсурда все сильнее раскручивается. Мы не будем осуждать в этом топике политические причины всего этого безобразия, а подумаем немного о том, что произойдет, если внезапно «выключат Google», причем неважно с какой стороны. Также предлагаю рассмотреть один из вариантов забрать себе накопленный контент, используя открытое ПО.
Для начала давайте подумаем, что является наиболее ценным для большинства пользователей сервисов Google? В первую очередь, это личный контент, который хранится в облаке, почта и другие материалы. Во вторую очередь, это сервисы, которым нужно найти замену в кратчайшие сроки. Мы не будем рассматривать нужды профессиональных разработчиков под Android и корпоративные нужды.
Жак Фреско — это человек, который уже много лет занимается идеей организации социальных структур будущего, основанных не на традиционных моделях экономики и потребления, а на возможностях современной науки. Цель проекта — устойчивое развитие цивилизации без конфликтов.
Жак родился в 1916-м году и успел застать Великую Депрессию, затем получил хорошее образование и стал известен в качестве промдизайнера и архитектора. В последние годы он занимается тем, что рассказывает о несколько фантастичном проекте своей мечты. Буквально пару дней назад в Digital October прошла его лекция (прямой телемост) про этот проект.
Жак в своей творческой лаборатории
Вот основные тезисы:
Политическая система, которая хорошо работала 50 лет назад, сейчас уже устарела.
Большинству современных систем мы обязаны римлянам. Но у них было другое общество.
Мы уже произвели огромную базу знаний. Нам нужно развивать её, а не считать деньги.
Вот выкладки того, какими должны быть города, системы взаимоотношений и т.п.
Интеграция будет медленной и плавной, но это нужно делать.
Первое, с чего нужно начать — с изменения системы образования.
Второе — переход к некоей форме правления, похожей на коммунизм.
Третье — последовательная автоматизация всех рутинных процессов, включая правительственную работу.
Не желаете ли узнать о том, что Google знает о вас? Вот 6 ссылок, которые покажут вам некоторые данные, собранные гуглом.
1. Ваш профиль в Google
Google создаёт профиль с вашими основными данными – возраст, пол, интересы. Эти данные используются для показа релевантных объявлений. Вы можете просмотреть эту информацию здесь:
(прим.перев. – в моём случае гугл не блещет информацией. Я не состою в Google+, а по посещённым мною сайтам гугл не смог определить мой пол, а возраст определил в 65+ лет).
Приветствую, Хабрахабр. Сегодня я хочу, в своём обычном стиле, устроить сообществу небольшой ликбез по структурам данных. Только на этот раз он будет гораздо более всеобъемлющ, а его применения и практичность — простираться далеко в самые разнообразные области программирования. Самые красивые применения, я, конечно же, покажу и опишу непосредственно в статье.
Нам понадобится капелька абстрактного мышления, знание какого-нибудь сбалансированного дерева поиска (например, описанного мною ранее декартова дерева), умение читать простой код на C#, и желание применить полученные знания.
Итак, на повестке сегодняшнего дня — моноиды и их основное применение для кеширования вычислений в деревьях.
Моноид как концепция
Представьте себе множество чего угодно, множество, состоящее из объектов, которыми мы собираемся манипулировать. Назовём его M. На этом множестве мы вводим бинарную операцию, то есть функцию, которая паре элементов множества ставит в соответствие новый элемент. Здесь и далее эту абстрактную операцию мы будем обозначать "⊗", и записывать выражения в инфиксной форме: если a и b — элементы множества, то c = a ⊗ b — тоже какой-то элемент этого множества.
Например, рассмотрим все строки, существующие на свете. И рассмотрим операцию конкатенации строк, традиционно обозначаемую в математике "◦", а в большинстве языков программирования "+": "John" ◦ "Doe" = "JohnDoe". Здесь множество M — строки, а "◦" выступает в качестве операции "⊗". Или другой пример — функция fst, известная в функциональных языках при манипуляции с кортежами. Из двух своих аргументов она возвращает в качестве результата первый по порядку. Так, fst(5, 2) = 5; fst("foo", "bar") = "foo". Безразлично, на каком множестве рассматривать эту бинарную операцию, так что в вашей воле выбрать любое.
Далее мы на нашу операцию "⊗" накладываем ограничение ассоциативности. Это значит, что от неё требуется следующее: если с помощью "⊗" комбинируют последовательность объектов, то результат должен оставаться одинаковым вне зависимости от порядка применения "⊗". Более строго, для любых трёх объектов a, b и c должно иметь место: (a ⊗ b) ⊗ c = a ⊗ (b ⊗ c) Легко увидеть, что конкатенация строк ассоциативна: не важно, какое склеивание в последовательности строк выполнять раньше, а какое позже, в итоге все равно получится общая склейка всех строк в последовательности. То же касается и функции fst, ибо: fst(fst(a, b), c) = a fst(a, fst(b, c)) = a Цепочка применений fst к последовательности в любом порядке всё равно выдаст её головной элемент.
И последнее, что мы потребуем: в множестве M по отношению к операции должен существовать нейтральный элемент, или единица операции. Это такой объект, который можно комбинировать с любым элементом множества, и это не изменит последний. Формально выражаясь, если e — нейтральный элемент, то для любого a из множества имеет место: a ⊗ e = e ⊗ a = a В примере со строками нейтральным элементом выступает пустая строка "": с какой стороны к какой строке её ни приклеивай, строка не поменяется. А вот fst в этом отношении нам устроит подлянку: нейтральный элемент для неё придумать невозможно. Ведь fst(e, a) = e всегда, и если a ≠ e, то свойство нейтральности мы теряем. Можно, конечно, рассмотреть fst на множестве из одного элемента, но кому такая скука нужна? :)
Каждую такую тройку <M, ⊗, e> мы и будем торжественно называть моноидом. Зафиксируем это знание в коде:
public interface IMonoid<T> {
T Zero { get; }
T Append(T a, T b);
}
Больше примеров моноидов, а также где мы их, собственно, применять будем, лежит под катом.
Здравствуй, Хабр. Большинство из нас так или иначе работает со строками. Этого не избежать — если ты пишешь код, ты обречен каждый день складывать строки, разбивать их на составные части и обращаться к отдельным символам по индексу. Мы давно привыкли что строки — это массивы символов фиксированной длины, а это влечет за собой соответствующие ограничения в работе с ними. Так, мы не можем быстро объединить две строки — для этого нам потребуется сначала выделить необходимое количество памяти, а потом скопировать туда данные из конкатенируемых строк. Очевидно, что такая операция имеет сложность порядка О(n), где n — суммарная длина строк. Именно поэтому код
string s = "";
for (int i = 0; i < 100000; i++) s += "a";
работает так медленно.
Хочешь выполнять конкатенацию гигантских строк быстро? Не нравится, что строка требует для хранения непрерывную область памяти? Надоело использовать буферы для построения строк?
В 1973 году на первом ежегодном симпозиуме «Принципы языков программирования» (Principles of Programming Languages Symposium) Вон Пратт представил статью «Нисходящий парсер с операторным предшествованием» (Top Down Operator Precedence). В этой статье Пратт описал метод синтаксического разбора, который объединяет лучшие стороны рекурсивного спуска и метода операторного предшествования Флойда. Метод Пратта очень похож на рекурсивный спуск, но требует меньше кода и работает гораздо быстрее. Пратт заявил, что его метод прост в освоении, реализации и использовании, необычайно эффективен и очень гибок. Благодаря своей динамичности он может использоваться для расширяемых языков.
Но если метод действительно безупречен, почему же разработчики компиляторов по сей день его игнорируют? В своей статье Пратт предположил, что БНФ-грамматики и их многочисленные модификации, а также связанные с ними теоремы и автоматы заняли нишу раньше и теперь препятствуют развитию теории синтаксического анализа в других направлениях.
Есть и другое объяснение: этот метод наиболее эффективен для динамических, функциональных языков программирования и использовать его в статическом, процедурном языке куда сложнее. Свою статью Пратт иллюстрирует на примере Lisp и играючи строит синтаксические деревья по потоку лексем. Но методы синтаксического разбора не особо ценятся в сообществе Lisp-программистов, которые проповедуют спартанский отказ от синтаксиса. С момента создания Lisp предпринималось немало попыток придать этому языку богатый синтаксис в стиле ALGOL: CGOL Пратта, Lisp-2, MLISP, Dylan, Interlisp's Clisp, оригинальные М-выражения Маккарти и так далее. Но все они провалились. Для Lisp-сообщества согласованность программ и данных оказалась важнее выразительного синтаксиса. С другой стороны, подавляющее большинство программистов любит синтаксис, поэтому сам Lisp так и не стал популярен. Методу Пратта нужен динамический язык, но сообщество динамических языков исторически не пользовалось синтаксисом, который так удобно реализуется методом Пратта.
Следующая часть книги расскажет о веб-браузерах. Без них не было бы JavaScript. А если бы и был, никто бы не обратил на него внимания.
Технологии веба с самого начала были децентрализованными – не только технически, но и с точки зрения их эволюции. Различные разработчики браузеров добавляли новую функциональность «по случаю», непродуманно, и часто эта функциональность обретала поддержку в других браузерах и становилась стандартом.
Это и благословление и проклятие. С одной стороны, здорово не иметь контролирующего центра, чтобы технология развивалась различными сторонами, иногда сотрудничающими, иногда конкурирующими. С другой – бессистемное развитие языка привело к тому, что результат не является ярким примером внутренней согласованности. Некоторые части привносят путаницу и беспорядок.
В посте я постарался избежать сложных дефиниций и строгих матетематических доказательств, а некоторые вещи вообще понятны интуитивно. Алгоритм удобно разбивается на взаимосвязные части, поэтому и уловить принцип его работы не должно составлять труда.
Начальное описание
Алгоритм Ахо-Корасик реализует эффективный поиск всех вхождений всех строк-образцов в заданную строку. Был разработан в 1975 году Альфредом Ахо и Маргарет Корасик. Опишем формально условие задачи. На вход поступают несколько строк pattern[i] и строка s. Наша задача — найти все возможные вхождения строк pattern[i] в s.
Суть алгоритма заключена в использование структуры данных — бора и построения по нему конечного детерминированного автомата. Важно помнить, что задача поиска подстроки в строки тривиально реализуется за квадратичное время, поэтому для эффективной работы важно, чтоб все части Ахо-Корасика ассимптотически не превосходили линию относительно длинны строк. Мы вернемся к оценке сложности в конце, а пока поближе посмотрим на составляющие алгоритма.
Для обеспечения работы всех наших внешних продуктов мы используем популярный nginx. Это быстро и это надежно. Проблем с ним почти нет. Наши продукты также постоянно развиваются, появляются новые сервисы, добавляется новый функционал, расширяется старый. Аудитория и нагрузка только растет. Сейчас мы хотим рассказать о том, как мы ускорили разработку, неплохо увеличили производительность и упростили добавление в наши сервисы этого нового функционала, при этом сохранив доступность и отказоустойчивость затронутых приложений. Речь пойдет о концепции “nginx as web application”. А именно, о сторонних модулях (в основном LUA), позволяющих делать совершенно магические вещи быстро и надежно.
Когда заходит разговор о кешировании складывается парадоксальная ситуация. С одной стороны все понимают важность и нужность кеширования в архитектуре приложений. С другой стороны мало кто может внятно объяснить что и как надо кешировать.
Обычно люди сходу начинают предлагать готовые реализации кеша, вроде memcached или HTTP-кеша, но это лишь ответ на вопрос где кешировать.
Кеширование – одна из многих тем, наряду с безопасностью и логированием, о которых знают и говорят все, но мало кто может это сделать правильно.
Electronic Frontier Foundation (EFF), Фонд Электронных Рубежей, некоммерческая правозащитная организация, от имени 77 учёных-компьютерщиков требуют от судей верховного суда пересмотра решения, согласно которому API (программный интерфейс для приложений) может быть объектом защиты авторских прав, как сообщает официальный сайт EFF. Это решение, принятое в мае, перевернуло с ног на голову сложившуюся за десятилетия практику.
Под петицией подписались пятеро обладателей Премии Тьюринга, четыре медалиста Национальной Технологической Премии, и множество людей из Ассоциации вычислительной техники, Института инженеров электротехники и электроники, и Американской академии науки и искусств. В списке также есть разработчики таких компьютерных систем и языков программирования, как AppleScript, AWK, C++, Haskell, IBM S/360, Java, JavaScript, Lotus 1-2-3, MS-DOS, Python, Scala, SmallTalk, TCP/IP, Unix, и Wiki.
Так сложилось, что за последние пару лет я успел поучаствовать в разработке нескольких социальных сетей. Главная задача, которую приходилось решать в каждом из этих проектов, заключалась в формировании новостной ленты пользователя. При чём важным условием была возможность масштабирования этой ленты в условиях роста числа пользователей (точнее, числа связей между ними) и, как следствие, — количества контента, который они деливерят друг другу.
Мой рассказ будет о том, как я, превозмогая трудности, решал задачу формирования новостной ленты. А также я расскажу о подходах, которые наработали ребята из проекта Socialite, и которыми они поделились на MongoDB World.
Не так давно было много шума об инициатике CommonMark по унификации маркдауна. Казалось бы, наконец-то в этой замечательной разметке наступит порядок. Но на практике не все так просто. Сейчас ведется работа над базовым синтаксисом, и до расширений дело дойдет не скоро. Ждать год с лишним могут не все. Но разработки спецификаций — это скорее научная работа. Нас же интересует практика — как приворачивать маркдаун к конкретным проектам.
Что же может потребоваться программисту от хорошего парсера маркдауна? Ну конечно же не скорость :). А нужна на самом деле возможность добавлять свои расширения синтаксиса. К сожалению, во всех реализациях парсеров, что я до этого встречал, логика разбора разметки приколочена намертво. Все что остается — ковырять гвоздиком конечный результат и надеяться что конфликтов не случится. Конечно, гарантировать при этом надежный выхлоп невозможно. Можно пойти другим путем — попробовать заслать патч в апстрим. Но тут нет ни каких гарантий, что синтаксис вашего расширения будет нужен кому-то еще кроме вас, и что ваш код будет принят.
Как же быть? К счастью, теперь у нас есть markdown-it!
О чем вы думаете, когда слышите слово «экзоскелет»? Скорее всего, о Железном Человеке или о громоздких конструкциях, подключенных к электросети и оснащенных здоровенными пулеметами. Во всяком случае у меня эти мысли — первые. Но в данном случае это не экзоскелет, а экзокостюм. В основном он выполнен из ткани и он очень легкий. DARPA сейчас влила в этот проект почти три миллиона долларов в рамках программы «Warrior Web».
Честно говоря, я давно ждал этого события. На днях оно случилось. Открыт общественный краудфандинг-биржа, где принимаются ставки на убийство общественных деятелей. Схема простая: кто-то вносит имя в блэк-лист, остальные люди, которым тоже не нравится сей деятель и которые желают от него быстрее избавиться, вносят пожертвования через биткоины. В один прекрасный момент, собранная сумма становится привлекательной для киллера-маньяка, он пишет авторам сайта сообщение (делает ставку), мол, тогда-то и тогда-то умрет такой-то человечек из вашего списочка. Если человек действительно умирает, убийца срывает банк и забирает все деньги. Все счастливы (почти все). Конечно, к сервису два главных вопроса.
В подавляющем большинстве изделия класса «настольные игрушки» не отличаются разнообразием. Но этого не скажешь об этих маленьких «существах», которые являются миниатюрными версиями гигантских самоходных конструкций авторства голландца Тео Янсена.
Эти конструкции, которыми он прославился, Янсен называет Strandbeest. Каждый из этих невероятных механизмов состит из сотен движущихся частей, и зрелище просто завораживающее:
Человеку давно свойственно интересоваться окружающим миром и находить объяснения тому окружающим вещам и событиям. Собственно, без этого человек не стал бы человеком. На базе верований, мифов развивалась сначала религия, а потом — и современная наука, которая уже весьма успешно объясняет окружающий мир от очень малых до впечатляющих масштабов. Но всегда оставались люди, которые противились прогрессу и распространяли устоявшиеся мифы, уверяя, что они отвечают на все вопросы и незачем двигаться дальше. Гром гремит — это Перун-громовержец злится; кто-то заболел — это Бог его наказывает, вот тебе объяснения, отстань, не задавай вопросов, а лучше помолись. Современные мифы более глубоки и обычно связаны с наукой. Причины понятна — наука развилась (особенно в последнее время) до такой степени, что часто нужен колоссальный объем знаний, чтобы просто понять, о чем вообще идет речь. У многих людей этого объема нет или безвозвратно потерян, что и снижает их сопротивляемость к разного рода мифам нашего времени. Миф про вредность пищевых добавок Exxx; миф про полезность натурального и вредность «химии»; миф про врачей-убийц, травящих людей прививками; миф про настолько страшное ГМО, что наклейки с надписью «без ГМО» надо клеить даже на салфетки и на пачки с солью. Что такое ГМО? Зачем они нужны? Как велика опасность и польза от их использования? Есть ли доказательства безопасности этих организмов?
Если вы кого-нибудь спросите, на чем он делает клиентскую сторону своих приложений сегодня, этот человек наверняка ответит, что использует какой-нибудь хипстерский JS-фреймворк, вроде Angular, Ember, Knockout, Backbone или Polymer (смотрите сайт TodoMVC).
У большинства этих фреймворков есть «отличная» возможность, которая позволяет вам «легко» ссылаться на какую-либо информацию, используя дата-биндинги. Они выглядят примерно так:
Переписывал в островке кусок одного сервиса с Python на Erlang. Сам сервис занимается тем, что скачивает по HTTP значительное количество однотипных HTML страниц и извлекает из них некоторую информацию. Основная CPU нагрузка сервиса приходится на парсинг HTML в DOM дерево.
Сперва захотелось сравнить производительность Erlang парсера mochiweb_html с используемым из Python lxml.etree.HTML(). Провел простейший бенчмарк, нужные выводы сделал, а потом подумал что неплохо было бы добавить в бенчмарк ещё парочку-другую парсеров и платформ, оформить покрасивее, опубликовать код и написать статью. На данный момент успел написать бенчмарки на Erlang, Python, PyPy, NodeJS и С в следующих комбинациях:
Erlang — mochiweb_html
CPython — lxml.etree.HTML
CPython — BeautifulSoup 3
CPython — BeautifulSoup 4
CPython — html5lib
PyPy — BeautifulSoup 3
PyPy — BeautifulSoup 4
PyPy — html5lib
Node.JS — cheerio
Node.JS — htmlparser
Node.JS — jsdom
C — libxml2 (скорее для справки)
В тесте сравниваются скорость обработки N итераций парсера и пиковое потребление памяти.
Интрига: кто быстрее — Python или PyPy? Как сказывается иммутабельность Erlang на скорости парсинга и потреблении памяти? Насколько быстра V8 NodeJS? И как на всё это смотрит код на чистом C.
Удачная возможность для веб-разработчиков выучить язык программирования Си — HTML5-парсер Gumbo, реализованный в виде небольшой библиотеки C99 без внешних зависимостей. Парсер создан как строительный блок для создания других инструментов и библиотек, таких как валидаторы, языки шаблонов, инструменты рефакторинга и анализа кода.
В Perl заложено огромное количество возможностей, которые, на первый взгляд, выглядят лишними, а в неопытных руках могут вообще приводить к появлению багов. Доходит до того, что многие программисты, регулярно пишущие на Perl, даже не подозревают о полном функционале этого языка! Причина этого, как нам кажется, заключается в низком качестве и сомнительном содержании литературы для быстрого старта в области программирования на Perl. Это не касается только книг с Ламой, Альпакой и Верблюдом («Learning Perl», «Intermediate Perl» и «Programming Perl») — мы настоятельно рекомендуем их прочитать.
В этой статье мы хотим подробно рассказать о маленьких хитростях работы с Perl, касающихся необычного использования функций, которые могут пригодится всем, кто интересуется этим языком.
Первый рабочий день. Первая задача в Redmine. Первая спецификация в формате doc. На новой рабочей машине. К чтению спецификации удалось приступить часа через 3. Пока скачался и установился MS Office. Вспоминая этот случай, я был уверен, что в нашей системе управления задачами надо сделать онлайн просмотр документов. Вот только идей по реализации за разумное время и трудозатраты не было. Недавно мы нашли способ – Microsoft Office Web Apps.
В этой статье пойдет речь о том, как добавить онлайн просмотр документов в любой продукт.
Классическая теория эффективной виртуализации и обзор состояния индустрии в целом описаны в моей предыдущей публикации. В этой статье речь пойдёт о поддержке виртуализации в широком смысле в архитектуре Intel IA-32.
Черепаха на спине черепахи на спине черепахи на спине… — космологическая теория, которой придерживаются создатели виртуальных машин.
Эта статья — нулевая в небольшой серии о технологиях Intel, помогающих представить компьютер не тем, чем он в реальности является, для программ (в т.ч. операционных систем, BIOS и прошивок), на нём запущенных. В ней не будет говориться о настройке конкретных VMM, прозрачной миграции виртуальных машин, создании невидимых руткитов и многих других интереснейших вещах, произрастающих из этой фрактальной и потому неисчерпаемой темы. Мой взгляд будет с позиции системного программиста, занимающегося разработкой операционных систем и firmware или мониторов виртуальных машин и симуляторов, а также всех им сочувствующих.
Привет, Хабр! Ничего не писал со времен своей первой статьи, решил, что пора это исправить.
Существует мнение, что про геймдев внятной литературы почти нет, все знания надо получать практическим путем. С моей точки зрения, в этом мнении есть зерно истины, тем не менее, я не могу полностью с ним согласиться.
Ниже я даю рецензии на книжки, которые считаю очень полезными в различных разделах computer science, которые используются в геймдеве. Я намеренно опускаю книги по C++ и алгоритмам: мне кажется, эта тема уже настолько изучена и освещена, что больше про нее не стоит рассказывать.
Я старался покрыть максимальное количество разных топиков, особенно тех, что спрашивают на собеседованиях. Я старался воздерживаться от domain-specific литературы: профессионалы и так знают. Все картинки содержат ссылки на амазон.
А какие книжки нравятся вам? Также в комментах можете писать, на какие темы вам были бы интересны посты.
Не так давно в OpenSSL была обнаружена уязвимость, о которой не говорит только ленивый. Я знаю, что PVS-Studio не способен найти ошибку, которая приводит к этой уязвимости. Поэтому я решил, что нет повода писать какую-либо статью про OpenSSL. В последние дни и так слишком много стало статей на эту тему. Однако, я получил шквал писем с просьбой рассказать, может ли PVS-Studio найти эту ошибку. Я сдался и написал эту статью.
Двое суток осталось до окончания кампании на Kickstarter по сбору средств на «Project PERCEPTION NEURON: Motion Capture, VR and VFX». Недавно на Хабре о ней уже проскакивала миниатюрная заметка. Считаю, что это устройство заслуживает большего внимания, тем более, что с момента старта кампании выяснилось довольно много интересных подробностей и добавились новые фичи.
В последнее время я увлёкся темой зависимости от C Runtime в проектах, написанных на Visual C++. Вернее, темой избавления от зависимости от Visual C++ Redistributable, ведь если проект представляет собой небольшую библиотеку интеграции или простейшую утилиту, таскать за собой целый распространяемый пакет не очень удобно.
На Хабре уже была статья на данную тему, однако я в процессе своих экспериментов столкнулся с некоторыми проблемами. Об этих проблемах и о способе их решения и пойдёт речь.
Сразу оговорюсь, что я изначально ожидаю, в целом, справедливой критики на счёт правильности подхода к проблемам и вообще в целом линковки с msvcrt.dll — да, это не поддерживаемое Microsoft решение, да, это решение больше подходит для новых проектов, и да, возможно, придётся отказаться от многих плюшек, но ведь это используют, да и кто не рискует… В общем, все, кому интересна эта тема, как и мне, — прошу под кат.
Заранее прошу прощения за заголовок: я старался перевести фразу «Linking to msvcrt.dll in Visual C++». Статья моя, это не перевод, но название всё-таки проще сформулировать на английском.
В первой части мы познакомились с использованием Fossil в однопользовательском режиме на одном рабочем месте. Следующий шаг — перенос репозитория на другой компьютер — с работы на домашний, или на ноутбук, который мы берем с собой в поездку. Самый простой вариант — это просто скопировать репозиторий, благо это всего один файл, на новое рабочее место. Можно так и сделать, но самое простое решение не всегда самое лучшее, есть вероятность, что возникнут небольшие проблемы.
Относительно недавно здесь публиковался опрос по используемым системам контроля версий. Как и ожидалось, с большим отрывом победил Git, а Fossil даже не был включен в список, только в комментариях пару раз промелькнул. Поиск по Хабру показал, что здесь о Fossil практически ничего не писали. Поэтому я и решил опубликовать эту статью — тем более, что русскоязычная информация о Fossil крайне скудна и однообразна.
Не так давно, а именно 5 июня хабрачеловек по имени alan008 задал вопрос. Чтобы не заставлять ходить за подробностями, приведу его здесь:
Нужна помощь!
За несколько лет с разных трекеров (преимущественно c rutracker'а) разными клиентами (преимущественно uTorrent'ом) скачано много гигабайт разного полезного контента. Скачанные файлы впоследствии вручную перемещались с одного диска на другой, uTorrent их соответственно не видит. Многие .torrent файлы устарели сами по себе (например, велась раздача сериала путем добавления новых серий заменой .torrent файла).
Теперь сам вопрос: есть ли способ автоматически (не вручную) установить соответствие между имеющимися на компьютере .torrent файлами и содержимым, раскиданным по разным логическим дискам компьютера? Цель: удалить лишние (неактуальные) .torrent файлы, а для актуальных — поставить всё на раздачу. У кого какие идеи? :)
При необходимости (если это требуется) можно снова поместить все файлы данных в один каталог на одном логическом диске.
В обсуждениях сошлись на том, что если это и можно сделать, то только ручками. Мне же этот вопрос показался интересным, и после возвращения из отпуска я нашел время, чтобы в нем разобраться.
Потратив в общей сложности неделю на разбор формата .torrent-файла, поиск нормально работающей библиотеки для его парсинга, я приступил к написанию программы, которая позволит решить проблему затронутую в упомянутом вопросе.
Прежде чем начать, стоит отметить несколько моментов:
Получилось много, но не все.
По формату файла .torrent будут даны лишь необходимые пояснения.
Людей, чувствительных к временами некачественному коду, прошу меня заранее простить — я знаю, что многое можно было написать лучше, оптимальнее и безглючнее.
Для тех, кому интересно, что из этого получилось, технические подробности и подводные камни — прошу под кат.
HTML-импорт упрощает загрузку и повторное использование кода. В частности, это хороший способ распространения веб-компонентов. Это касается как простых HTML , так и полноценных кастомных элементов с теневым DOM [1, 2, 3]. Когда эти технологии работают вместе, импорт становится инструментом для подключения веб-компонентов.
Перевод статьи «HTML Imports #include for the web», Eric Bidelman.
От переводчика
Недавно я перевел статью по основам HTML Import. Я обещал, что если эта тема заинтересует хабра-сообщество, то переведу более подробную статью. Я решил разбить перевод на две одинаковые по размеру части, так как, по моему, на одну часть слишком много буков. Вторая часть выйдет спустя несколько дней после публикации этой части. Если, конечно, эта часть более-менее понравится хабра-сообществу.
Для чего нужен HTML-импорт?
Давайте поговорим о том, как мы загружаем различные ресурсы. JavaScript мы загружаем при помощи
<script src>
. Для CSS у нас есть
<link rel="stylesheet">
. Для изображений
<img>
. Для видео есть
<video>
. Для аудио —
<audio>
… Давайте ближе к сути! Для большинства видов контента есть простые способы его подгрузки. Но не для HTML. Для HTML у нас есть следующие варианты:
<iframe>
— испробованный и рабочий, но тяжеловесный способ. Контент iframe'а живет в отдельном от главной страницы контексте. Хоть это и хорошая особенность, она также создает дополнительные трудности: подгонка размера айфрейма к его содержимому, работа с внутренними скриптами и стилями.
AJAX — мне нравится
xhr.responseType="document"
, но загрузка HTML при помощи JS выглядит как-то неправильно.
КривыеКостылиTM — html код в виде JS строк или комментариев, например
<script type="text/html">
.
HTML код, это самый простой тип контента, но в этом плане, он требует наибольших усилий. Хорошо, что у нас есть Web Components, они помогут нам справиться с этой и другими проблемами.
Редактор разрабатывается уже около 5 лет, пережил два прототипа и полное переписывание… И всё ещё находится в стадии активной разработки.
Вероятно, я бы не созрел написать эту статью ещё несколько лет, пока редактор не будет на 100% вылизан и функционален. Но как верно заметили мои коллеги — этого не будет никогда. Поэтому идеалист внутри был слегка придушен, результатом чего стало написание этой статьи.
Deus Ex Human Revolution — произведение искусства в лучших традициях киберпанка, своего рода IT-RPG. Игра отличная и стильная с крутым сюжетом и массой проработанных деталей. Но самое, на мой взгляд, крутое в ней – это система диалогов как механика.
Сейчас объясню в чём дело. Посмотрите на вот эти два скриншота: первый из Fallout II, второй из нового Deus Ex.
Старая добрая диалоговая система
Диалог в Deus Ex с установленным в голову социальным модулем
Перевод статьи «What are HTML Imports and How Do They Work?», Paula Borowska.
Вы когда-нибудь замечали, что включение одной HTML страницы в другую, это какая-то инородная концепция? Это то, что должно быть просто, но не это не часто происходит. Это не невозможно, но трудно. К счастью есть HTML импорт, который позволяет запросто помещать HTML страницы, а также CSS и JavaScript файлы, внутрь других HTML страниц.
Введение в HTML импорт
HTML импорт, это простая для понимания вещь; это способ вставки на страницу других HTML страниц. Вы можете сказать, что в этом нет ничего особенного, так вот есть; раньше вы не могли это так просто сделать.
Интересно то, что HTML это самые простые файлы, но иногда с ними труднее всего работать. Даже PHP файлы имеют возможность включения, почему же HTML этого не может? Благодаря веб-компонентам, мы, теперь, можем включать одни HTML документы в другие. Также, при помощи этого же тега, мы можем подключать CSS и JavaScript. (Жить стало намного лучше.)
Определить наиболее оптимальный алгоритм под задачи распознавания мимики человеческого лица, рассмотреть способы его реализации.
Задачи:
Провести анализ существующих алгоритмов распознавания мимики, учитывая определённые нами доминирующие признаки классификации и математической модели. На основании полученных данных выбрать оптимальный вариант алгоритма для последующей его реализации и апробации.
Введение
В предыдущих научных отчётах была разработана математическая модель распознавания мимики, и был синтезирован алгоритм распознавания мимики. Существуют два подхода в распознавании мимики – использование деформируемой модели на области губ и выхватывание векторных признаков области губ с последующим их анализом с помощью алгоритмов на основе гауссовых смесей. Для реализации распознавания мимики необходимо выбрать оптимальный алгоритм.
1. Алгоритмы распознавания человеческого лица:
1.1 Алгоритмы, основанные на деформируемой модели.
Деформируемая модель (deformable template model) – это шаблон некоторой формы (для двумерного случая — открытая либо замкнутая кривая, для трехмерного — поверхность). Наложенный на изображение, шаблон деформируется под воздействием различных сил, внутренних (определенных для каждого конкретного шаблона) и внешних (определенных изображением, на которое наложен шаблон) — модель меняет свою форму, подстраиваясь под входные данные [1]. Исходная грубая модель губ деформируется под действием силовых полей, заданных входным изображением (Рис.1). Основное преимущество над традиционными методами поиска, такими как преобразование Хафа (Hough transform [2]), в которых шаблон для поиска задается жестко, заключается в том, что деформируемые модели в процессе работы могут менять свою форму, позволяя более гибко осуществлять поиск объекта [3].
Основной недостаток деформируемых моделей [4] заключается в необходимости проведения большого числа итераций над большим количеством кадров, что значительно нагружает систему, но при вынесении основных вычислений в облако можно разгрузить систему.
Деформируемые модели можно классифицировать по типу ограничений, накладываемых на их форму, на два вида: деформируемые модели свободной формы и параметрические деформируемые модели.
Oovee Game Studios, одна из восходящих звезд Объединенного Королевства вышла на Кикстартер с дебютным проектом «Spintiers». Событие хоть и отмеченное на известном британском новостном ресурсе Rock Paper Shotgun (что уже само по себе говорит за игру), но, к сожалению, не вызвавшее достаточного резонанса среди игроков. Причины могут быть разными и не последняя из них – жанр. Это не гоночный симулятор, не полноценный симулятор дальнобойщика, а симулятор «месителя грязи». По крайней мере, из демо-версии складывается именно такое впечатление. Однако, даже демо-версия намного глубже чем кажется, даже если не проваливаться в колею. Если присмотреться – это отличнейшая база под будущую игру, необычный сеттинг не без изюминок.
А ведь в демо, между прочим, представлен шикарный парк отечественного автомобилестроения. При должном исполнении это может сделать ее своеобразным Сталкером от мира колес. Из чрева железных монстров при переключении коробки передач доносится забористая русская речь, вокруг расстилается живописная тайга, прорезанная линиями разбитых троп и дорог, и ведь елки-палки… все действительно родное, от и до. Как так? В Британии появились поклонники колесного русского духа? Вопрос на миллион долларов.
Что еще можно сказать об этой игре? Перво-наперво то, что Spin Tires не игра, а демонстрация физического движка Havok. Техническая демо-версия, созданная специально для конкурса Havok Physics Innovation Contest. Особенностями этой демо-версии стало наличие «физичных» покрытий (вода, грязь) и взаимодействие с ними объектов (грузовых и не очень автомобилей), деформация грязевых и водных участков ландшафта в реальном времени, очень красивое и эффектное освещение. Как это часто бывает в случае удачных решений – демо постепенно начало превращаться в игру. Именно с этим демо Oovee Game Studios и обратилась к игрокам, чтобы собрать средства на полноценную игру.
Все выше сказанное — легкий набросок собственных эмоций на базе доступной и типовой информации, которую легко можно почерпнуть в сети. А что произойдет, если копнуть глубже?
Определить доминирующие признаки классификации объекта локализации и разработать математическую модель под задачи анализа изображений мимики.
Задачи
Поиск и анализ способов локализации лица, определение доминирующих признаков классификации, разработка математической модели оптимальной под задачи распознавания движения мимики.
Тема
Помимо определения оптимального цветового пространства для построения выделяющихся объектов на заданном классе изображения, которая проводилась на предыдущем этапе исследования, немаловажное значение также играет определение доминирующих признаков классификации и разработка математической модели изображений мимики.
Для решения данной задачи необходимо, прежде всего, задать системе особенности модификации задачи обнаружения лица видеокамерой, а затем уже проводить локализацию движения губ.
Что касается первой задачи, то следует выделить две их разновидности: • Локализация лица (Face localization); • Отслеживание перемещения лица (Face tracking) [1]. Так как перед нами стоит задача разработки алгоритма распознавания мимики, то логично предположить, что данную систему будет использовать один пользователь, который не слишком активно будет двигать головой. Следовательно, для реализации технологии распознавания движения губ необходимо взять за основу упрощенный вариант задачи обнаружения, где на изображении присутствует одно и только одно лицо.
А это значит, что поиск лица можно будет проводить сравнительно редко (порядка 10 кадров/сек. и даже менее). Вместе с тем, движения губ говорящего во время разговора являются достаточно активными, а, следовательно, оценка их контура должна проводиться с большей интенсивностью.
Мне нравится рефакторинг. Нет, не так. Я люблю рефакторинг. Не, даже не так. Я чертовски люблю рефакторинг. Я не переношу плохой код и плохую архитектуру. Меня коробит, когда я пишу новую фичу, а в соседнем классе творится полный бардак. Я просто не могу смотреть на печально названные переменные. Иногда перед сном я закрываю глаза и представляю, что можно было бы улучшить в проекте. Иногда я просыпаюсь в три часа ночи и иду к ноутбуку, чтобы что-нибудь поправить. Мне хочется, чтобы на любой стадии разработки код был не просто кодом, а произведением искусства, на которое приятно смотреть, с которым приятно работать.
Если вы хоть немного разделяете мои ощущения, то нам есть о чём поговорить. Дело в том, что со временем что-то внутри меня начало подсказывать, что рефакторить всё подряд, везде и всё время — не самая лучшая идея. Поймите меня правильно, код должен быть хорошим (а лучше бы ему быть идеальным), но в условиях суровой реальности не всегда разумно постоянно заниматься улучшением кода. Я вывел для себя несколько правил о своевременности рефакторинга. Если у меня начинают чесаться руки что-нибудь улучшить, то я оглядываюсь на эти правила и начинаю думать: «А действительно ли сейчас тот момент, когда нужно нарефакторить?». Давайте порассуждаем о том, в каких же случаях рефакторинг уместен, а в каких — не очень.
История кинематографа неразрывно связана с историей спецэффектов. От первых примитивных уловок с освещением и фальшивых кинжалов в немом кино, до целых миров и невероятно реалистичных существ, которых никогда не существовало. Сейчас практически ВСЕ фильмы с приличным бюджетом в той или иной степени используют виртуальные декорации.
Что первично в кино — сюжет или игра актёров? Спецэффекты или мастерство оператора-постановщика? Безусловно, все эти составляющие крайне важны. Но, всё же, некоторые фильмы стали знамениты именно благодаря использованным спецэффектам. И пусть сегодня некоторые из них выглядят обыденно, а некоторые наивно, в своё время они стали вехами в кинематографе. Конечно, вообще таких фильмов было много. Но мало кто может похвастаться спецэффектами, исключительно благодаря которым стало возможно рассказать задуманную историю. Такими спецэффектами, которые не просто вызывали вау-эффект, а действительно брали за душу. Которые заставляли сопереживать главному герою, проникаться ситуациями, в которых он оказывался. Давайте вспомним о некоторых из таких знаковых фильмов.
Ребята из Official.fm Labs задумали совершить настоящую звуковую революцию в вебе: две недели назад они выпустили FLAC.js — декодер аудиофайлов формата FLAC (Free Lossless Audio Codec), а также Aurora.js — фреймворк на CoffeeScript для простого подключения декодеров и создания веб-приложений, работающих со звуком. Таким образом, через Web Audio API теперь можно слушать музыку в идеальном качестве, и все веб-приложения могут обращаться к звуковой карте стандартным образом.
JavaScript уже так могуч, что браузер декодирует звук, потребляя менее 5% ресурсов CPU. Можно представить, какие крутые звуковые редакторы, миксеры и прочие аудиоприложения появятся в вебе в ближайшее время.
В данной статье, состоящей из двух частей, речь пойдёт об использовании возможностей процедурных генераторов при создании контента для компьютерной игры Oil Rush и бенчмарка Valley (выйдет в феврале), разработанных на нашем собственном движке Unigine.
Специалист по дата-майнингу и визуализации данных Майк Босток (Mike Bostock) опубликовал великолепную подборку с визуализацией различных алгоритмов.
Работа уникальная, в своём роде, потому что в этом случае графическое отображение особенно сложно сделать: ведь, по сути, нет данных для анализа. «Но алгоритмы также демонстрируют, что визуализация — это больше, чем просто инструмент для поиска закономерностей среди данных, — пишет Майк Босток. — Визуализация использует зрительную систему человека, чтобы расширить человеческий интеллект: с её помощью мы лучше понимаем важные абстрактные процессы и, надеюсь, другие вещи тоже».
Множество людей, включая дизайнеров, думают, что типографика – это только выбор гарнитуры, размера шрифта и того, должен ли он быть нормальным или полужирным. Для большинства людей на этом все и заканчивается. Но для получения хорошей типографики нужно гораздо больше и как правило это детали, которые дизайнеры часто игнорируют. Эти детали дают дизайнеру полный контроль, позволяет ему создавать прекрасные и последовательные с точки зрения типографики решения в дизайне. Хотя все это применимо для различных типов носителей, в этой статье мы сосредоточимся на том, как их применить к веб-дизайну с использованием CSS. Вот 8 простых путей с помощью CSS улучшить типографику и, следовательно, общее удобство дизайна.
Уже немало копий front-end разработчиков было сломано об проблему стилизации поля ввода input[type=file]. Суть проблемы заключается в том, что в спецификации HTML нет строгих правил, устанавливающих, как же должен отображаться браузером этот элемент. Более того, для input[type=file] не предусмотрено атрибутов, которые позволили бы изменить его внешний вид, с помощью стилей CSS можно изменить лишь вид его границы и шрифт, а средствами JavaScript, из соображений безопасности, нельзя сымитировать клик по этому элементу, который вызвал бы системное окно для выбора файла*. Но что же делать, когда заказчик хочет адаптивный сайт с красивыми стилизованными формами, в которых нельзя обойтись без этого поля ввода?
* — на момент написания этой статьи, мне было еще неизвестно, что уже во всех современных браузерах имитация клика по input[type=file] вызывает системное окно выбора файла. Большое спасибо lutov за ценный комментарий с ссылкой на рабочий пример от Pagefest!
Здарствуй Хабр! Статья посвящена оптимизации изображений формата SVG.
SVG (от англ. Scalable Vector Graphics — масштабируемая векторная графика) — язык разметки масштабируемой векторной графики, созданный Консорциумом Всемирной паутины (W3C) и входящий в подмножество расширяемого языка разметки XML, предназначен для описания двумерной векторной и смешанной векторно/растровой графики в формате XML.
Один из сотрудников Google в свободное время разработал новый алгоритм сжатия Zopfli, который на 3,7-8,3% эффективнее, чем стандартная библиотека zlib на максимальном уровне сжатия. Изначально алгоритм создавался для формата сжатия без потерь WebP, но его можно применять и для другого контента.
Новый алгоритм является реализацией стандартных алгоритмов Deflate, поэтому он совместим с zlib и gzip, а разархивирование данных уже поддерживается всеми браузерами. Достаточно подключить Zopfli на сервере. Например, его можно использовать с веб-сервером Nginx без изменений в модуле gzip, просто указав новый «прекомпрессор».
Правда, сжатие с помощью Zopfli требует примерно в 100 раз больше ресурсов, чем gzip, зато декомпрессия в браузере осуществляется с той же скоростью.
Soundex — один из алгоритмов сравнения двух строк по их звучанию. Был разработан чуть менее 100 лет назад Робертом Расселом и Маргарет Оделл. Активно используется в США при диктовке фамилий.
Я давно интересовался применением этого алгоритма и нашёл ему место для фильтрации данных на клиенте, а точнее, для поиска отеля по названию в проекте Островок.ru.
Задача
На Островке все найденные отели передаются на клиент и вся фильтрация и сортировка выдачи происходит в браузере. Необходимо было добавить фильтр по названию отеля.
Практически каждый день я пользуюсь почтой Gmail, но вот недавно заметил, что если сделать скриншот экрана (www.take-a-screenshot.org), то простым нажатием Ctrl + V этот скриншот можно скопировать прямо в текст письма Gmail. Это работает везде, но естественно кроме IE. Заинтересовавшись вопросом как это происходит нагуглил следующий пост на Stackoverflow. Под сильным впечатлением от возможностей HTML5 clipboardData решил сделать простенький портал, где без всяких Desktop приложений любой юзер может загрузить скриншот просто скопировав его.
Со вчерашнего дня, господа, можно написать вот такой скрипт:
// функция преобразования строки JavaScript (UTF-8) в UTF-16
function TEXT(text){
return new Buffer(text, 'ucs2').toString('binary');
}
var FFI = require('node-ffi');
// подключаемся к user32.dll
var user32 = new FFI.Library('user32', {
'MessageBoxW': [
'int32', [ 'int32', 'string', 'string', 'int32' ]
]
});
// диалоговое окно
var OK_or_Cancel = user32.MessageBoxW(
0, TEXT('Привет, Хабрахабр!'), TEXT('Заголовок окна'), 1
);
и, запустив его в Windows, получить желаемый результат — диалоговое окно Windows.
Это стало возможным потому, что модуль node-ffi (обёртку вокруг той необыкновенно полезной библиотеки libffi, которая используется для вызова библиотек на языке Си не менее чем в восьми других языках) вчера портировали на Windows.
Привет Хабр! Примерно год назад я представил вашему вниманию первую версию open-source библиотеки FileAPI, предназначенную для работы с файлами на клиенте и последующей загрузки на сервер.
За это время был пройден долгий путь. Библиотека заработала 670+ звезд и 90+ форков. С помощью github-сообщества удалось исправить множество «детских» проблем и внести ряд улучшений. Было закрыто более 100 тасков, и благодаря Илье Лебедеву сделана загрузка файлов по частям. Сегодня я с гордостью хочу представить вам FileAPI 2.0.
Асинхронность… Услышав это слово, у программистов начинают блестеть глаза, дыхание становится поверхностным, руки начинают трястись, голос — заикаться, мозг начинает рисовать многочисленные уровни абстракции… У менеджеров округляются глаза, звуки становятся нечленораздельными, руки сжимаются в кулаки, а голос переходит на обертона… Единственное, что их объединяет — это учащенный пульс. Только причины этого различны: программисты рвутся в бой, а менеджеры пытаются заглянуть в хрустальный шар и осознать риски, начинают судорожно придумывать причины увеличения сроков в разы… И уже потом, когда большая часть кода написана, программисты начинают осознавать и познавать всю горечь асинхронности, проводя бесконечные ночи в дебаггере, отчаянно пытаясь понять, что же все-таки происходит…
Именно такую картину рисует мое воспаленное воображение при слове “асинхронность”. Конечно, все это слишком эмоционально и не всегда правда. Ведь так?.. Возможны варианты. Некоторые скажут, что “при правильном подходе все будет работать хорошо”. Однако это можно сказать всегда и везде при всяком удобном и не удобном случае. Но лучше от этого не становится, баги не исправляются, а бессонница не проходит.
Так что же такое асинхронность? Почему она так привлекательна? А главное: что с ней не так?
Прочитав однажды вот этот пост, после покопавшись в черновиках w3c, начал потиху в этом пытаться разбираться. Сразу оговорюсь, что технология хранения данных на стороне клиента — штука не новая. А в этом варианте, так ещё и, в большей степени, вебкитная (webkit) да и под html5, так что может многих отпугнуть. Рассказывать как она работает я не буду (есть ссылки чуть выше, там всё подробно описано), а хотел бы обратить выше внимание на администрирование БД при помощи браузера Chrome…
Привет хабр! Хочу представить вам мой проект над которым я работал последние несколько месяцев. Это небольшой пост о том как в одиночку и без денег имея в запасе знание JS разработать небольшой веб проект, плагины для нескольких браузеров и мобильную версию к нему.
Предисловие
Меня всегда удручали закладки браузера или любые другие сервисы своей не информативностью. Довольно затруднительно найти нужную ссылку имея только фавиконку и заголовок. А если нужно найти конкретное видео или картинку в разросшейся коллекции закладок? Одно время я просто сохранял URL-ы в txt файл, вел скрытую группу Вконтакте, делал заметки в Evernote, пользовался кучей сервисов. Все это привело меня к созданию Raindrop.io.
Это вторая и заключительная часть статьи, посвященной процедурным методам производства контента для 3D приложений. Первую часть Вы можете найти здесь.
В этой части, так же как и в предыдущей, приводятся ссылки на скачивание созданных нами исходных материалов, которые можно свободно использовать (с изменениями или без) в своих проектах, но только не продавать/распространять в чистом виде и/или в составе каких-либо библиотек.
Напоминаем, что все эти исходные файлы не подвергались никакой специальной подготовке, обработке или оптимизации, чтобы не приукрашивать реальную ситуацию (довольно часто в процессе работы приходится жертвовать универсальностью/удобством создаваемых решений в пользу сэкономленного времени).
В этот раз речь пойдёт о том, какими средствами и приёмами мы пользовались при создании бенчмарка Valley, чтобы в максимально сжатые сроки произвести большое количество фотореалистичного контента.
CSSO (CSS Optimizer) является минимизатором CSS, выполняющим как минимизацию без изменения структуры, так и структурную минимизацию с целью получить как можно меньший текст. CSSO написан на Javascript, выполняется как в браузере, так и в командной строке (с помощью NodeJS). Распространяется под лицензией MIT.
Если вам понадобится алгоритм сортировки массива, который:
Работал бы гарантированно за O(N*log(N)) операций (обменов и сравнений);
Требовал бы O(1) дополнительной памяти;
Был бы устойчивым (то есть, не менял порядок элементов с одинаковыми ключами)
то вам, скорее всего, предложат ограничиться любыми двумя из этих трёх пунктов. И, в зависимости от вашего выбора, вы получите, например, либо сортировку слиянием (требует O(N) дополнительной памяти), либо пирамидальную сортировку (неустойчив), либо сортировку пузырьком (работает за O(N2)). Если вы ослабите требование на память до O(log(N)) («на рекурсию»), то для вас найдётся алгоритм со сложностью O(N*(log(N)2) — довольно малоизвестный, хотя именно его версия используется в реализации метода std::stable_sort().
На вопрос, можно ли добиться выполнения одновременно всех трёх условий, большинство скажет «вряд ли». Википедия о таких алгоритмах не знает. Среди программистов ходят слухи, что вроде бы, что-то такое существует. Некоторые говорят, что есть «устойчивая быстрая сортировка» — но у той реализации, которую я видел, сложность была всё те же O(N*(log(N)2) (по таймеру). И только в одном обсуждении на StackOverflow дали ссылку на статью B-C. Huang и M. A. Langston, Fast Stable Merging and Sorting in Constant Extra Space (1989-1992), в которой описан алгоритм со всеми тремя свойствами.
FaceRig — программа, позволяющая управлять эмоциями и голосом анимированного персонажа с веб-камеры, за десять дней собрала заявленные 120.000 долларов в краудфандинговой кампании на Indiegogo. Пока программа находится на раннем этапе разработки, но авторам удалось привлечь почти уже более пяти тысяч фандеров за счет довольно детальной проработки анимации и многообещающими возможностями в полной версии приложения.
Создатели программы заявляют, что их долгосрочная цель — исследование и создание доступной обычным людям системы управления и визуализации для целого персонажа (сейчас это только голова и голос), с использованием разнообразных устройств ввода и двусторонней обратной связью. По их словам, они понимают, что это довольно смелое и революционное заявление, но это — долгосрочная цель, а пока они предлагают небольшое приложение для управления эмоциями персонажа посредством веб-камеры, поскольку таким образом они хотят сделать проект доступным любому.
Всем привет! Сегодня задача у нас следующая: необходимо создать интерфейс для загрузки картинок, который бы генерировал перед загрузкой превьюшки небольшого формата. На данный момент HTML5 вовсю шествует по планете, и, казалось бы, как это реализовать должно быть предельно ясно. Есть несколько русскоязычных статей на эту тему (вот, например). Но тут есть одно но. В рассматриваемом там подходе не уделено никакого внимания расходу памяти браузером. А расход может доходить до гигантских размеров. Разумеется, если загружать одновременно не более 5-10 картинок небольшого формата, то все остается в пределах нормы; но наш интерфейс должен позволять загружать сразу много изображений формата не меньше, чем у современных фотоаппаратов-мыльниц. И вот тогда-то свободная память начинает таять на глазах.
Судя по результатам голосования, которое я проводил в своём блоге, большинство пользователей никак не типографируют тексты перед публикациями (НЛО не считается). Те, кто работают над текстами, в большинстве своём делают это вручную, поэтому я решил попробовать собрать воедино рецепты экранной типографики, дабы не забывать самому и напомнить другим. Не думаю, что статья будет чем‐то новым для опытных верстальщиков. Новички узнают, профи исправят :)
Kartograph — это новый фреймворк для создания интерактивных картографических веб приложений без использования Google Maps/Bing Maps или любого другого сервиса. Он создавался с учетом потребностей дизайнеров и журналистов.
Можно поглядеть на демки, чтобы узнать на что способен Kartograph.
Пример начинается с создания слоя с тайлами от cloudmade. Само API вроде как тоже «by cloudmade». Внимание, вопрос: а что, для родительского/дружественного проекта нельзя сделать удобный способ добавления слоя тайлов? Типа такого:
var cloudmade = new L.CloudMade.TileLayer(YOUR-API-KEY);
Не знаю, какие отношения связывают Leaflet и Cloudmade, но уж сделать удобно клиенту Cloudmade — точно не последняя задача Leaflet API. Заставлять пользователя самостоятельно добавлять копирайт Cloudmade — это какое-то насилие над здравым смыслом.
Чтобы делать приложения, которые могут работать в полностью автономном режиме, нам нужно познакомиться со следующими технологиями: HTML5 Application Cache, Web Storage и WebSQL. Мной уже были опубликованы вводные статьи, касающиеся Web Storage и HTML5 Application Cache. Рекомендую их к прочтению если вы еще не знакомы с основными понятиями. В данной статье будут пересмотрены эти технологии, в том числе и WebSQL, и описаны варианты их совместного эффективного использования. Все эти технологии поддерживаются настольной версией браузера Opera 11.10, Opera Mobile 11, браузерами на движке WebKit (в iOS и Google Android).
В прошлом топике я постарался рассказать, что такое Chrome app, и зачем их писать. В этом, как обещал, я опишу процесс создания простого Chrome-приложения. В качестве примера будет использован текстовый редактор. Во-первых, его можно написать очень коротко, так чтобы практически весь код поместился в статью. Во-вторых, в текстовом редакторе будут использоваться несколько характерных для Chrome (и других основанных на Chromium браузеров) программных интерфейсов. В-третьих, да, я уже писал текстовый редактор для Chrome.
В процессе работы над хеш-таблицей возник обычный вопрос: какую из известных хеш-функций использовать. Образцов таких функций в сети множество, есть и «любимчики», использовавшиеся ранее и показавшие неплохой результат, в основном оценивавшийся «на глаз» — длины цепочек в хеш-таблице на боевых данных «примерно равны», значит, все работает так, как нужно; отдельные выбросы… ну что ж, ну выбросы, бывает.
Рассмотрим один из вариантов создания нескольких страниц или вкладок (в том числе вложенных) на html и css без скриптов, списков и таблиц, на одной html странице. Только дивы, только хардкор. Подходит для небольших портфолио и элементов интерфейса. Не будьте буратинами используя это везде подряд. Суть:
Так получилось, что мы пишем разные высоконагруженные вещи на JS. В отличие от простых сценариев в браузере, оптимизация производительности JS на сервере (речь в основном о Node.js) – тема очень интересная практически. Думаю, присутствующим не надо объяснять, почему быстрый код лучше, чем медленный.
Вообще оптимизация – это далеко не только переписывание на Си или ассемблере «горячих» участков кода. В нашей команде дискуссия о том, как заставить скрипт работать шустрее – явление перманентное. А поскольку существуют объективные критерии оценки (бенчмарк и юнит-тесты), не допускающие патологической ситуации «о вкусах не спорят» – в результате действительно получается быстрый код, снижение нагрузки на сервер, процветание, радость.
IndexedDB – стандарт хранения больших объемов структурированных данных на клиенте – был ожидаем также как и WebSocket (ну может самую малость меньше). В свете выхода FireFox 4 я нашёл время и силы всё-таки разобраться, как им пользоваться, и попытаться написать что-то больше, чем пример с адресной книгой, гуляющий по интернетам (в процессе поиска информации у меня сложилось впечатление, что это был единственный пример).
Из года в год, сталкиваюсь с одной и той же проблемой. Как добавить, изменить или удалить параметр к некоторому адресу в строковом виде. Быстро и грязно это можно делать с помощью, например, регулярных выражений или найти каке-то готовое решение. Зачастую также может потребоваться, к примеру, подменить путь в адресе или изменить протокол с HTTP на HTTPS и т.д.
В целом, это хочется делать просто и понятно. При этом хочется разумного компромиса. Я встречал некоторые библиотеки, которые дают мощный функционал, но при этом по объему — десятки килобайт JavaScript кода. Несколько десятков килобайт, чтобы, например, подменить параметр в QueryString? Эх…
С выходом CSS3 появилось множество новшеств: с новыми свойствами стили стали сложнее, но не появилось никаких улучшений для поддержки новых и старых сложностей, в том числе дупликации кода. В чистом CSS отсутствует модульность, так как разбиение стилей на файлы и их подключение через @import пагубно влияет на производительность. Решение этих проблем нашлось в CSS препроцессорах, с их помощью стало возможным использование переменных, выполнение математических подсчетов в коде, появилась возможность повторно использовать код с помощью миксинов и наследования.
За прошедшие, с момента публикации предыдущего обзора, 3 месяца уже успели обновиться почти все рассмотренные алгоритмы минимизации (кроме, Packer`а). Кроме того в Bundle Transformer появился новый модуль-минимизатор на базе Clean-css — BundleTransformer.CleanCss.
При подготовке данного сравнительного обзора были учтены следующие пожелания читателей:
В предыдущем обзоре в качестве исходных файлов использовались: bootstrap.css и bootstrap.js из Twitter Bootstrap 2.3.2, из-за чего достоверность результатов была низкой. В новом же обзоре размер выборки был увеличен: для сравнения были отобраны 7 JS-файлов и 5 CSS-файлов из 10 популярных Open Source-проектов.
Теперь в сравнении минимизаторов CSS-кода также участвуют встроенные средства минимизации препроцессоров LESS и Sass.
Как известно, Bundle Transformer минимизирует каждый файл по отдельности и затем производит объединение минимизированного кода в один файл. Данный механизм сделан для того, чтобы предотвратить повторную минимизацию предварительно минимизированных файлов. Другие аналогичные библиотеки сначала объединяют код файлов, а затем минимизируют этот объединенный файл. Поэтому для полноты картины мы произведем 2 сравнения: сначала сравним эффективность минимизаторов на файлах, полученных путем объединения минимизированного кода, а затем на файлах, полученных путем минимизации объединенного кода файлов.
Как и в предыдущем обзоре, для минимизации файлов мы будем использовать модули Bundle Transformer, а для измерения размеров полученных файлов – расширение YSlow.
Разработчики, использующие Bundle Transformer, часто спрашивают у меня: «Какой минимизатор обладает самой высокой степенью сжатия?». В принципе, в сентябре прошлого года в своей статье «Вышел Bundle Transformer 1.6.2 или что изменилось за полгода?» я уже проводил сравнение минимизаторов по степени сжатия кода, но это сравнение было поверхностным и не было подкреплено цифрами.
В этой краткой статье мы проведем сравнение наиболее популярных алгоритмов минимизации CSS- и JS-кода на примере адаптеров-минимизаторов из Bundle Transformer. В качестве исходных файлов будут использоваться файлы bootstrap.css и bootstrap.js из Twitter Bootstrap версии 2.3.2. Измерять размеры файлов мы будем с помощью YSlow.
Здравствуй Хабр! Сегодня я хочу рассказать о генерации деревьев на HTML5 Canvas с помощью JavaScript. Сразу поясню, что речь идет не о деревьях ссылок или B-дереьях, а о тех деревья, которые мы каждый день видим у себя за окном, тех, которые делают наш воздух чище и богаче кислородом, тех, что желтеют осенью и теряют листья зимой, вообщем о тех самых живых, лесных, настоящих деревьях, только нарисованных на Canvas и пойдет речь.
Такие вот деревья получаются
Генерация деревьев нужна была мне для моей игры. Но некаких адекватных алгоритмов мне найти так и не удалось. Поэтому я написал свой генератор…
В процессе рассмотрения LUA и Python я выделил для себя, что LUA является достаточно быстрым, но с немного непривычным синтаксисом. Python же обладает очень простым синтаксисом и массой полезных библиотек, но, к сожалению, он оказался довольно медленным, и его довольно тяжело привязывать к С++. И тут на работе мне подсказали использовать AngelScript, мол, он удобный для связки, быстрее LUA и имеет С-подобный синтаксис. Как только я начал его изучать, я понял, что это тот самый скриптовый язык моей мечты.
Превью
Вот что можно прочитать про этот язык на Википедии:
AngelScript представляет собой движок, в котором приложение может регистрировать функции, свойства и типы, которые могут использоваться в скриптах. Скрипты компилируются в модули. Количество используемых модулей варьрируется в зависимости от нужд. Приложение может также использовать различные интерфейсы для каждого модуля с помощью групп конфигурации. Это особенно полезно, когда приложение работает с несколькими типами скриптов, например, GUI, AI и т.д.
Программа «Hello, world» в простейшем случае выглядит так:
Увидев на просторах сети пару впечатляющих примеров 3D-трансформаций средствами CSS — заинтересовался, решил разобраться в теме, прочитал несколько статей, вроде бы что-то понял. Но, как известно, теория без практики – как зомби — мертва, хоть и может съесть мозг.
Для усвоения материала необходимо самому сделать что-нибудь любопытное с использованием прочитанного. Какой трехмерный объект сделать легче всего? Пожалуй, кубик. А чтобы результат получился интереснее и красивее, пусть это будет игральный кубик с точками на гранях. Поехали.
Для нетерпеливых и тех, кто смотрит Хабр ради забавных картинок – конечный результат. Работает в Chrome, последних версиях Firefox, Safari. Opera 12.01 — пока никак, ну а про IE вы и сами все знаете.
С октября 2009 года я занимаюсь разработкой приложения для поиска и прослушивания музыки. Я стремлюсь организовать возможность быстрого взаимодействия пользователя с интерфейсом, и в качестве одного из средств ускорения взаимодействия использую различные способы для быстрой отрисовки страниц.
Предлагаю ознакомиться со способами, реализованными мной в приложении на системном уровне:
Использование CSS и переключение классов вместо перестроения DOM дерева
Повсемнестное кеширование выборок элементов ($('div.active_part span.highlighter')), атомарные операции по изменению (вместо всеобщей перерисовки, вместо переделывания больших участков DOM дерева)
Минимизации чтений DOM во время записи изменений состояний
Кеширование размеров и расположения элементов (это спасает от излишнего вычисления при считывании этих значений при наличии других изменений: чтение во время изменения множества частей дерева крайне негативно сказывается на производительности)
Аккуратное, не затягивающееся накопление изменений, необходимых произвести в DOM
Прикрепление частей изменяющихся коллекций единовременно (когда, например, в середину списка вставляется 3 новых элемента; createDocumentFragment) в конкретное место (after, before) вместо открепления всей коллекции от DOM и повторного прикрепления (и вместо того, чтобы перерисовывать весь список)
Прогрессивный асинхронный рендеринг: картина прорисовывается сразу с небольшим количеством деталей, затем деталей появляется всё больше
Клонирование нодов (как часть шаблонизации)
Кеширование и использование кеша результатов парсинга DOM шаблонов
изображения из части с заголовком «Прикрепление частей изменяющихся коллекций единовременно...»
Дэниел Клиффорд сделал на Google I/O прекрасный доклад, посвященный особенностям оптимизации кода JavaSсript для движка V8. Дэниел призвал нас стремиться к большей скорости, тщательно анализировать отличия между С++ и JavaScript, и писать код, помня о том, как работает интерпретатор. Я собрал в этой статье резюме самых главных моментов выступления Дэниела, и буду обновлять её по мере того, как движок будет меняться.
Кто из нас в детстве не мечтал «бороздить просторы вселенной», как капитан Пикард, прогуливаться по неизведанным планетам далёких миров, встречать рассветы двойных или тройных звёзд, погружаться в атмосферы газовых гигантов, ронять корабли в чёрные дыры? И я тоже не исключение. Конечно, частично эту мечту воплощали книги, фильмы и «Элит»-ные игры. Но вся романтика в них разрушалась банальными купи-продай и «пиу-пиу» в «жидком» космосе на скоростях самолётов времён первой мировой войны. Да и тем немногим виртуальным миркам не хватало свободы, детальности и масштабов реальной вселенной.
В начале тысячелетия я познакомился с MojoWorld и был шокирован его возможностями. Наконец-то, можно было бродить по другим планетам и фотографировать местные достопримечательности. Он стал первой ласточкой, дававшей надежду на то, что полномасштабные космические миры технически возможны. Но, к сожалению, производительности железа десятилетней давности было не достаточно для передачи всех красот в реальном времени. Да и планеты оставались всего лишь мёртвыми пейзажами.
Но вот, чуть больше года назад, я совершенно случайно наткнулся на вселенную Space Engine, и она просто взорвала мне мозг и размазала его по полу своим масштабом и невероятной детализацией.
В 2011 году была переведена хорошая статья „Лучшие шрифты для программирования“. Теперь представляется список самых удачных шрифтов для кода на момент июня 2014 года. Хотя я и уверен, что многих устраивает Courier New, используемый по умолчанию в Windows во многих редакторах. Но, как человек любящий типографику, настаиваю обратить внимание на одну из гарнитур из этой статьи. Хороший шрифт — это прекрасно!
На Хабре публиковалось немало статей о создании расширений для Chrome, но тема разработки Chrome приложений (они же Chrome apps) затрагивалась заметно реже. В последнее время она стала актуальнее из-за распространения устройств на ChromeOS. К тому же инфраструктура для создания приложений для Chrome стала более стабильной и удобной для использования. В этой статье я постараюсь ответить на основные вопросы: зачем вообще писать приложения для Chrome, чем они отличаются от расширений, веб-сервисов, десктопных приложений и т.п., а также как они разрабатываются, и какие на них накладываются ограничения. Если эта тема вызовет интерес, у статьи будут продолжения, затрагивающие более специальные вопросы.
Привет, Хабр! Мой предыдущий пост, посвященный программированию графики, был благодушно воспринят сообществом, и я отважился ещё на один. Сегодня я расскажу об алгоритме рендеринга теней Parallel-Split Shadow Mapping (PSSM), с которым я впервые столкнулся, когда возникла рабочая необходимость отображать тени на большом расстоянии от игрока. Тогда я был ограничен набором возможностей Direct3D 10, сейчас я реализовал алгоритм на Direct3D 11 и OpenGL 4.3. Подробнее алгоритм PSSM описывается в GPU Gems 3 как с математической точки зрения, так и с точки зрения реализации на Direct3D 9 и 10. За подробностями прошу под кат.
Mozilla анонсировала новый проект mozjpeg по созданию качественного кодера JPEG, который улучшит сжатие изображений при сохранении совместимости с существующими декодерами.
На каждом сайте постоянно увеличивается и количество файлов JPEG, и их размер. Поскольку HTML, JS, и CSS относительно невелики, то при загрузке веб-страницы основной трафик зачастую приходится именно на JPEG. Так что уменьшение размера фотографий — вполне очевидная цель для оптимизации, считает Mozilla.
Существующие кодеры JPEG зачастую работают не очень эффективно. Логично перейти на более современные алгоритмы (например, JPEG2000 с вейвлет-преобразованием или свободный WebP), и такая тема неоднократно обсуждалась. Но разработчики Mozilla говорят, что популярность JPEG слишком велика. Созданный в 1992 году этот стандарт сжатия с потерями стал общепризнанным. Переход на новый формат займёт много лет, поскольку он не совместим с имеющимся программным обеспечением. «Мы (в Mozilla) не сомневаемся, что алгоритмические улучшения когда-нибудь подтолкнут к такому переходу, возможно, скоро. Но даже в этом случае JPEG ещё долго будет с нами».
В далекие времена, для IT-индустрии это 70-е годы прошлого века, ученые-математики (так раньше назывались программисты) сражались как Дон-Кихоты в неравном бою с компьютерами, которые тогда были размером с маленькие ветряные мельницы. Задачи ставились серьезные: поиск вражеских подлодок в океане по снимкам с орбиты, расчет баллистики ракет дальнего действия, и прочее. Для их решения компьютер должен оперировать действительными числами, которых, как известно, континуум, тогда как память конечна. Поэтому приходится отображать этот континуум на конечное множество нулей и единиц. В поисках компромисса между скоростью, размером и точностью представления ученые предложили числа с плавающей запятой (или плавающей точкой, если по-буржуйски).
Арифметика с плавающей запятой почему-то считается экзотической областью компьютерных наук, учитывая, что соответствующие типы данных присутствуют в каждом языке программирования. Я сам, если честно, никогда не придавал особого значения компьютерной арифметике, пока решая одну и ту же задачу на CPU и GPU получил разный результат. Оказалось, что в потайных углах этой области скрываются очень любопытные и странные явления: некоммутативность и неассоциативность арифметических операций, ноль со знаком, разность неравных чисел дает ноль, и прочее. Корни этого айсберга уходят глубоко в математику, а я под катом постараюсь обрисовать лишь то, что лежит на поверхности.
 Чего только не сделают люди в порыве гнева. Кто-то готов сломать телефон или выкинуть ноутбук в окно. Способы мести тоже выбирают изысканно. Один из самых популярных — выложить в социальные сети компрометирующие фотографии и видеоролики с участием бывшей девушки. Мол, так она будет опозорена, ведь фотографии увидят знакомые и родственники. Это очень распространённое явление получило название «порноместь» (revenge porn). В современном обществе сцены убийства ни у кого не вызывают удивления, но показывать секс между влюблёнными людьми — это своеобразное табу.
Чего только не сделают люди в порыве гнева. Кто-то готов сломать телефон или выкинуть ноутбук в окно. Способы мести тоже выбирают изысканно. Один из самых популярных — выложить в социальные сети компрометирующие фотографии и видеоролики с участием бывшей девушки. Мол, так она будет опозорена, ведь фотографии увидят знакомые и родственники. Это очень распространённое явление получило название «порноместь» (revenge porn). В современном обществе сцены убийства ни у кого не вызывают удивления, но показывать секс между влюблёнными людьми — это своеобразное табу.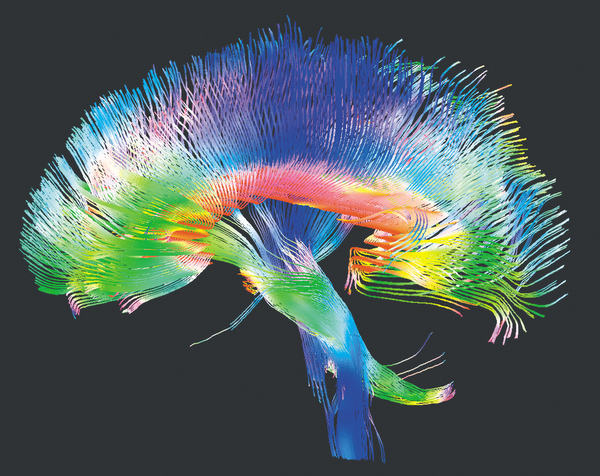



 В
В 

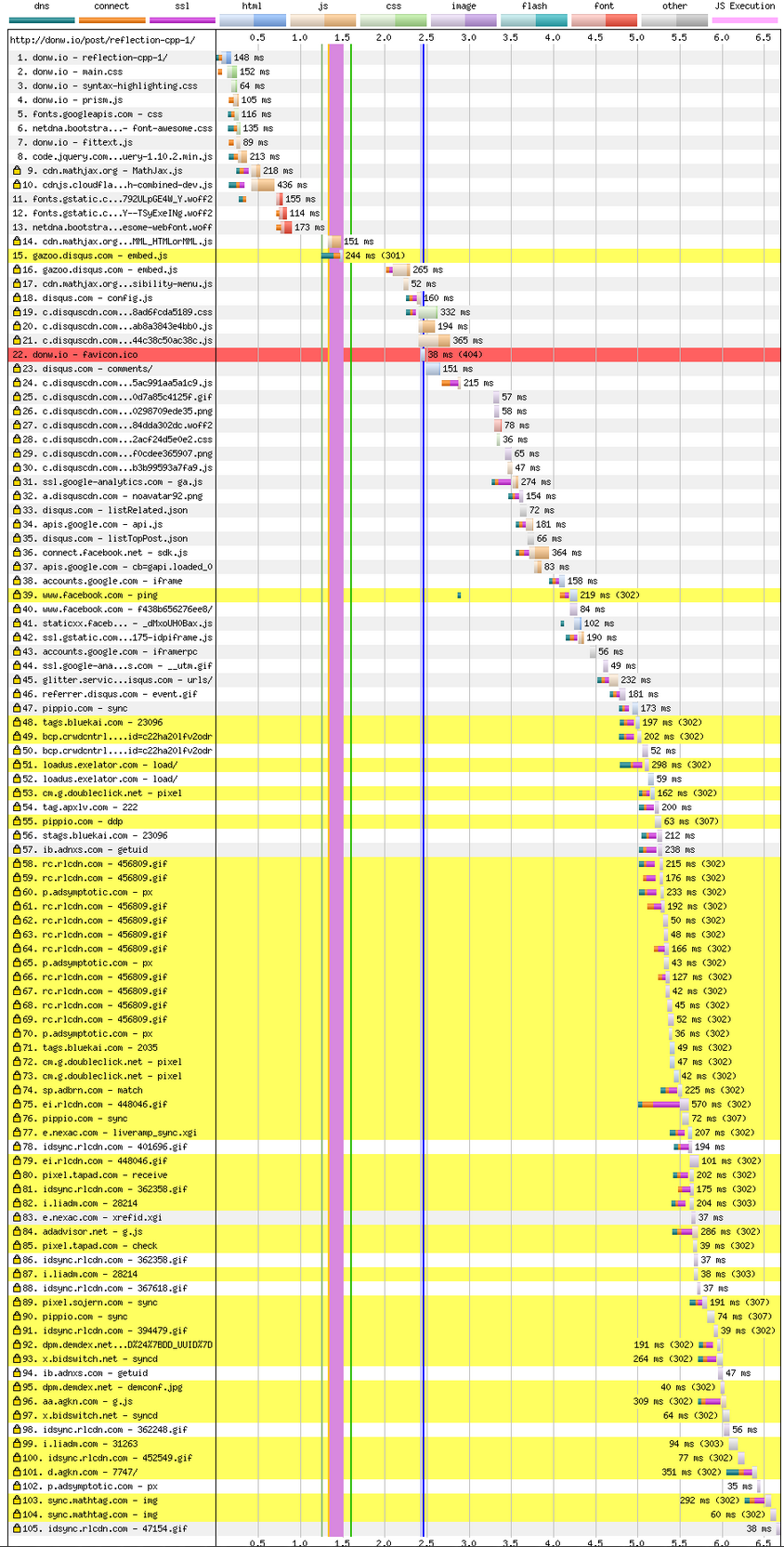
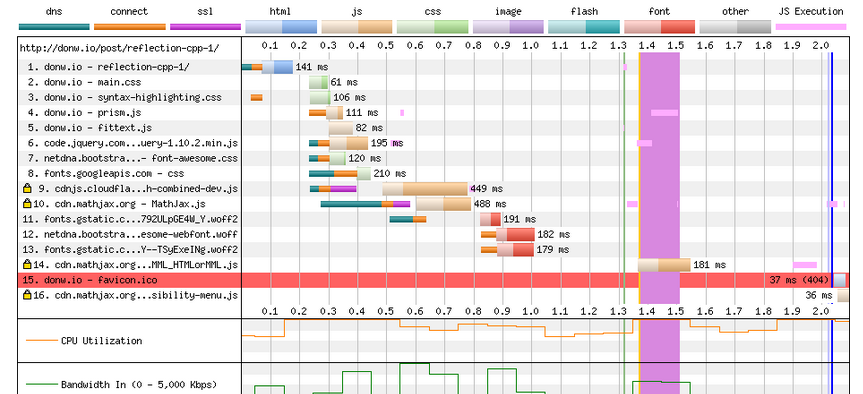






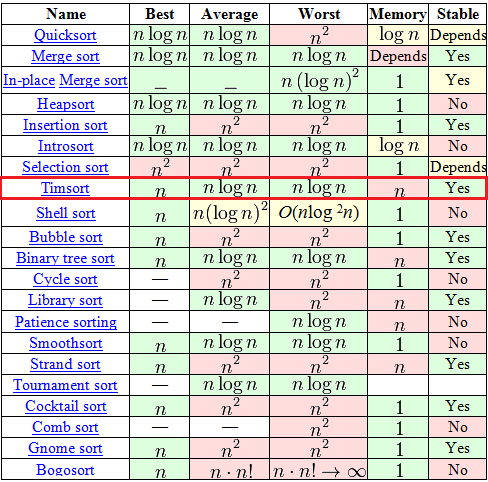
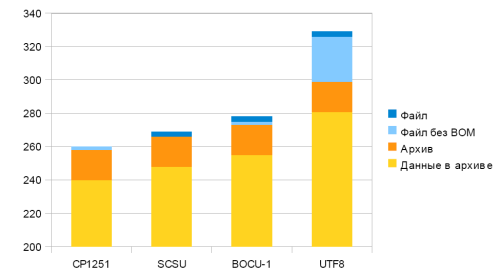



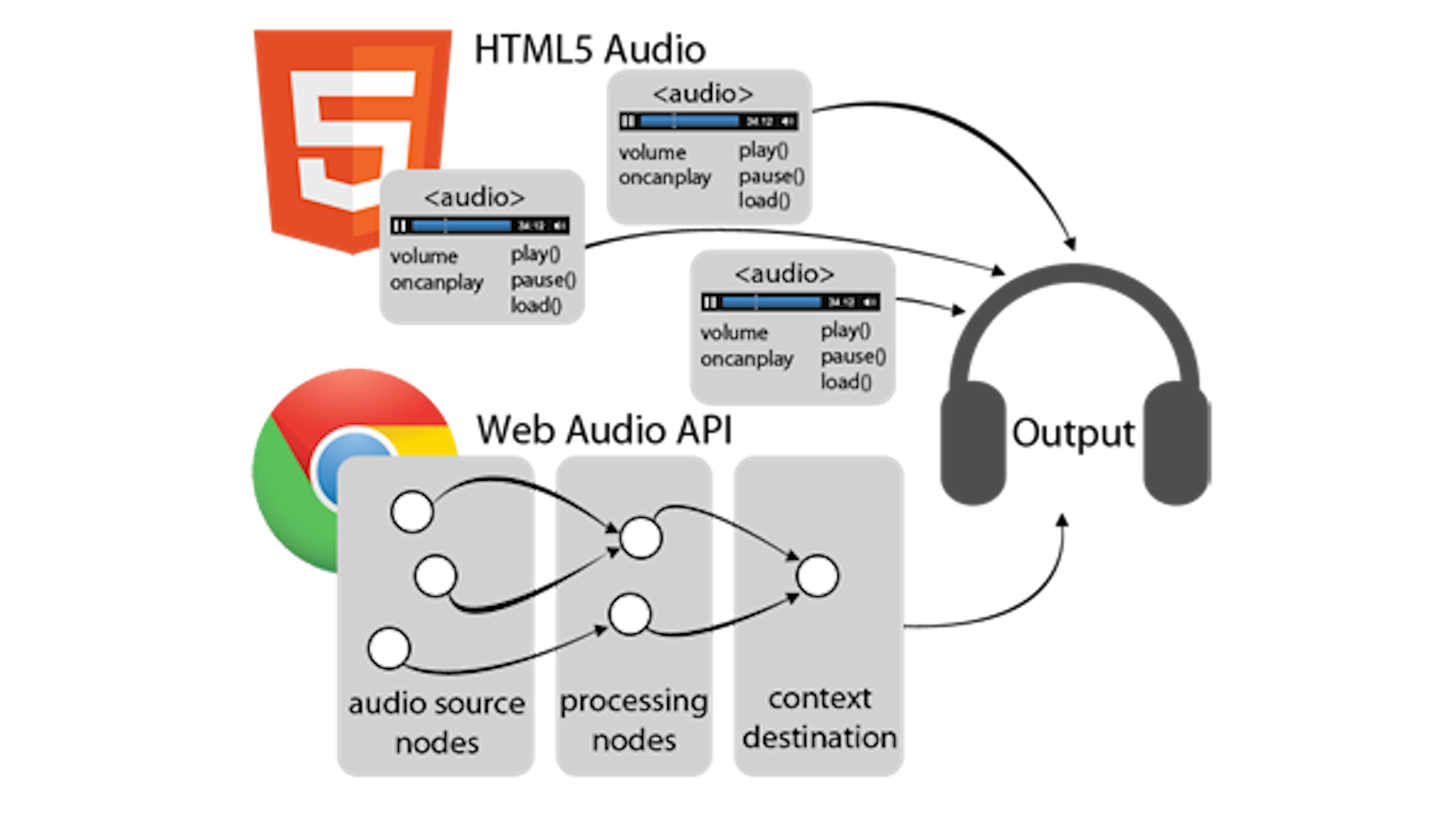





![[узлы к узлам]](https://habrastorage.org/getpro/habr/post_images/590/ffa/1d9/590ffa1d92f892c50c2c05afc343009c.png)


 Должны мы,
Должны мы,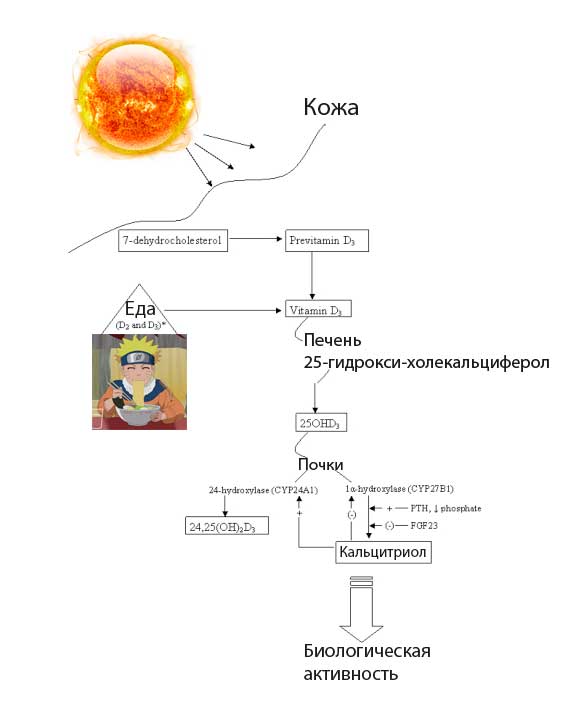


 Говорят, обещанного три года ждут. Вот и я в комментарии к
Говорят, обещанного три года ждут. Вот и я в комментарии к 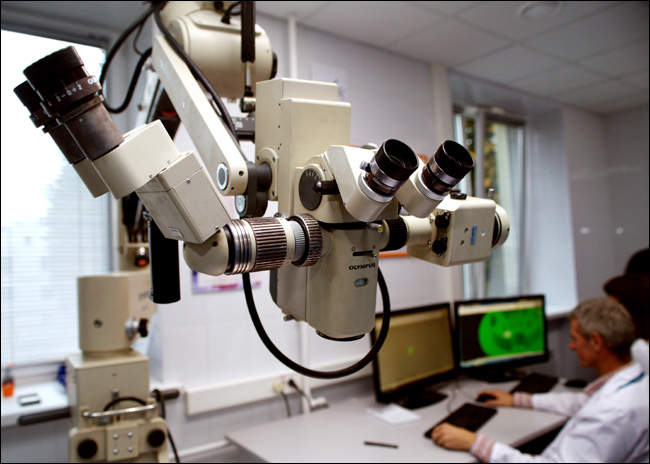









 (с) xkcd
(с) xkcd




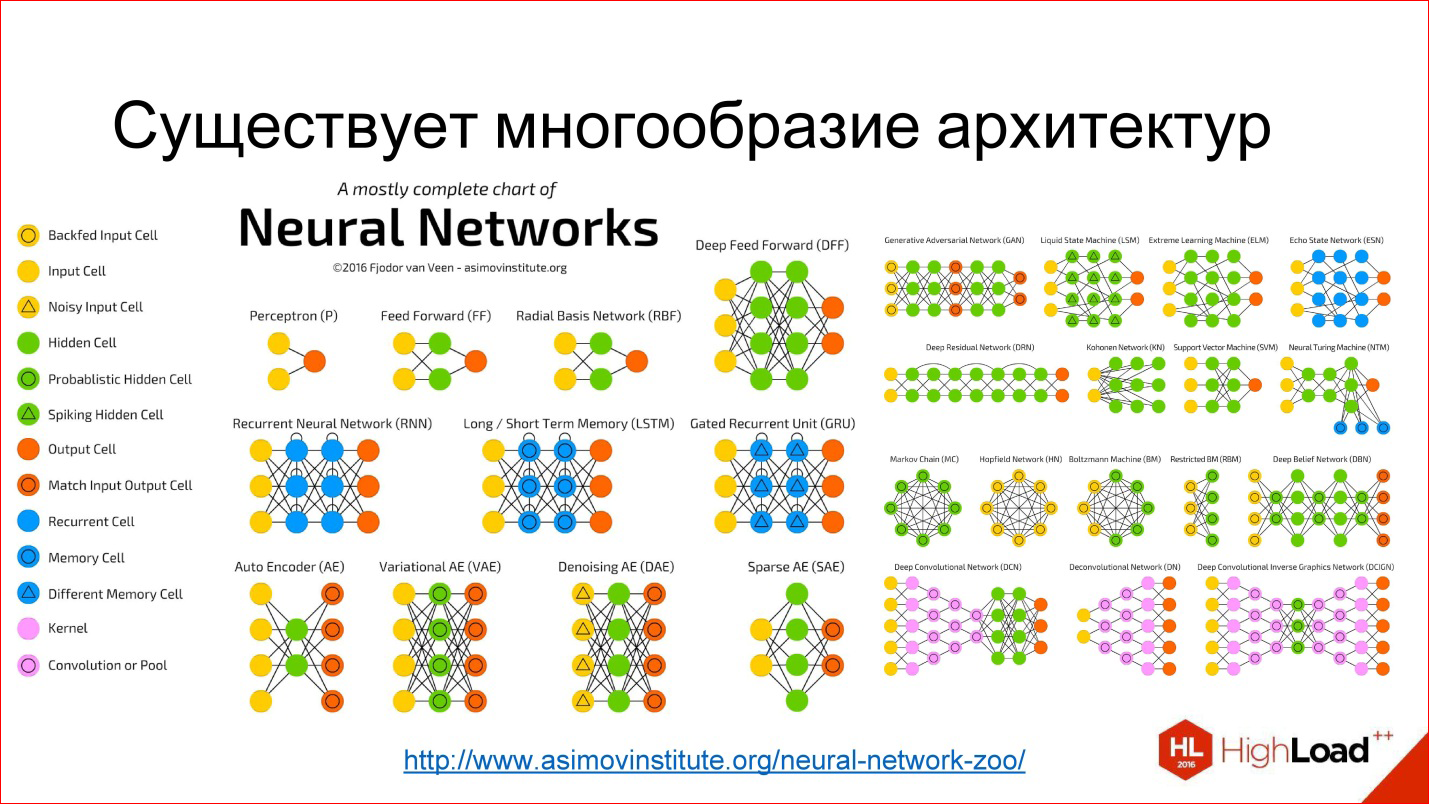




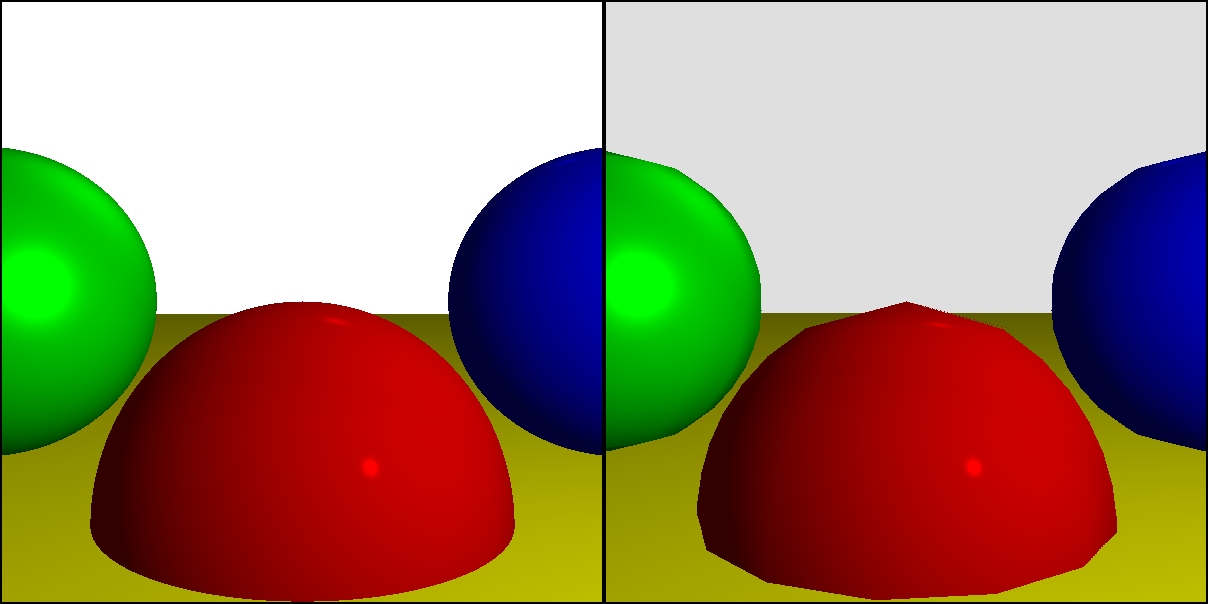



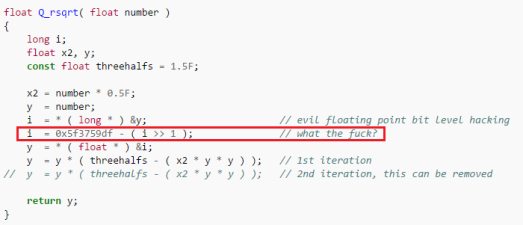




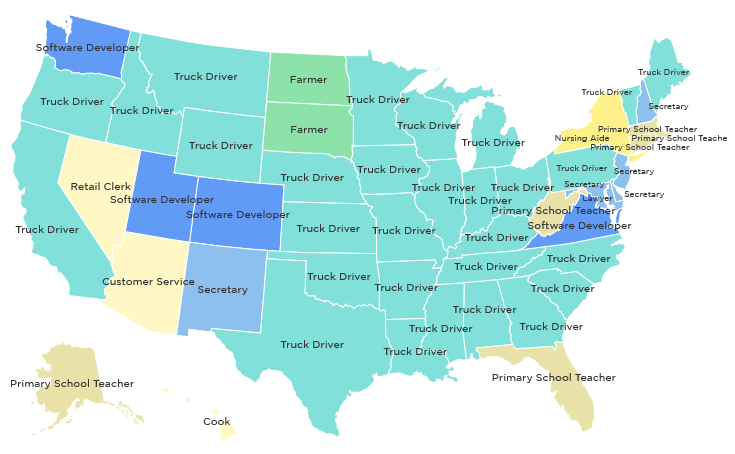
 В настоящей заметке я расскажу о том, как можно построить систему оптического распознавания структурной информации, опираясь на алгоритмы, применяющиеся в обработке изображений и их реализации в рамках библиотеки OpenCV. За описанием системы стоит активно развивающийся open source проект
В настоящей заметке я расскажу о том, как можно построить систему оптического распознавания структурной информации, опираясь на алгоритмы, применяющиеся в обработке изображений и их реализации в рамках библиотеки OpenCV. За описанием системы стоит активно развивающийся open source проект 
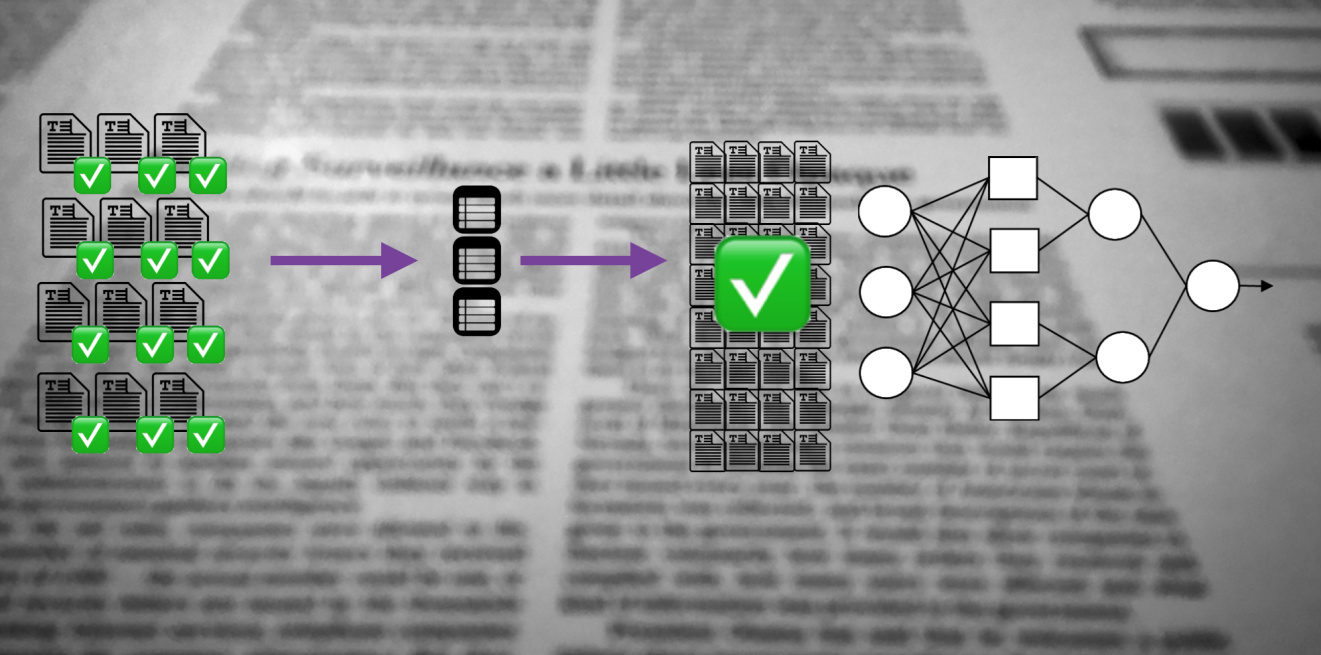

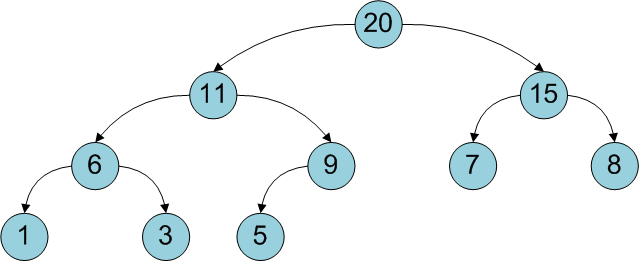









 Поэзия — та же добыча радия.
Поэзия — та же добыча радия.











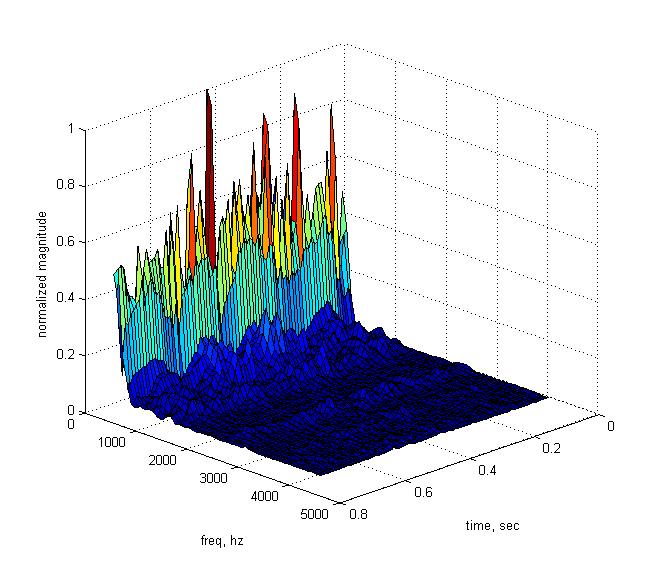












 Хей, привет. 2017 год на дворе. Даже простенькие мобильные и браузерные приложения начинают потихоньку рисовать физически корректное освещение. Интернет пестрит кучей статей и готовых шейдеров. И кажется, что это должно быть так просто тоже обмазаться PBR… Или нет?
Хей, привет. 2017 год на дворе. Даже простенькие мобильные и браузерные приложения начинают потихоньку рисовать физически корректное освещение. Интернет пестрит кучей статей и готовых шейдеров. И кажется, что это должно быть так просто тоже обмазаться PBR… Или нет?












 Реализацию порядко-независимой прозрачности (
Реализацию порядко-независимой прозрачности (


 Давненько я не писал на хабр: учеба, сессия надвигается, сами понимаете. Сегодня я попробую рассказать, как в XNA реализовать Deferred Lighting (отложенное освещение) с использованием normal mapping на три источника света, при этом использовать мы будем Reach-профиль и Shader model 2.0.
Давненько я не писал на хабр: учеба, сессия надвигается, сами понимаете. Сегодня я попробую рассказать, как в XNA реализовать Deferred Lighting (отложенное освещение) с использованием normal mapping на три источника света, при этом использовать мы будем Reach-профиль и Shader model 2.0.




 Конечно, многие скажут, что это ни-ни и писать для веба нужно только на PHP, ну или на один из модерных языках Питон, Руби, Node.js и т.д.
Конечно, многие скажут, что это ни-ни и писать для веба нужно только на PHP, ну или на один из модерных языках Питон, Руби, Node.js и т.д.





![[факсимиле страницы из ежедневника Потапюка]](https://habrastorage.org/storage/68322bbd/157792dc/76452fce/ef85eac8.jpg)


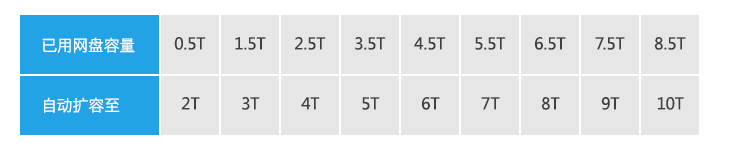


 Хабр, привет.
Хабр, привет.









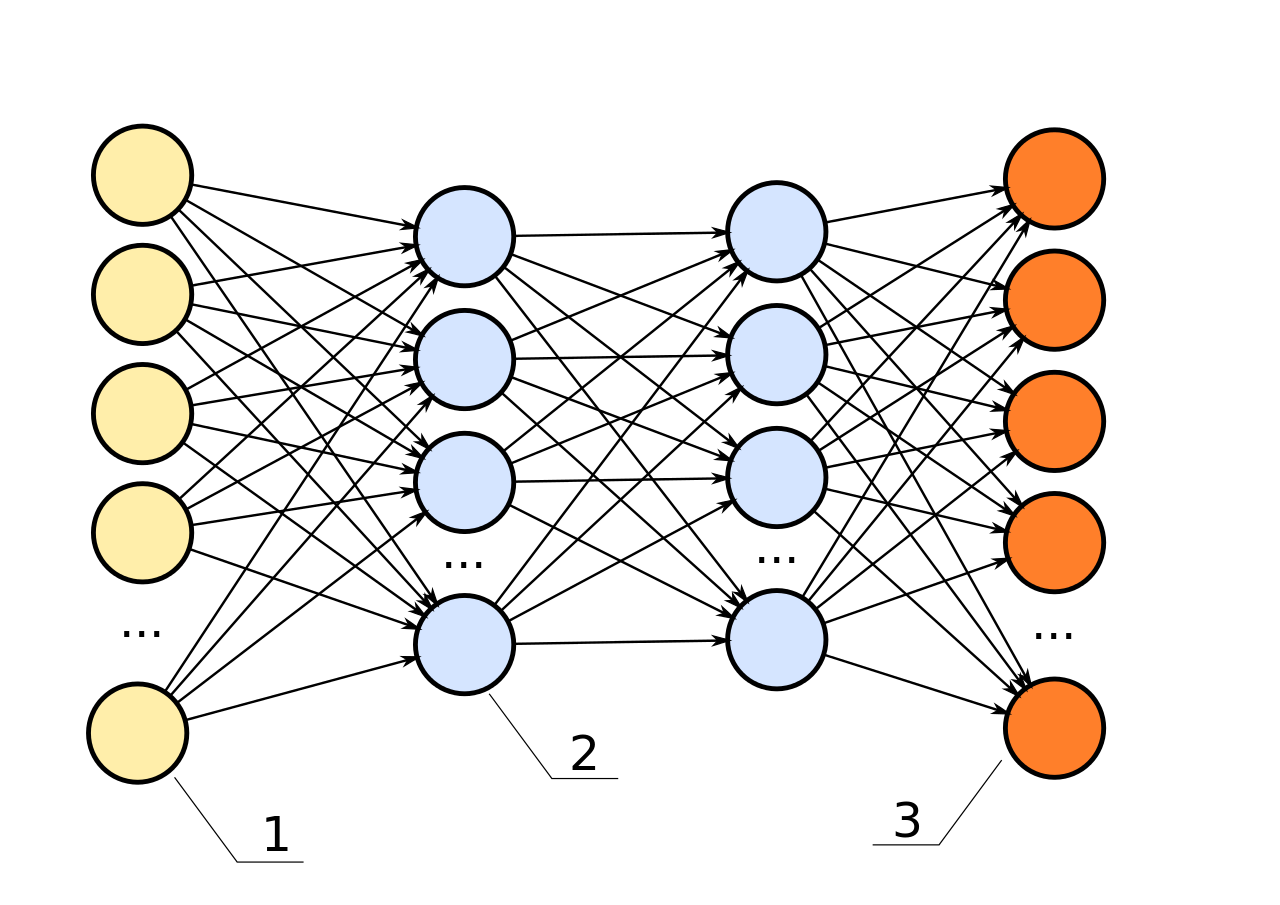











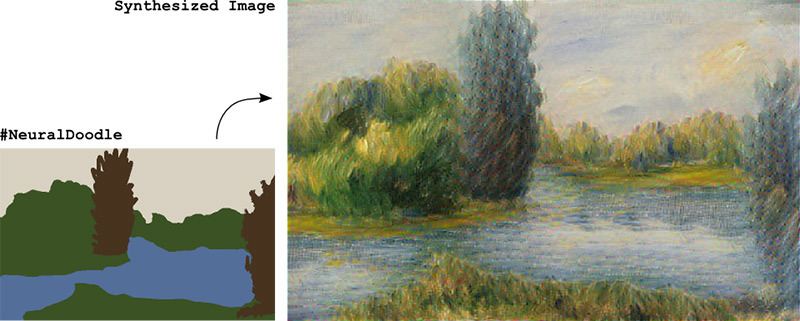
 В свое время на Хабре был опубликован цикл статей «Логика мышления». С тех пор прошло два года. За это время удалось сильно продвинуться вперед в понимании того, как работает мозг и получить интересные результаты моделирования. В новом цикле «Логика сознания» я опишу текущее состоянии наших исследований, ну а попутно попытаюсь рассказать о теориях и моделях интересных для тех, кто хочет разобраться в биологии естественного мозга и понять принципы построения искусственного интеллекта.
В свое время на Хабре был опубликован цикл статей «Логика мышления». С тех пор прошло два года. За это время удалось сильно продвинуться вперед в понимании того, как работает мозг и получить интересные результаты моделирования. В новом цикле «Логика сознания» я опишу текущее состоянии наших исследований, ну а попутно попытаюсь рассказать о теориях и моделях интересных для тех, кто хочет разобраться в биологии естественного мозга и понять принципы построения искусственного интеллекта.
























 Поскольку побеждать
Поскольку побеждать 





 Привет, Хабр, давно не виделись. В этом посте мне хотелось бы рассказать о таком относительно новом понятии в машинном обучении, как
Привет, Хабр, давно не виделись. В этом посте мне хотелось бы рассказать о таком относительно новом понятии в машинном обучении, как 







 Ян Вермеер, «Урок музыки» (1662-1665)
Ян Вермеер, «Урок музыки» (1662-1665)





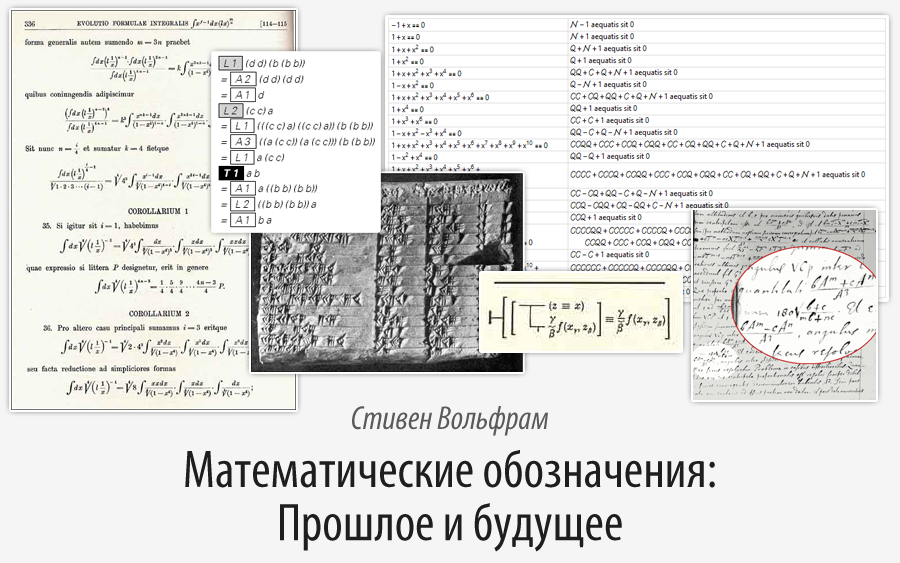
 По умолчанию npm публикует в registry весь модуль целиком. За исключением явно указанных в .gitignore файлов. Это отбрасывает зависимости, но все равно позволяет куче не очень нужных файлов просочиться в опубликованное. После чего
По умолчанию npm публикует в registry весь модуль целиком. За исключением явно указанных в .gitignore файлов. Это отбрасывает зависимости, но все равно позволяет куче не очень нужных файлов просочиться в опубликованное. После чего 

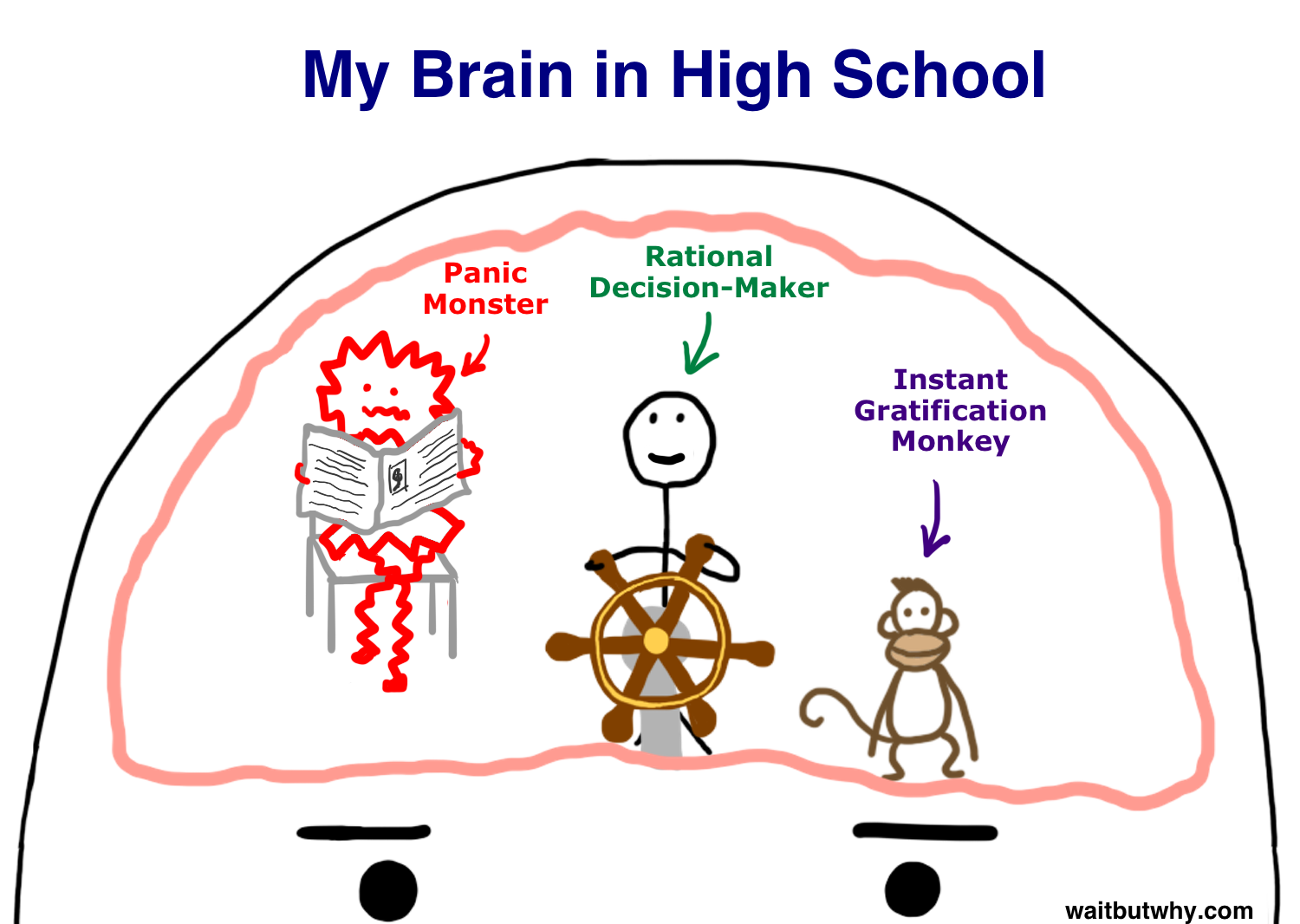




 Генетически модифицированные организмы (ГМО) — организмы, чей генотип искусственно изменён при помощи методов генной инженерии. Изменения внесены целенаправленно, например, в случае сельскохозяйственных культур — повышение урожайности, улучшение вкуса и питательных ценностей продуктов, устойчивости к вредителям и т.д.
Генетически модифицированные организмы (ГМО) — организмы, чей генотип искусственно изменён при помощи методов генной инженерии. Изменения внесены целенаправленно, например, в случае сельскохозяйственных культур — повышение урожайности, улучшение вкуса и питательных ценностей продуктов, устойчивости к вредителям и т.д.



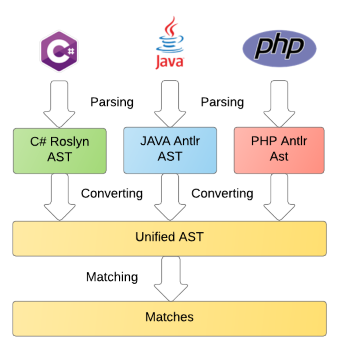



 «It is certainly a killer feature, if you know what I mean.»
«It is certainly a killer feature, if you know what I mean.»










 CSS — не очень сложный язык. Но даже если вы пишете таблицы стилей в течении многих лет, наверняка бывают моменты, когда вы узнаете еще что-нибудь новенькое: свойства или значения, которые вам не доводилось использовать, детали спецификации, о которых вы не имели понятия.
CSS — не очень сложный язык. Но даже если вы пишете таблицы стилей в течении многих лет, наверняка бывают моменты, когда вы узнаете еще что-нибудь новенькое: свойства или значения, которые вам не доводилось использовать, детали спецификации, о которых вы не имели понятия.




 Германия отличается даже от европейских соседей — в этой стране наиболее ревностно следят за соблюдением законов о защите приватных данных. Любые попытки внедрить отслеживающую технологию здесь могут наткнуться на судебный запрет. Немецкие домовладельцы заставляют Google
Германия отличается даже от европейских соседей — в этой стране наиболее ревностно следят за соблюдением законов о защите приватных данных. Любые попытки внедрить отслеживающую технологию здесь могут наткнуться на судебный запрет. Немецкие домовладельцы заставляют Google 
 Несколько лет назад художница
Несколько лет назад художница 





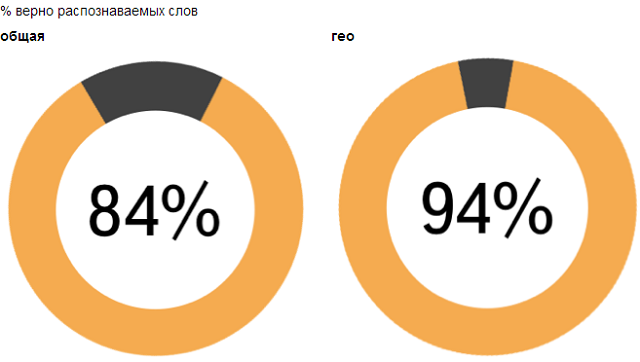



 Наверное каждый продукт, интерфейс которого имеет более одного языка, сталкивался с проблемой организации процесса локализации.
Наверное каждый продукт, интерфейс которого имеет более одного языка, сталкивался с проблемой организации процесса локализации.
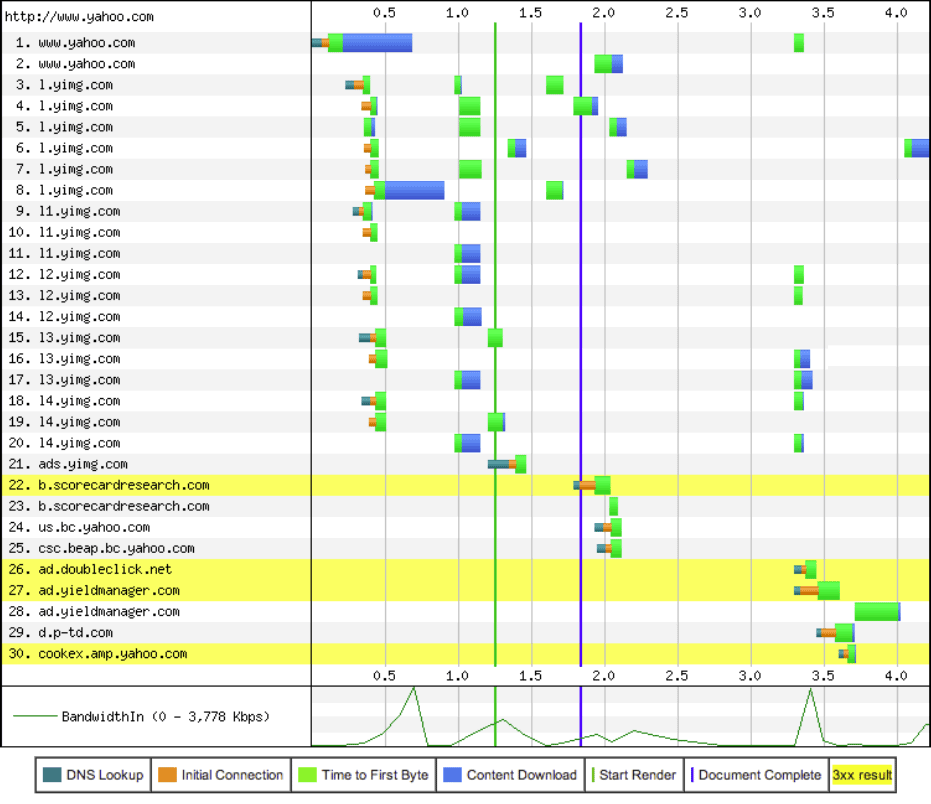





 Наука всегда привлекала к себе мошенников и аферистов. В прошлые века в патентные ведомства поступали сотни заявок на патенты с вечными двигателями, пока такое «изобретение» не запретили в принципе. Теперь распространяются псевдонаучные журналы, которые принимают к публикации что угодно, любые статьи, даже
Наука всегда привлекала к себе мошенников и аферистов. В прошлые века в патентные ведомства поступали сотни заявок на патенты с вечными двигателями, пока такое «изобретение» не запретили в принципе. Теперь распространяются псевдонаучные журналы, которые принимают к публикации что угодно, любые статьи, даже 




 «по глазам» (кто играл в Fallout 2 тот поймет).
«по глазам» (кто играл в Fallout 2 тот поймет).









 Для Visual Studio 2010 создано уже около 900
Для Visual Studio 2010 создано уже около 900 










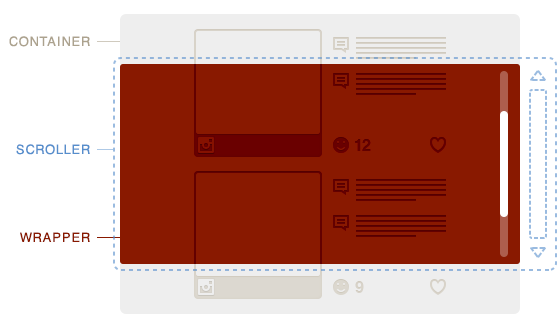









 От переводчика:
От переводчика: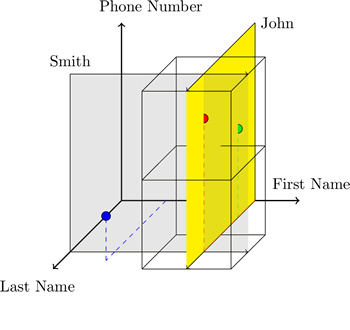




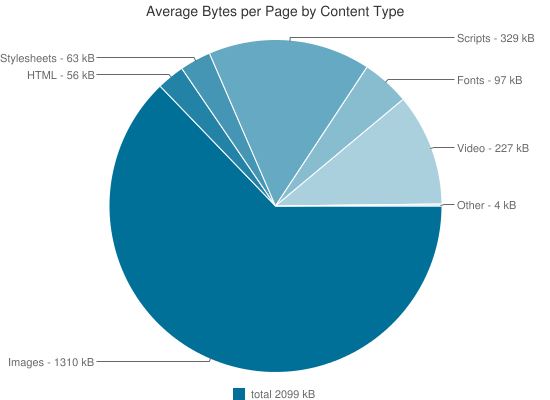





 Tree — двумерный бинарно-безопасный формат представления структурированных данных. Легко читаемый как человеком так и компьютером. Простой, компактный, быстрый, выразительный и расширяемый. Сравнивая его с другими популярными форматами, можно составить следующую сравнительную таблицу:
Tree — двумерный бинарно-безопасный формат представления структурированных данных. Легко читаемый как человеком так и компьютером. Простой, компактный, быстрый, выразительный и расширяемый. Сравнивая его с другими популярными форматами, можно составить следующую сравнительную таблицу:




 В последние дни
В последние дни 







 Я не люблю CSS. Он простой и понятный. Это движущая сила Интернета, но он слишком ограниченный и им трудно управлять. Пришло время привести этот язык в порядок и сделать его более полезным, используя динамический CSS при помощи LESS.
Я не люблю CSS. Он простой и понятный. Это движущая сила Интернета, но он слишком ограниченный и им трудно управлять. Пришло время привести этот язык в порядок и сделать его более полезным, используя динамический CSS при помощи LESS.
 Некоторое время назад мы
Некоторое время назад мы 
 Суффиксное дерево – мощная структура, позволяющая неожиданно эффективно решать мириады сложных поисковых задач на неструктурированных массивах данных. К сожалению, известные алгоритмы построения суффиксного дерева (главным образом алгоритм, предложенный Эско Укконеном (Esko Ukkonen)) достаточно сложны для понимания и трудоёмки в реализации. Лишь относительно недавно, в 2011 году, стараниями Дэни Бреслауэра (Dany Breslauer) и Джузеппе Италиано (Giuseppe Italiano) был придуман сравнительно несложный метод построения, который фактически является упрощённым вариантом алгоритма Питера Вейнера (Peter Weiner) – человека, придумавшего суффиксные деревья в 1973 году. Если вы не знаете, что такое суффиксное дерево или всегда его боялись, то это ваш шанс изучить его и заодно овладеть относительно простым способом построения.
Суффиксное дерево – мощная структура, позволяющая неожиданно эффективно решать мириады сложных поисковых задач на неструктурированных массивах данных. К сожалению, известные алгоритмы построения суффиксного дерева (главным образом алгоритм, предложенный Эско Укконеном (Esko Ukkonen)) достаточно сложны для понимания и трудоёмки в реализации. Лишь относительно недавно, в 2011 году, стараниями Дэни Бреслауэра (Dany Breslauer) и Джузеппе Италиано (Giuseppe Italiano) был придуман сравнительно несложный метод построения, который фактически является упрощённым вариантом алгоритма Питера Вейнера (Peter Weiner) – человека, придумавшего суффиксные деревья в 1973 году. Если вы не знаете, что такое суффиксное дерево или всегда его боялись, то это ваш шанс изучить его и заодно овладеть относительно простым способом построения. — это наименьшее выпуклое множество
— это наименьшее выпуклое множество 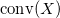 , содержащее в себе множество
, содержащее в себе множество 
 В современном мире многие сталкиваются с необходимостью изучить иностранный язык. Чаще всего этим языком является английский. Методов изучения иностранного языка, и английского в том числе, существует много: заучивание слов по карточкам; расклеивание стикеров с названиями предметов по всему дому; метод 25-го кадра (хотя лично я в него не верю); штудирование грамматики,– как с репетитором/в школе/в университете/на курсах, так и самостоятельно; метод погружения, наконец. В общем, есть из чего выбрать. Благо, на просторах Интернета материалов можно найти великое множество.
В современном мире многие сталкиваются с необходимостью изучить иностранный язык. Чаще всего этим языком является английский. Методов изучения иностранного языка, и английского в том числе, существует много: заучивание слов по карточкам; расклеивание стикеров с названиями предметов по всему дому; метод 25-го кадра (хотя лично я в него не верю); штудирование грамматики,– как с репетитором/в школе/в университете/на курсах, так и самостоятельно; метод погружения, наконец. В общем, есть из чего выбрать. Благо, на просторах Интернета материалов можно найти великое множество.





 CMake — кроcсплатформенная утилита для автоматической сборки программы из исходного кода. При этом сама CMake непосредственно сборкой не занимается, а представляет из себя front-end. В качестве back-end`a могут выступать различные версии make и Ninja. Так же CMake позволяет создавать проекты для CodeBlocks, Eclipse, KDevelop3, MS VC++ и Xcode. Стоит отметить, что большинство проектов создаются не нативных, а всё с теми же back-end`ами.
CMake — кроcсплатформенная утилита для автоматической сборки программы из исходного кода. При этом сама CMake непосредственно сборкой не занимается, а представляет из себя front-end. В качестве back-end`a могут выступать различные версии make и Ninja. Так же CMake позволяет создавать проекты для CodeBlocks, Eclipse, KDevelop3, MS VC++ и Xcode. Стоит отметить, что большинство проектов создаются не нативных, а всё с теми же back-end`ами.
 Пару лет назад я прочитал интересные факты о жизненном цикле
Пару лет назад я прочитал интересные факты о жизненном цикле 








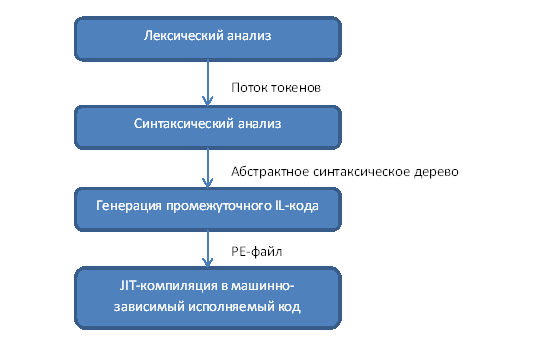




 От переводчика: Это восьмая статья из
От переводчика: Это восьмая статья из 

 В Мексике бушует насилие из-за активной борьбы правительства с наркокартелями. Последние придумали весьма радикальное решение для получения преимущества в борьбе на улицах.
В Мексике бушует насилие из-за активной борьбы правительства с наркокартелями. Последние придумали весьма радикальное решение для получения преимущества в борьбе на улицах.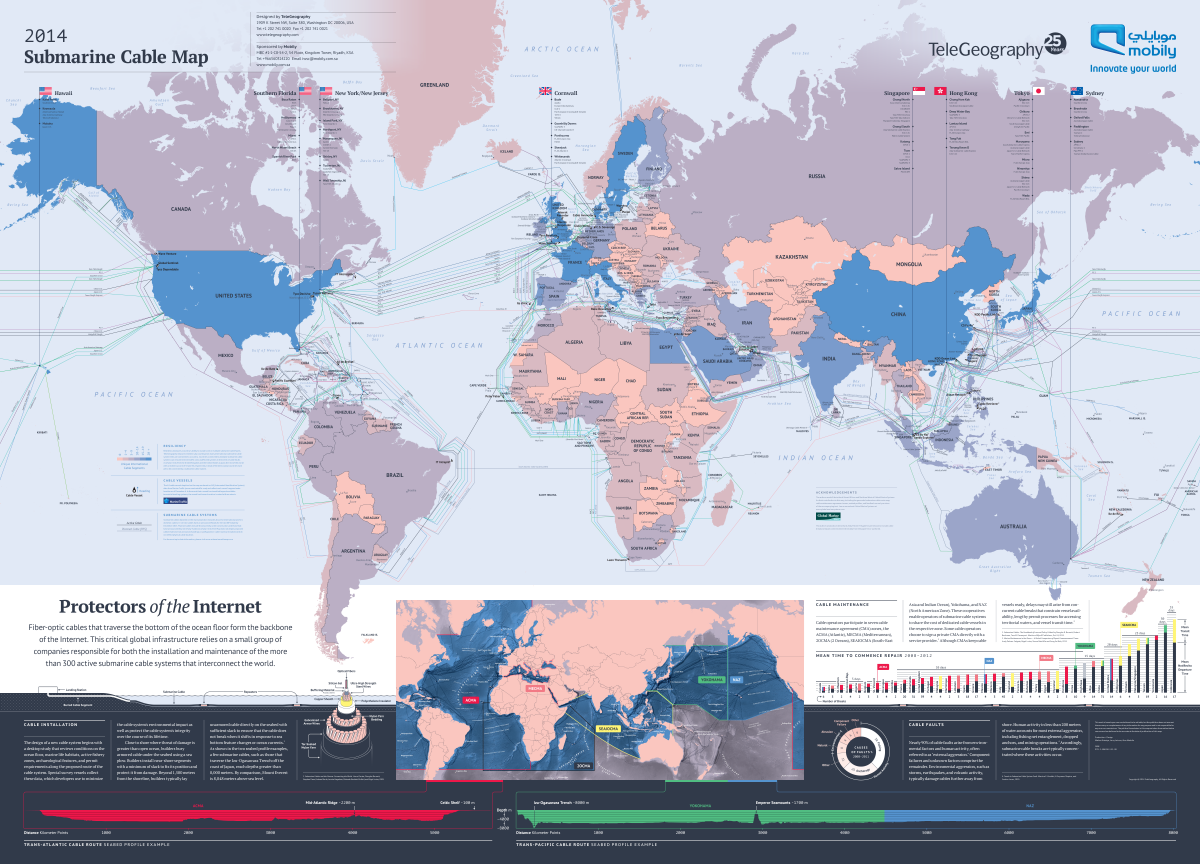


 Техника – это способ справиться с заданием, и у нас, разработчиков и дизайнеров фронтэнда, этих способов бывает достаточно много. При это, будучи погруженными в рутинную работу, мы порой не всегда замечаем как стремительно меняется окружающая нас сфера. В период с 2002 по 2010 годы сообщество фронтэнд-разработчиков буквально покрывалось язвами избыточного кода и ресурсов, от которых страдали и работа сайтов, и удобство их использования. Чтобы с этим справиться, мы придумали уйму хаков, трюков и уловок под кодовым названием «техника». Мы по-прежнему продолжаем выполнять поставленные перед нами задания, просто используем не самые эффективные способы.
Техника – это способ справиться с заданием, и у нас, разработчиков и дизайнеров фронтэнда, этих способов бывает достаточно много. При это, будучи погруженными в рутинную работу, мы порой не всегда замечаем как стремительно меняется окружающая нас сфера. В период с 2002 по 2010 годы сообщество фронтэнд-разработчиков буквально покрывалось язвами избыточного кода и ресурсов, от которых страдали и работа сайтов, и удобство их использования. Чтобы с этим справиться, мы придумали уйму хаков, трюков и уловок под кодовым названием «техника». Мы по-прежнему продолжаем выполнять поставленные перед нами задания, просто используем не самые эффективные способы.

 Сидел я как-то дома, читал
Сидел я как-то дома, читал 
 В последнее время я стал замечать, что большая часть пользователей «семерки» используют стандартную тему оформления, которую разработчики ласково назвали Aero.
В последнее время я стал замечать, что большая часть пользователей «семерки» используют стандартную тему оформления, которую разработчики ласково назвали Aero.











 Переписывал
Переписывал 






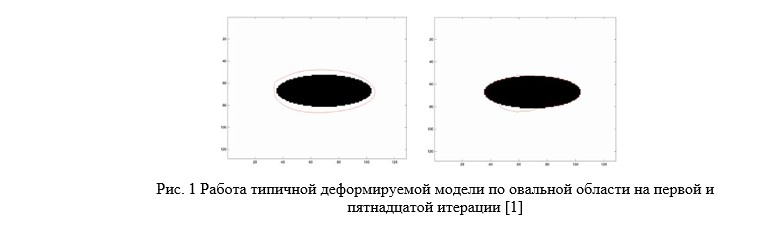




 Ребята из Official.fm Labs задумали совершить настоящую звуковую революцию в вебе: две недели назад они выпустили
Ребята из Official.fm Labs задумали совершить настоящую звуковую революцию в вебе: две недели назад они выпустили 

 Один из сотрудников Google в свободное время разработал новый алгоритм сжатия
Один из сотрудников Google в свободное время разработал новый алгоритм сжатия 

 Привет Хабр! Примерно год назад я представил вашему вниманию первую версию
Привет Хабр! Примерно год назад я представил вашему вниманию первую версию 

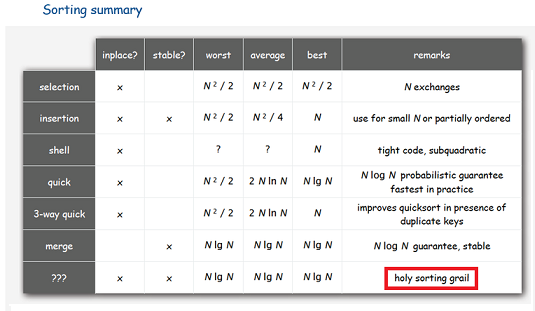


 Привет, друзья.
Привет, друзья.


 My God, it's full of stars!
My God, it's full of stars!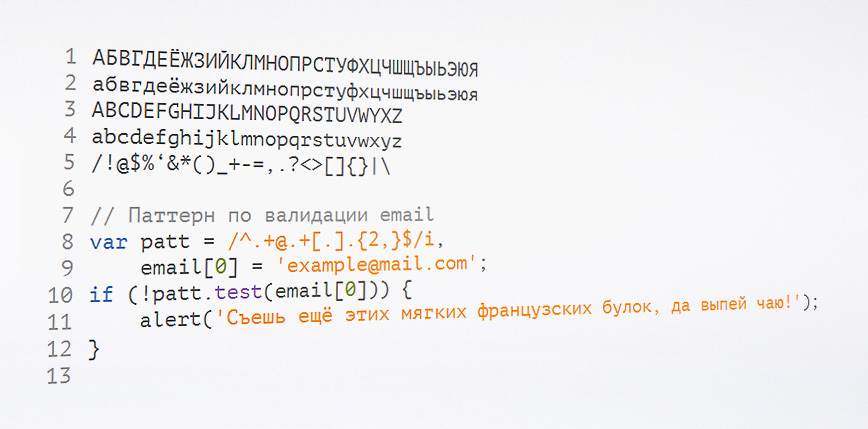

 Привет, Хабр! Мой
Привет, Хабр! Мой  Mozilla анонсировала новый проект
Mozilla анонсировала новый проект 
{kind=link}
{kind=link}
{kind=link}